




引读
因为工作的关系,最近几年我会触到各种国产数据库,唯独对TDengine念念不忘。众多数据库中TiDB一枝独秀,OceanBase出身名门世家,openGauss有华为撑腰,只有TDengine给人感觉有一种草莽出英雄的感觉,TiDB借用了rocksDB的性能,openGauss是基于postgreSQL9.2.4开发,即使OceanBase也是基于内部应用需求开始打造的。只有TDengine 不依赖任何开源或第三方软件,而且它不是一款通用型的数据库,剑走偏锋,它有自己独特的社会应用场景,主要为工业网服务。
笔者把对TDengine的定义和理解,TDengine能做什么?它与其它数据库的区别?同类的产品有哪些?TDengine解决了什么问题? 它的优势与亮点在哪里?下面细细道来,希望对TDengine有兴趣的小伙伴有所领悟。
TDengine与其它数据库的区别
数据库完成出色的的读写,最核心的能力的是索引,一般数据库产品都具备正向索引能力。所谓正向索引就是通过文档记录里面的标识符为关键字,通过关键标识符不需要进行全盘扫描。B树索引、哈希索引、位图索引有区别,但是大方向都属于正向索引。
除了正向索引,还有反向索引【也称倒排索引】,反向索引主要是用于全文检索的,例如ElasticSearch,大多数据库都是正向索引。TDengines也是使用正向索引,它的特别之处标识符肯定包含时间戳,再加上一个维度指标数据,构对一个对数据值明确的描述,某个时间某个指标对象的数据值是多少多少。
从数据组织的存储引擎来看,数据库底层可以分为B树机制、LSM机制,两种机制没有谁最好,各有各的优点和缺点。
B树最大好处,在于它对数据持续高涨读性能的处理,即使数据量级增大,它的读也没有放大。 奥秘在于对数据进行终极持久存储的时候,B树是以有序有规律的数据结构保存在硬盘上的。这样随着数据越来越大,它依然保持有序有规律的特性,面以成千上万的读操作,都可以遵循条件运行,减少或避免读放大的行为。
与B树机制截然相反,LSM机制则是减少避免了写放大。
LSM机制充分利用了内存,在内存里面开辟了一个空间,写数据优先往内存里面放,写进去直接返回用户成功,而不是像B树那样写一个, 我要找出谁比我大谁比我小,只要内存有够,我就直接往内存里面填就好。 当内存达到一定的阈值,将内存中的数据以批量、顺序的方式一次写入硬盘上,内存则重置清零再服务新的写要求。
传统数据库MySQL、Oracle使用的是B树机制,而TiDB、OceanBae使用的是优化后的LSM机制,而TDengine使用的是B树 + LSM机制的方式,B树存储的是元数据【主要是时间戳+指标数据】,LSM机制存储的是具体的数据,元数据以有序表结构方式进行存储,而具体数据则是追加的方式 写入,这样即避免了读话大和写放大。
业界为OLTP产品为了提升并发控制的性能,必定会有写时复制或者MVCC的功能选项,写时复制与MVCC虽然保障了数据的一致性,但是带来更多的IO负担。TDengine不需要对数据进行修改,所以不需要考虑数据一致性的问题,数据是以有序的规律并追加的形式写进去的,因为只有读和写,所以也不需要锁保护,抛掉一些无用的包袱,可以集中优化其它地方,例如列式表。
业界通用数据库针对各种业务都会有行式表、列式表甚至完全的内存库,对于具体的数据存储TDengine使用完全列式存储在硬盘,而维度指标则行式保存在内存中。因为TDengine面对的是机器的数据,机器24小时工作精确到每个毫秒都在产生数据,为了存储更多的数据,所以TDengine用上行列并存、用途分离的方式。
数据库里面的每一行的文档记录都是非常重要的,即使这行记录信息无关交易,只是一个用户基本信息,它的价值密度也十分高。时间序列数据库不同,单行文档记录价值密度低。因为1秒可以产生1万条记录,必须要把数据聚合汇总起来才能体现数据的价值。快速并有效聚合普通数据使之变成价值密度高的数据,这个也是时间序列数据库区别于其它数据库的一个重要的特征。
TDengine目前提供了三个版本的产品:社区版,企业版以及云版本, 满足市场的需求和个人开发者的需求。
TDengine的竞争对手
技术上区分定位,TDengine是专注时间序列领域的一个分布式的海量数据分析平台。 TDengine的竞争对手可以分为直接竞争对手和间接竞争对手,间接竞争对手有TiDB、OceanBase、GaussDB以及国外Oracle、MySQL等等,虽然它们在综合技术维度上与TDengine没有对标,但是分析上只要是使用时间戳,与时间序列有关系,这里就有TDengine的用武之地。
与TDengine构成直接竞争对手有Druid、opentsDB、influxDB,他们都是时间序列分析的前辈。
**Druid是一个分布式系统,采用Lambda架构,充分利用内存,也会把历史数据保存到硬盘上,按一定的时间粒度对数据进行聚合,实时处理和批处理数据解耦分开。**实时处理是面向写多读少的场景,主要是以流方式处理增量数据,批处理是面向读多写少的场景,主要是以批处理方式处理离线数据。
Druid依赖hadoop,集群中采用share nothing的架构,各个节点都有自己的计算和存储能力,整个系统通过Zookeeper进行协调。为了提高计算性能,会采用近似计算方法包括HyperLoglog、DataSketches的一些基数计算。
OpenTsDB是 一个开源的时序数据库,支持存储 数千亿的数据点,并提供精确的查询,采用JAVA语言编写,通过基于Hbase的存储实现横向扩展,OpenTsDB广泛用于服务器的监控和度量,包括网络和服务器、传感器、IOT、金融数据的实时监控领域。OpenTsDB的设计思路上是利用Hbase的key 去存储一些Tag信息,将同一个小时数据放在一行存储 ,提高 了查询速度。
OpenTsDB通过预先定义好维度Tag等,采用精巧的数据组织形式放在hbase里面,通过HBase的keyRange可以进行快速查询,但是在任意维度的组织 查询下,OpenTsDB的效率会降低。
influxDB是非常流行的时序数据库,采用go语言开发,社区非常活跃,技术特点支持任意数量的列,去模式化,使用方便、强大的查询语言,集成 了数据采集、存储和可视化存储。支持高效存储,使用高压缩比的算法等,采用TIME SERIES MERGE TREE的内部存储引擎,支持与SQL类似的语言。
时间序列的业务背景,在OLAP场景中一般会进行预聚合来减少数据量,影响预聚合主要因素如下,
- 维度指标的个数
- 维度指标的基数
- 维度指标组合程度
- 时间维度指标的粗粒度和细粒度
为了高效的预聚合,TDengine的秘诀是超级表,Druid会提前定义预计算,influxDB也有自己的连续查询方法,只有hbase 使用时才进行拼接,所以涉及不同的维度指标查询,hbase会慢一些。
| 特性 | TDengine | Druid | OpentsDB | influxDB |
|---|---|---|---|---|
| 使用场景 | 时间序列实时分析 | 时间序列实时分析 | 时间序列实时分析 | 时间序列实时分析 |
| 开发语言 | C | Java | Java | GO |
| 接口协议 | OLAP/JDBC | JSON | JSON | OLAP/JDBC |
| 发布时间 | 2018 | 2011 | 2010 | 2013 |
| 主要领域 | 工业领域 | 广告领域 | 运维领域 | 资源监控 |
| 产品生态 | 独立自治 | hadoop生态圈 | hadoop生态圈 | 独立自治 |
| 核心技术 | 超级表 | 预计算、实时聚合 | 使用时进行聚合 | 提前预计算 |
| 部署 | 一键部署、无依赖 | 需要搭建hadoop,配置JAVA环境 | 需要搭建hbase,创建tsd数据、配置JAVA环境 | 部署简单、无依赖 |
| 集群 | 社区版开源仅支持单机 | 集群方案成熟 | 集群方案成熟 | 开源仅支持单机 |
| 资源占用 | 资源占用少 | 资源占用多 | 资源占用多 | 资源占用少 |
| 存储引擎 | 自己独立研发 | 基于lambda架构的批处理能力和流处理能力 | 基于hbase的存储 | 自己独立研发 |
| 存储特点 | 单点写入,连续存储,跨维度指标融合的超级表 | 支持跨标签聚合,热数据保存内存中,冷数据保存在硬盘中 | 无法有效压缩,聚合能力弱 | 同一数据源的标签不再冗余存储,独立压缩 |
| 性能 | 查询更快,数据汇聚分析 | 查询更快,数据汇聚分析较快 | 数据写入和存储较快,但查询和分析能力略有不足 | 查询更快,数据汇聚分析较快 |
| 开发 | 架构简单,类SQL易开发 | API较为丰富 | API较为丰富 | 架构简单,类SQL易开发 |
TDengine的应用案例
我对TDengines的认识了解结合笔者的过去项目经验,以2018年为背景,讲述一个工业界坏件故障件预测的故事。
某知名集团,随着公司业务的快速增长、新工厂的不断增加,各种有价值的数据,没有很好的整合、分析与挖掘出它应有的价值。公司已经进入的‘拼’的战略,快速响应与准确预测是大数据所能做的事情,通过整合各系统数据以科学的分析手法,帮助驱动公司业务的发展,使得工厂的制造更能智能化。
当前工厂生产过程中有同一种特殊问题的glass id,glass 的品质由于各种原因是参差不齐的,甚至会有品质异常的glass。这些异常 glass 在检测过程中,是无法检测出异常原因的。如果无法快速定位出异常原因,会造成更多的异常 glass,严重影响生产。
- 通过品质异常的 GLASS,找到产生此异常的相关性因子。如:机台、物料、载具、参数等。
- 异常 GLASS 侦测预警,通过对产生品质异常的因子进行数学建模,预测出偏离正常范围的异常玻璃,提前预警。
- 分析 GLASS 的特征值与特征值之间的关联关系,并建立预测模型,提前预测出GLASS 的特征值。
- 分析GLASS 相关的电压、电阻、电流、温度、湿度影响。
很明显这是数据挖掘的项目,以上glass在生产过程中的环境信息,检测机台资料,量测机台资料,制程参数信息,以及FDC,OEE系统的数据找出产生这种问题的原因。第一步是数据收集整合,第二步数据探索,第三步是模型调校,找出可能性、影响最大的因素的特征因素,第四步是投入生产验证,,通过spark ml提供预测动力。
当时的技术栈用的是CDH,首先通过kafka采集的数据, spark对接kafka进行初步计算去噪并汇总到hadoop里面,以parquet的格式保存,有需要进一步的加工,通过impala进行一步的加工,每天挂起N个任务,不停的调度计算。
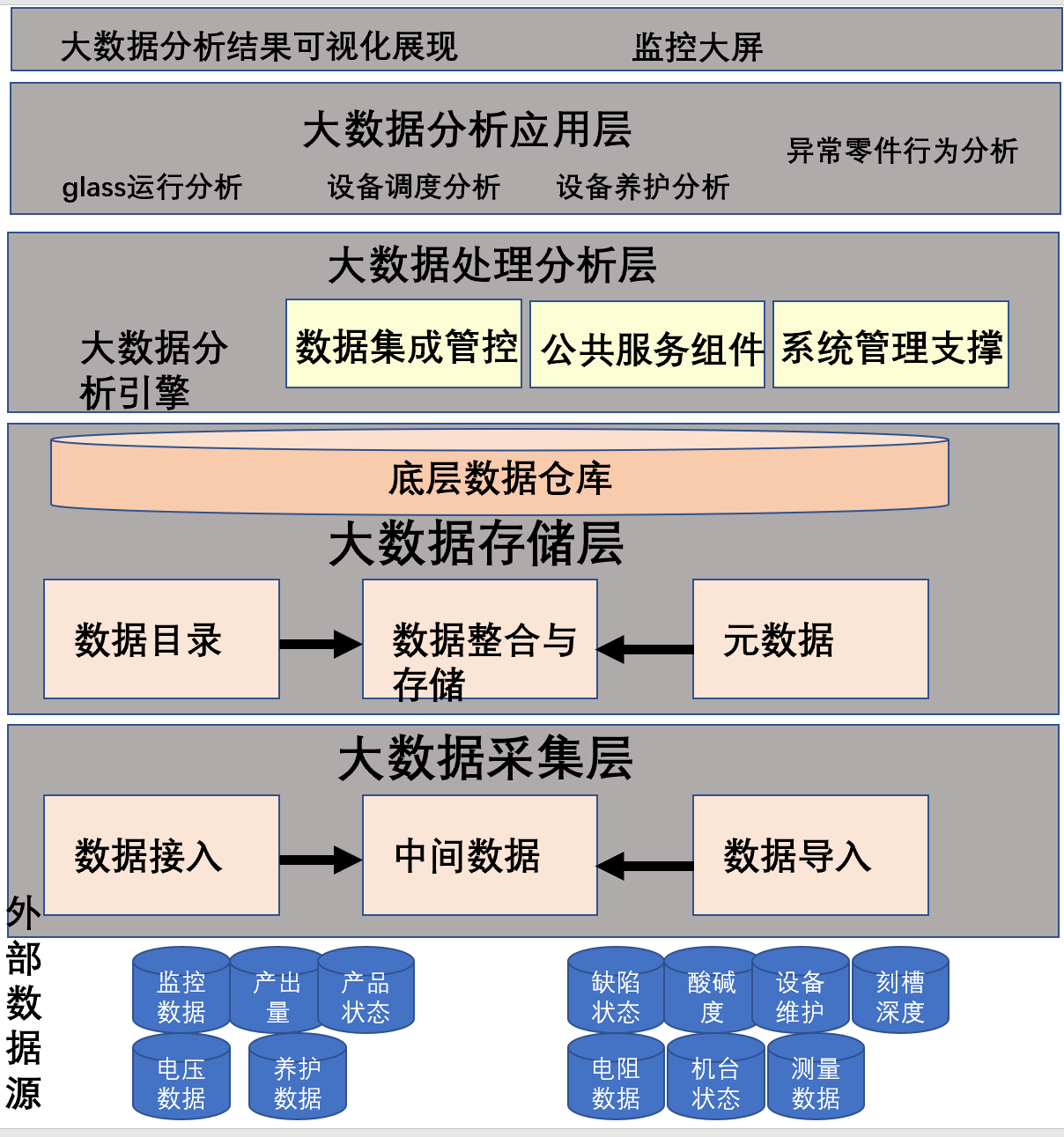
当时坏件故障件预测项目有以下痛点,主要是及时性、有效性、准确性的问题,无法做到实时数据分析,但是CDH hadoop还能做些事,继续用着。
-
难以满足用户需求,某些机器数据的聚合计算需要第二天才能出结果,甚至更多的时间才能出来。
-
经济成本的费用较高,CPU、磁盘、网络都在一个高段的使用状态,针对越来越多的数据需要投入新机器。
-
维护成本高,你需要维护hadoop所有的机器,各种hbase、spark、zookeeper、hdfs之类,不但对工程师要求高,而且工作量大。
-
低质量数据,因为数据流程或者错误的逻辑整合,导致机器传感器聚合后导致数据模型无法正常使用。
-
无法做到实时监测,机器数据作为宝贵的自变量因素无法及时传输并进行计算,自然会影响因变量。
笔者经历了这个项目,知道这个坏件故障预测与时间序列有紧密的关系。**时至今日,时间序列分析也是重要的数据分析技术。尤其面对季节性、周期性变化数据时,传统的回归拟合技术难以奏效,这时候就需要复杂的时间序列模型,以时间为特征作为抓手点。**这样你不太懂业务的前提下,也可以进行数据挖掘的工作。
这个项目与Tdengine有什么关系? 这个项目没有用上TDengine,后来集团搭建了一个hadop集群试点,这次居然用了HDP,理由很简单,因为HDP默认搭载了时间序列数据库Druid。
当时技术负责人认为坏件故障预测模型的 数据库基座应该是 时间序列数据库,而不是hadoop不停的数据采集、数据转换以及各种批计算,通过时间序列数据库可以不但可以实时计算,而且输出的数据质量高。选择哪个时间序列数据库?考虑平稳过渡替换以及学习成本综合因素他们选择了Druid。
当时2017年,TDengine还没有面世,如果放到今天TDengine必定是考虑首选。
TDengine的优势相对Druid多了去,首先Druid不是一个经过开源版本1.00正式发布的软件,虽然发展多年,直至HDP与CDH两家公司融合,HDP搭配的Druid也不是1.00版。其次Druid依赖Hadoop,动辄就使用大量的资源以及各种复杂的hadoop组件,最后Druid只提供json的方式,对传统的DBA使用十分不友好。
TDengine有一个我认为很秀的功能,就是它的超级表的跨指标维度建模思想,目前它仅用于 自由组合维度指标,拼接不同的时间粒度进行聚合。在我看来,将来应用于时间序列机器学习模型也是它的一个亮点。在数据建模方面,针对工厂的设施、设备、机床、机房、车间、测台等晦涩,必须要做高效准确的定义。我们进行项目规划建设的时候,都会做大量的数据治理工作,但是具体实施工作的时候,还是要使用这些传统工具和技术。TDengine可以有效汇集各种机器数据源,并且能够高质量的提炼,这个是过去没有的。
我对TDengien的未来展望
一个老人和一个年青人站在一起,有句话如此说姜是老的辣,同时也有另外一句话,长江后浪推前浪,一代新人胜旧人,IT世界千变万化, TDengine这几年的冒起太迅速。最近TDengine推出3.0版本。新版优化了流计算功能,而且还重新设计了计算引擎,优化工程师 对 SQL 的使用,另外 增加了taosX,利用自己的数据订阅功能来解决增量备份、异地容灾。我对TDengine未来的发展方向路径,希望它增加库内机器学习函数,增加ARIMA模型、MA模型等时间相关功能,TDengine的未来是一个智能学习时间序列数据库,为工业4. 0不仅是提速,更是赋能。
