点亮 ⭐️ Star · 照亮开源之路
https://github.com/apache/incubator-seatunnel
为了更加出色地完成大数据同步的任务,SeaTunnel 自研了 SeaTunnel Engine,并于不久前正式发布。 在此前的文章中, 我们对这个引擎已经有所介绍,今天,我们再从现有引擎在数据集成领域的局限性,以及 SeaTunnel Engine 如何打破这些局限性从而突破性能的角度,详细解析其中的原理。 Apache SeaTunnel是一个非常易于使用的超高性能分布式数据集成平台,支持海量数据的实时同步,致力于解决在海量数据同步过程中可能遇到的问题,如数据丢失和重复、任务积累与延迟、低吞吐量等。 SeaTunnel 原名 Waterdrop,于 2017 年在 GitHub 上开源。 2021 年 10 月 Waterdrop 社区加入Apache孵化器,改名为 SeaTunnel。
stars
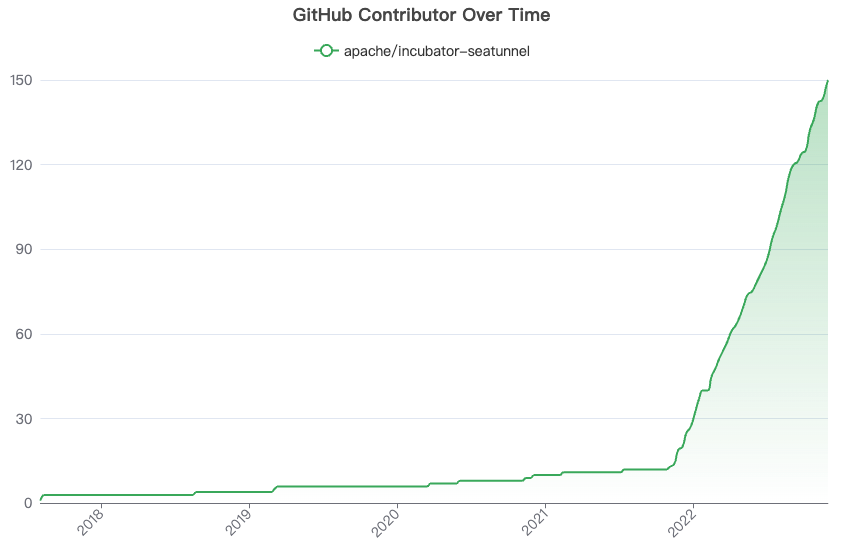
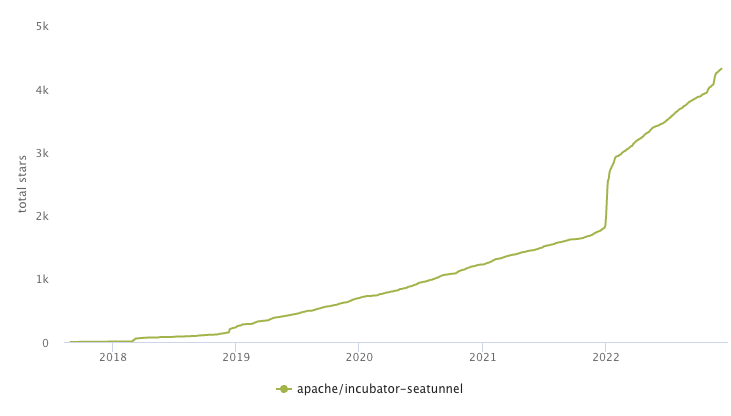
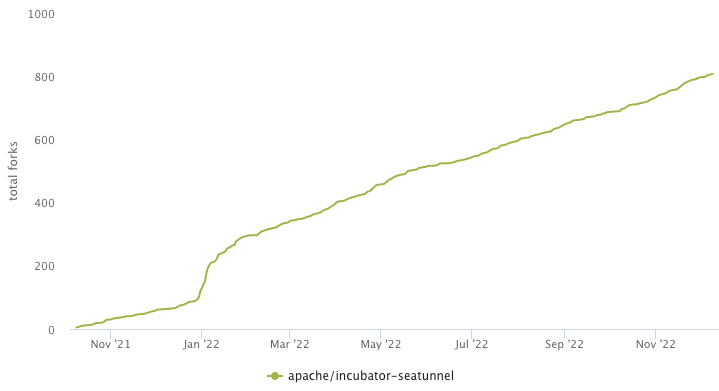
forks 当SeaTunnel进入Apache孵化器后,SeaTunnel社区迎来了高速增长。 截至目前,SeaTunnel社区一共有 150+ 位贡献者参与,获得 4.3k Star,被 fork 800+ 次。 现有的引擎在数据集成领域下存在着许多痛点,我们主要从三个方向考虑:
Global Failover
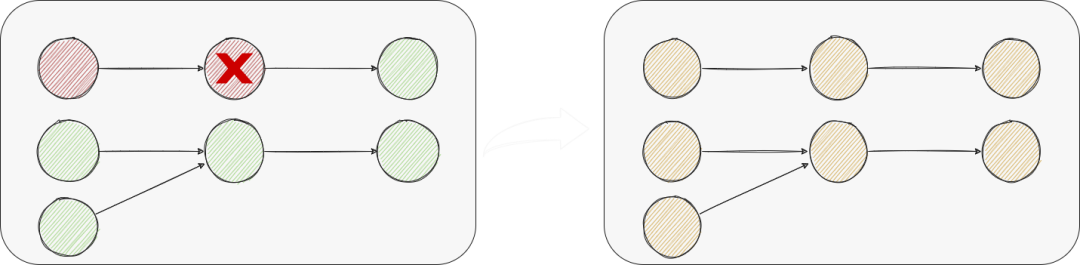
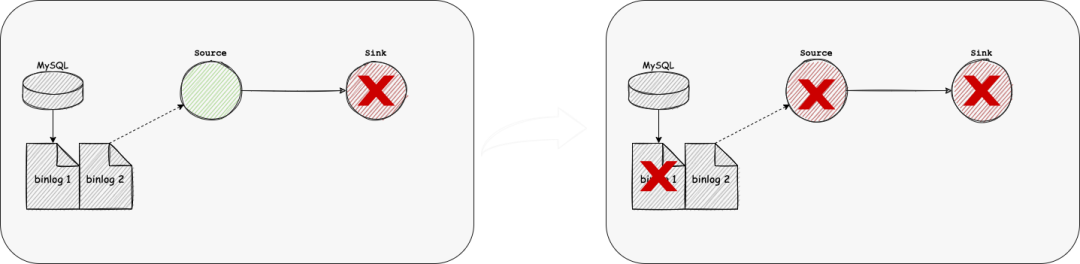
global-failover 对于分布式流处理系统而言,高吞吐、低延迟往往是最主要的需求。与此同时,容错在分布式系统中也很重要,对于正确性要求较高的场景,exactly once的实现往往也非常重要。 在分布式流处理系统中,由于各个节点的算力、网络、负载等情况各有不同,每个节点的状态直接合并不能得到一个真正的全局状态。为了得到一致性的结果,分布式处理系统需要对节点的失败要有弹性,即失败时可以恢复到一致性的结果。 Spark 的 Structured Streaming 虽然在官方博客中披露使用的 Chandy-Lamport 算法来做 Failover 处理,但是并没有更细节的披露。 Flink基于以上算法实现了Checkpoint作为容错机制,并发表了相关论文:Lightweight Asynchronous Snapshots for Distributed Dataflows(https://arxiv.org/abs/1506.08603) 在目前的工业实现中,当作业出错后需要作业DAG的所有节点进行failover,整个过程持续的时间会比较长,会导致上游累积很多数据。
前面的问题只是恢复时间长,业务上可能会接受一定时间的数据延迟。 更差的情况下是单个Sink节点长时间不可恢复,而Source的数据保存时间有限,比如MySQL、Oracle的日志数据,这将导致数据的丢失。 Single table Configuration
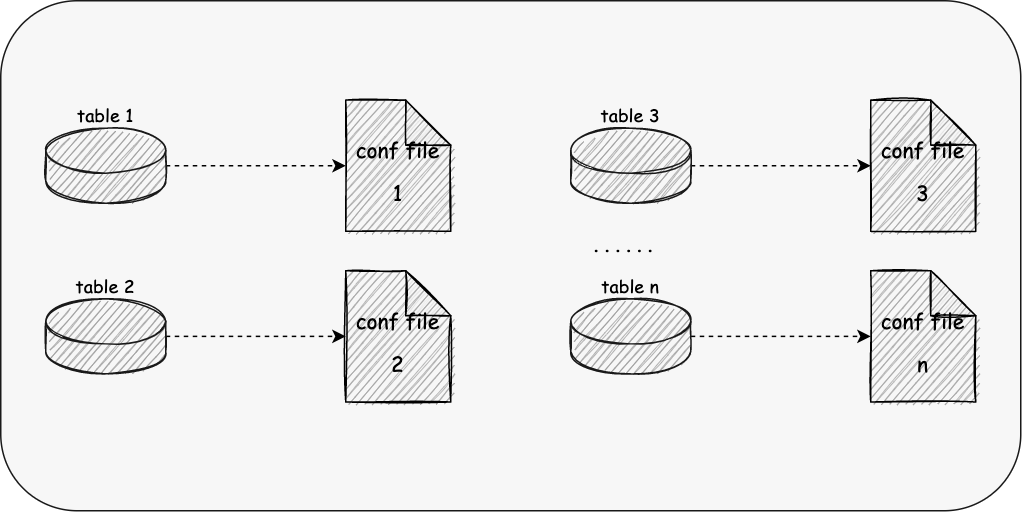
single-table 前面的例子都是少量的表,而真实的业务情况是我们需要同步上千上万张表,它同时可能是分库分表的; 现状是我们需要对每个表进行配置,大量的表同步需要花费用户大量的时间,同时容易出现字段映射错误等问题,难以维护; 不支持Schema Evolution
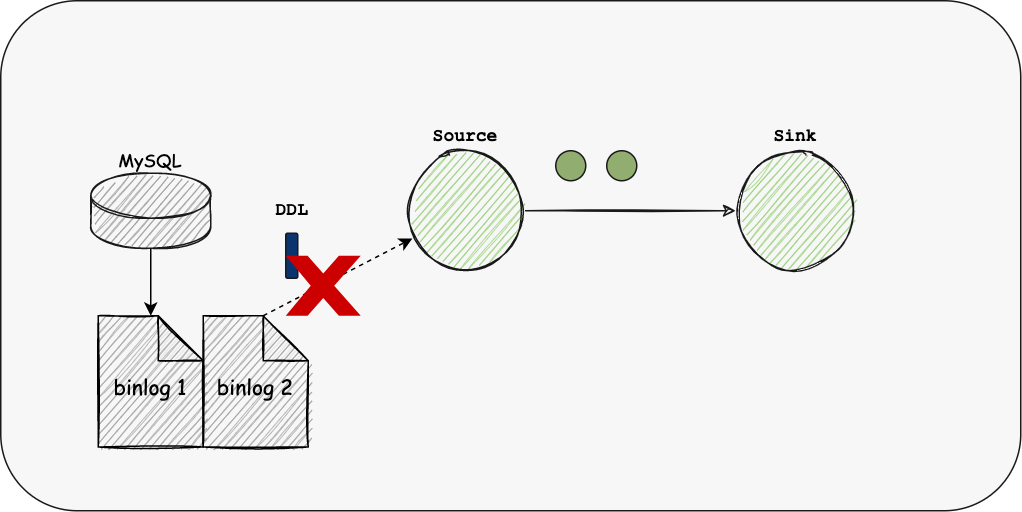
Not-support-ddl 根据fivetran的调研报告,60%的公司Schema每个月都会产生变化,30%每周都会变化; 而现有的引擎均不支持Schema Evolution,在每次变更Schema后,都需要用户对整个链路进行重新配置,使得作业的维护十分繁琐。 数据库链接占用多
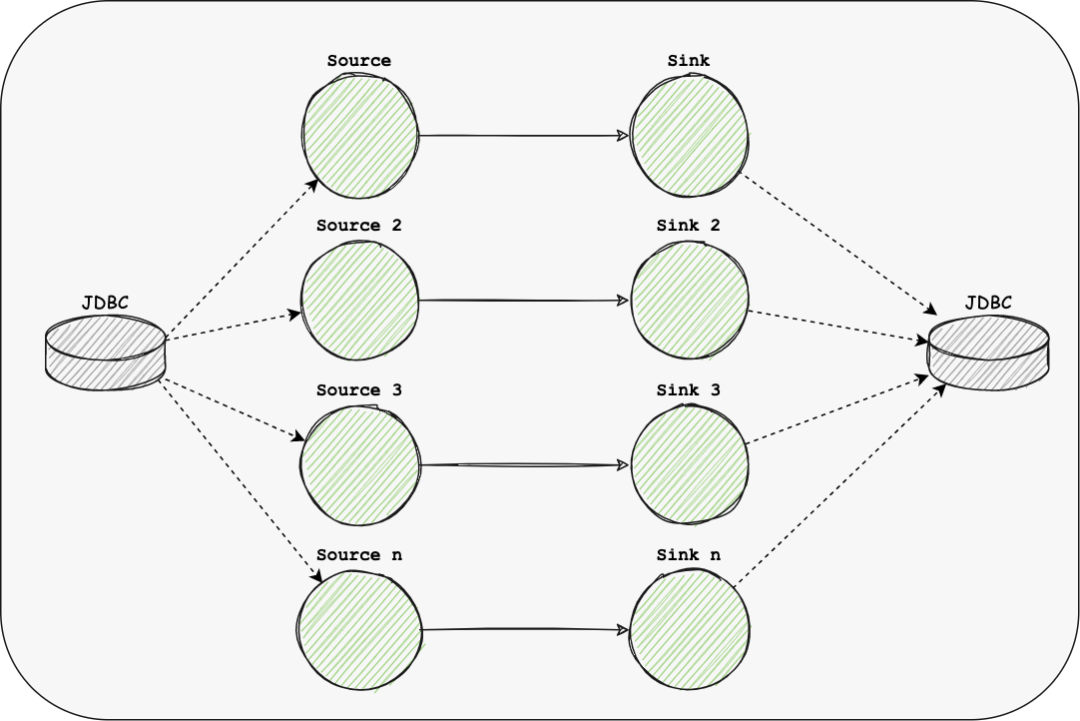
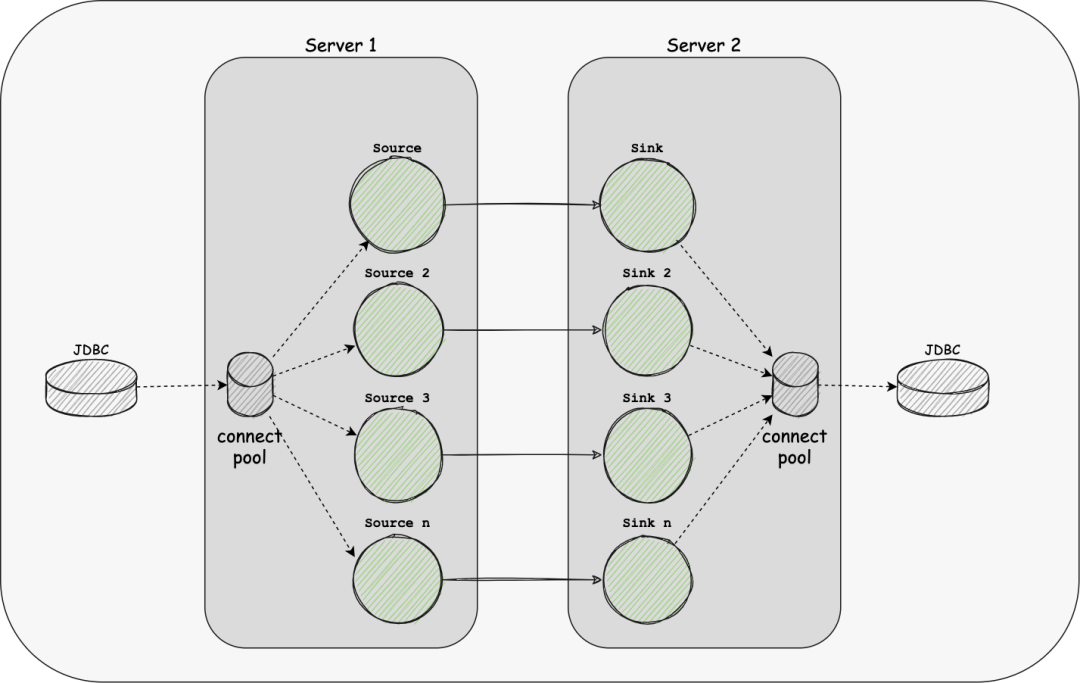
more-link 如果我们的Source或Sink是JDBC类型时,由于现有引擎只支持每个表持有一个或多个链接,当同步的表较多时会占用较多的链接资源,给数据库服务器带来很大的压力; 算子压力不可控
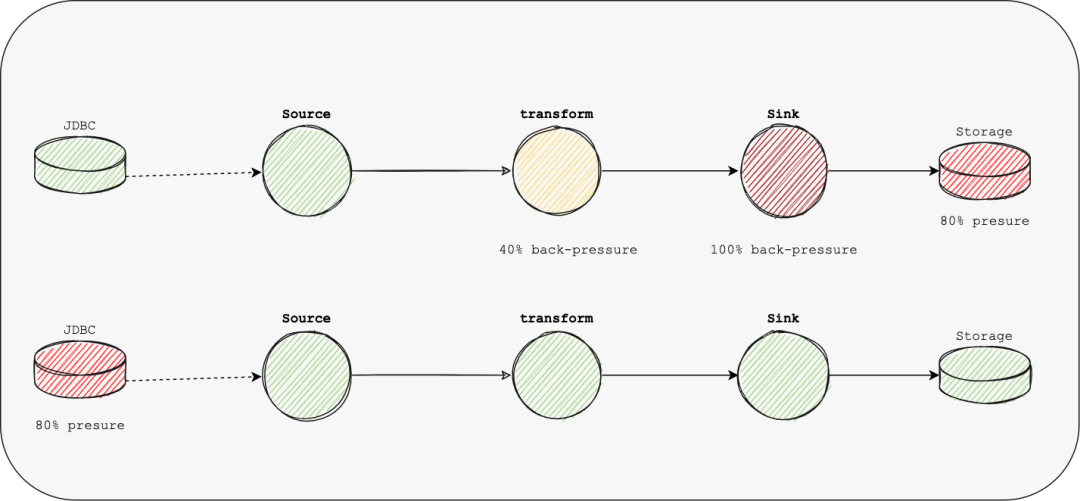
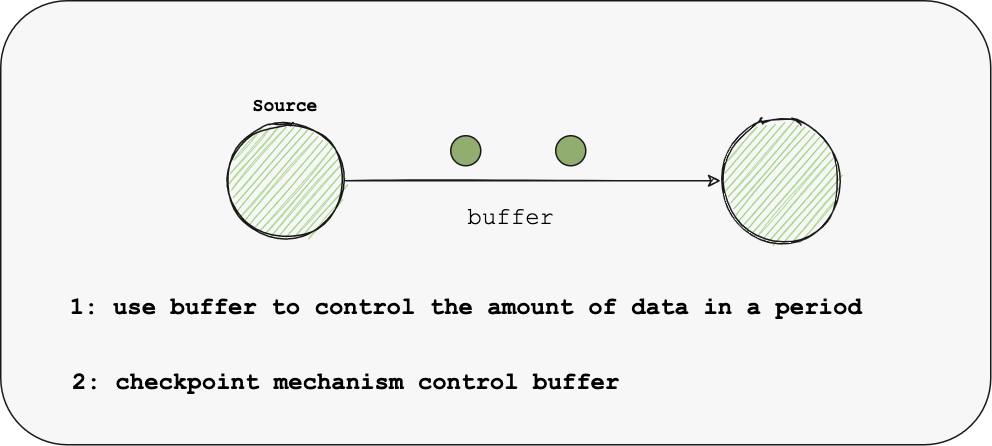
pressure 在现有引擎中,会使用buffer等控制算子的压力,也就是反压机制;由于反压是一级一级传递的,这会存在压力延迟,同时会使得数据的处理不够平滑,增大了GC时间,容错完成时间等; 另一个场景是Source与Sink都没有达到最大压力,但是用户仍然需要控制同步的速率,以防止对源数据库或目标数据库产生太大影响,这无法通过反压机制来控制; Apache SeaTunnel Engine的架构目标
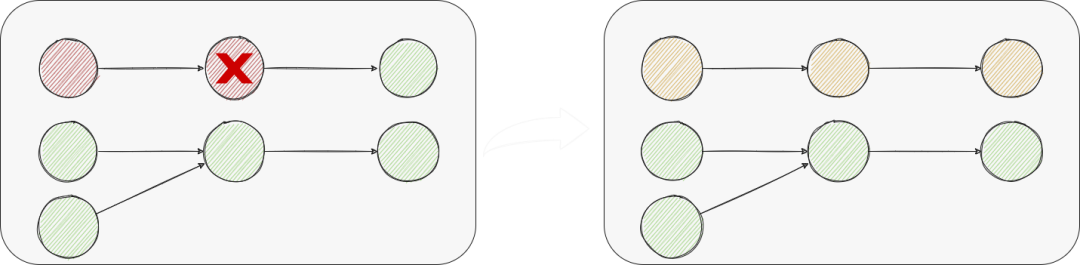
pipeline-failover 在数据集成场景中,存在一个Job同步上百张的可能,一个节点/一张表的失败而导致所有表失败这样的代价太大。 我们期望没有相关性的Job Task不会在容错时相互影响,所以我们将一个有上下游关系的vertex集合称为Pipeline,一个Job可以由一个或多个pipeline组成。 现在如果pipeline出现异常,我们仍然需要pipeline所有vertex进行failover;那么可不可以只恢复部分vertex呢?
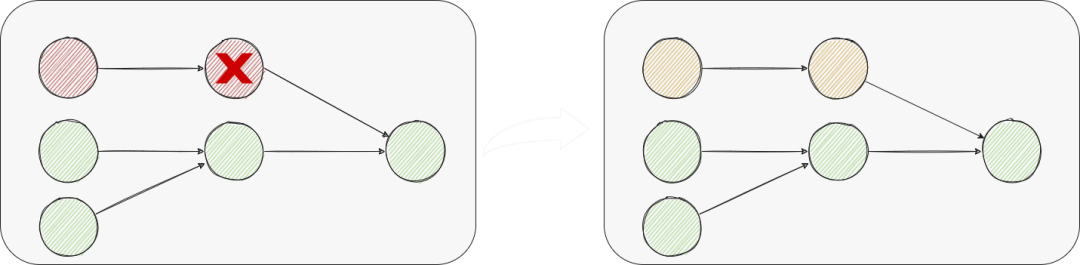
regional-failover 比如Source出错,Sink不重启,单Source多Sink的情况,单个Sink出错,只恢复出错的Sink与Source;即只恢复出错的节点以及其上游节点。 显然,无状态vertex可以不重启,而由于SeaTunnel是数据集成框架,我们不存在Agg、Count等聚合状态vertex,所以只用考虑Sink; Sink不支持幂等 & 2PC;不重启和重启都会导致同样的数据重复,只能由Sink解决该问题,可以不重启; Sink支持幂等,不支持2PC:由于是幂等写入,所以Source每次是否读取数据不一致无所谓,可以不重启了; 如果Source支持数据一致性,如果不执行abort,通过channel数据ID自动忽略已处理的老数据,同时会面临事务会话时间可能超时的问题; 如果Source不支持数据一致性,对Sink执行abort放弃上一次的数据,这与重启的效果一样但不需要重新建立链接等初始化操作; 我们以pipeline为最小粒度进行容错管理,采用Chandy-Lamport算法实现分布式作业的容错;
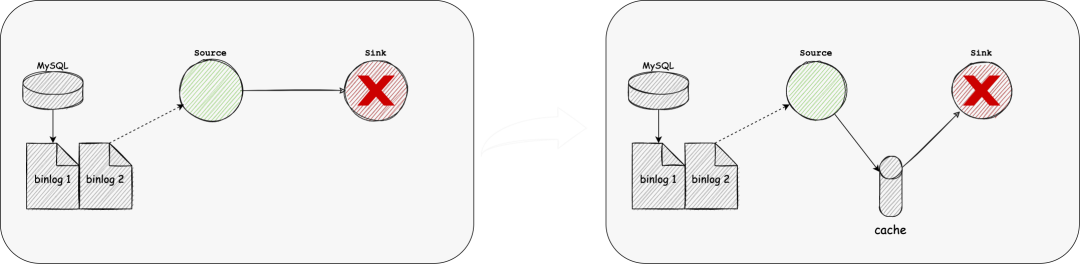
data cache 对于sink故障,无法写入数据时, 一个可行的解决办法是同时做两份工作。 一个作 业使用CDC源连接器读取数据库日志,然后使用Kafka Sink连接器将数据写入Kafka。 另一个作业使用Kafka源连接器从Kafka读取数据,然后使用目标接收器连接器将数据写入目标。 这种解决方案需要用户对底层技术有深入的了解,而且两项工作都会增加操作和维护的难度。 因为每个作业都需要JobMaster,所以它需要更多的资源。 理想情况下,用户只知道他们将从源读取数据并将数据写入接收器,同时,在这个过程中,数据可以被缓存,以防接收器出现故障。同步引擎需要自动将缓存操作添加到执行计划中,并确保在sink故障的情况下源端仍能正常工作。在这个过程中,引擎需要保证写入缓存和从缓存中读取的数据都是事务性的,这样可以保证数据的一致性。
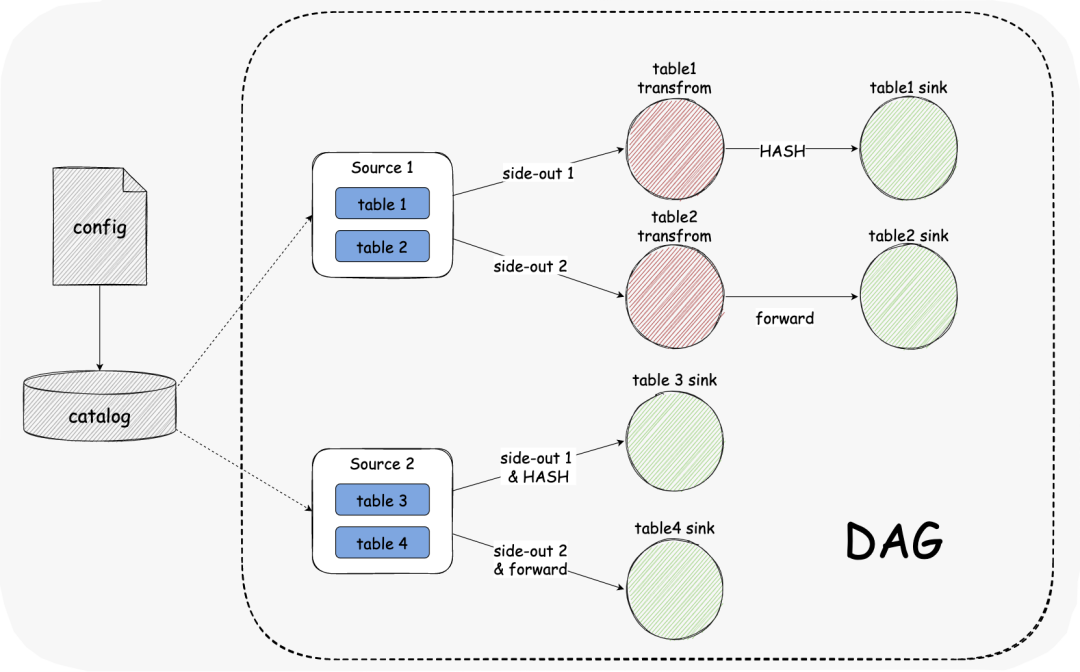
mutil-table-dag 对于大量的表同步,我们期望单个Source可以支持读取多个结构表,然后使用侧流输出与单个表流保持一致。 这么做的好处是可以减少数据源的链接占用,提高线程资源的使用率; 同时在SeaTunnel Engine中会将这多个表视为一个pipeline,会使得容错的粒度变大;这其中存在取舍,由用户自行选择一个pipeline能通过几张表;
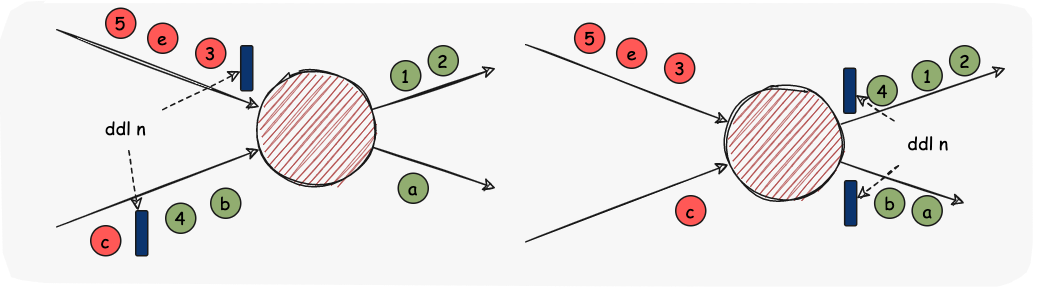
ddl Schema Evolution是一种允许用户轻松更改表的当前模式以适应随着时间变化的数据的特性。最常见的情况是,在执行追加或覆盖操作时使用它,以自动调整模式以包含一个或多个新列。 实时数据仓库场景需要该特性。目前flink和spark引擎不支持该特性。 在SeaTunnel Engine中,我们将采用Chandy-Lamport算法发送DDL事件,使其在DAG图中流转并变更每个算子的结构,进而同步到Sink端中;
shared-resource 由Multi-table特性可以减少一部分Source和Sink的链接资源的使用; 同时我们在SeaTunnel Engine中实现了动态线程资源共享,减少了引擎对服务器的资源使用;
speed-control 为了覆盖反压机制无法解决的场景,我们将优化Buffer与Checkpoint机制: 使引擎可以通过Checkpoint机制,在Checkpoint达到最大并行数量并执行了一个间隔时间后,锁住buffer,禁止Source的数据写入,达到主动背压的能力,避免反压延迟或无法传递到Source的问题; 作为一个Apache 孵化项目,Apache SeaTunnel 社区迅速发展,在接下来的社区规划中,主要有四个方向: 支持更多数据集成场景 (SeaTunnel Engine) 用于解决整库同步、表结构变更同步、任务失败影响粒度大等现有引擎不能解决的痛点; 对engine感兴趣的同学可以关注该Umbrella:https://github.com/apache/incubator-seatunnel/issues/2272 扩大与完善 Connector & Catalog 生态 支持更多 Connector & Catalog,如TiDB、Doris、Stripe等,并完善现有的连接器,提高其可用性与性能等; 对连接器感兴趣的同学可以关注该Umbrella:https://github.com/apache/incubator-seatunnel/issues/1946 如Spark 3.x, Flink 1.14.x等 对支持Spark 3.3 感兴趣的同学可以关注该PR:https://github.com/apache/incubator-seatunnel/pull/2574 提供Web界面以DAG/SQL等方式使操作更简单,更加直观的展示Catalog、Connector、Job等; 对Web 感兴趣的同学可以关注我们的Web子项目:https://github.com/apache/incubator-seatunnel-web
Apache SeaTunnel(Incubating) 是一个分布式、高性能、易扩展、用于海量数据(离线&实时)同步和转化的数据集成平台https://github.com/apache/incubator-seatunnel https://seatunnel.apache.org/ https://cwiki.apache.org/confluence/display/INCUBATOR/SeaTunnelPro Apache SeaTunnel(Incubating) 下载地址: https://seatunnel.apache.org/download 我们相信,在「Community Over Code」 (社区大于代码)、「Open and Cooperation」 (开放协作)、「Meritocracy」 (精英管理)、以及「多样性与共识决策」 等 The Apache Way 的指引下,我们将迎来更加多元化和包容的社区生态,共建开源精神带来的技术进步! 我们诚邀各位有志于让本土开源立足全球的伙伴加入 SeaTunnel 贡献者大家庭,一起共建开源! https://github.com/apache/incubator-seatunnel/issues https://github.com/apache/incubator-seatunnel/pulls dev-subscribe@seatunnel.apache.org https://join.slack.com/t/apacheseatunnel/shared_invite/zt-1cmonqu2q-ljomD6bY1PQ~oOzfbxxXWQ https://twitter.com/ASFSeaTunnel