




ClickHouse 核心特性
ClickHouse 为什么会有如此高的性能,获得如此快速的发展速度?下面我们来从 ClickHouse 的核心特性角度来进一步介绍。
1. 列存储
ClickHouse 采用列存储,这对于分析型请求非常高效。
一个典型且真实的情况是:如果我们需要分析的数据有 50 列,而每次分析仅读取其中的 5 列,那么通过列存储,我们仅需读取必要的列数据。相比于普通行存,可减少 10 倍左右的读取、解压、处理等开销,对性能会有质的影响。这是分析场景下,列存储数据库相比行存储数据库的重要优势。
行存储:从存储系统读取所有满足条件的行数据,然后在内存中过滤出需要的字段,速度较慢。
列存储:仅从存储系统中读取必要的列数据,无用列不读取,速度非常快。
2. 向量化执行
在支持列存的基础上,ClickHouse 实现了一套面向向量化处理的计算引擎,大量的处理操作都是向量化执行的。
相比于传统火山模型中的逐行处理模式,向量化执行引擎采用批量处理模式,可以大幅减少函数调用开销,降低指令、数据的 Cache Miss,提升 CPU 利用效率。并且 ClickHouse 可利用 SIMD 指令进一步加速执行效率。这部分是 ClickHouse 优于大量同类 OLAP 产品的重要因素。
以商品订单数据为例,查询某个订单总价格的处理过程,由传统的按行遍历处理的过程,转换为按 Block 处理的过程。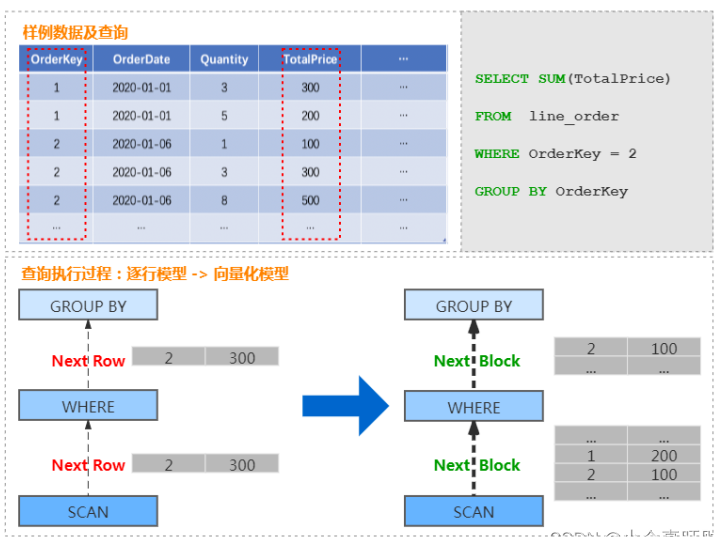
3. 编码压缩
由于 ClickHouse 采用列存储,相同列的数据连续存储,且底层数据在存储时是经过排序的,这样数据的局部规律性非常强,有利于获得更高的数据压缩比。
此外,ClickHouse 除了支持 LZ4、ZSTD 等通用压缩算法外,还支持 Delta、DoubleDelta、Gorilla 等专用编码算法,用于进一步提高数据压缩比。其中 DoubleDelta、Gorilla 是 Facebook 专为时间序数据而设计的编码算法,理论上在列存储环境下,可接近专用时序存储的压缩比,详细可参考 Gorilla 论文。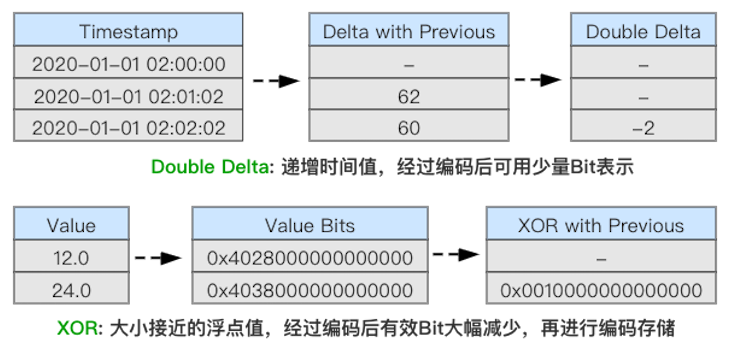
ClickHouse 通常可以达到 10:1 的压缩比,大幅降低存储成本。同时,超高的压缩比又可以降低存储读取开销、提升系统缓存能力,从而提高查询性能。
4. 多索引
列存用于裁剪不必要的字段读取,而索引则用于裁剪不必要的记录读取。ClickHouse 支持丰富的索引,从而在查询时尽可能的裁剪不必要的记录读取,提高查询性能。
ClickHouse 中最基础的索引是主键索引。前面我们在物理存储模型中介绍,ClickHouse 的底层数据按建表时指定的 ORDER BY 列进行排序,并按 index_granularity 参数切分成数据块,然后抽取每个数据块的第一行形成一份稀疏的排序索引。用户在查询时,如果查询条件包含主键列,则可以基于稀疏索引进行快速的裁剪。
这里通过下面的样例数据及对应的主键索引进行说明:

样例中的主键列为 CounterID、Date,这里按每 7 个值作为一个数据块,抽取生成了主键索引 Marks 部分。
当用户查询 CounterID equal ‘h’ 的数据时,根据索引信息,只需要读取 Mark number 为 6 和 7 的两个数据块。
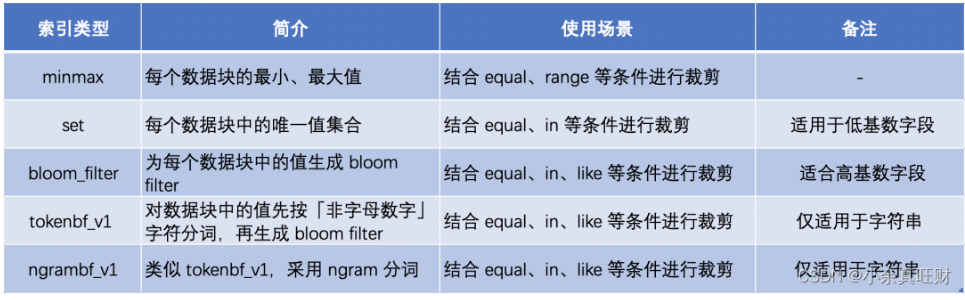
ClickHouse 支持更多其他的索引类型,不同索引用于不同场景下的查询裁剪,具体汇总如下,更详细的介绍参考 ClickHouse 官方文档:
原文链接:https://blog.csdn.net/shan19920501/article/details/125235310
