




什么是 CDP 运营数据库 (COD)
CDP 运营数据库使开发人员能够快速构建面向未来的应用程序,这些应用程序的架构旨在处理数据演变。它通过自动缩放等功能帮助开发人员自动化和简化数据库管理,并与Cloudera Data Platform (CDP) 完全集成。有关更多信息和 COD入门,请参阅 Cloudera Data Platform Operational Database (COD) 入门。
背景
我们将“ Cloudera Operational Database (COD) 中的事务支持”博客分为两部分。
在第一部分中,我们将介绍 COD 中事务支持的概述和用法。
在第二部分中,我们将通过分步示例演示如何在您的 COD 环境中使用事务。查看如何在 COD 中使用事务。
COD 中的事务支持概述
事务是数据库中一系列的一个或多个更改,必须按顺序完成或取消以确保完整性和一致性。
COD 中的事务支持使您能够执行复杂的分布式事务并运行原子跨行和跨表数据库操作。原子数据库操作确保您的数据库操作必须完成或终止。
COD 支持 Apache OMID(数据存储中的优化事务管理)事务框架,该框架允许大数据应用程序在 COD 表上执行 ACID 事务——坚持原子性、一致性、隔离性和持久性的 ACID 属性。OMID 在具有快照隔离保证的 HBase 之上提供无锁事务支持。OMID 使大数据应用程序能够从两全其美中获益:NoSQL 数据存储(如 HBase)提供的可扩展性,以及事务处理系统提供的并发性和原子性。
COD 如何管理事务
当多个事务在不同终端同时发生时,COD 确保为每个事务端到端更新 HBase 表,将事务标记为已完成,或者终止事务并且不更新 HBase 表。COD 使用事务处理服务 OMID 以及 HBase 和 Phoenix 来归档此事务管理。
COD 还管理支持事务所需的相关配置,以便您无需任何额外工作即可在应用程序中使用事务。
图 1:OMID 客户端视图
COD 自动执行管理 Phoenix 事务的所有步骤。这些步骤在附件 1中有所描述。
如何在不同的应用程序中使用事务
您可以在流式应用程序或 OLTP(在线事务处理)应用程序以及面向批处理的 Spark 应用程序中使用 COD 事务。
有关在 COD 上部署事务支持的更多详细信息,请参阅如何在 COD 上使用事务。
以下是您可以使用 COD 事务的不同方式和场景。
1(a):Phoenix胖客户端和瘦客户端(使用SQLLine命令行):
// create transactional table0: jdbc:phoenix:> create table bankaccount(customer_id varchar primary key,name varchar, balance double) transactional=true;No rows affected (2.287 seconds)// Initial data population0: jdbc:phoenix:> upsert into bankaccount values('CU001', 'foo', 100.0);1 row affected (0.017 seconds)0: jdbc:phoenix:> upsert into bankaccount values('CU002', ' baa', 100.0);1 row affected (0.015 seconds)0: jdbc:phoenix:> select * from bankaccount;+-------------+------+---------+| CUSTOMER_ID | NAME | BALANCE |+-------------+------+---------+| CU001 | foo | 100.0 || CU002 | baa | 100.0 |+-------------+------+---------+// Auto commit off0: jdbc:phoenix:> !autocommit offAutocommit status: false// Starts transaction 1 to transfer 50 from CU001 to CU0020: jdbc:phoenix:> upsert into bankaccount(customer_id, balance) select customer_id, balance - 50 from bankaccount where customer_id = 'CU001';1 row affected (0.075 seconds)0: jdbc:phoenix:> upsert into bankaccount(customer_id, balance) select customer_id, balance + 50 from bankaccount where customer_id = 'CU002';1 row affected (0.021 seconds)0: jdbc:phoenix:> !commitCommit complete (0.044 seconds)0: jdbc:phoenix:> select * from bankaccount;+-------------+------+---------+| CUSTOMER_ID | NAME | BALANCE |+-------------+------+---------+| CU001 | foo | 50.0 || CU002 | baa | 150.0 |+-------------+------+---------+2 rows selected (0.068 seconds)// Starts transaction 2 to transfer 20 from CU001 to CU0020: jdbc:phoenix:> upsert into bankaccount(customer_id, balance) select customer_id, balance - 20 from bankaccount where customer_id = 'CU001';1 row affected (0.014 seconds)0: jdbc:phoenix:> upsert into bankaccount(customer_id, balance) select customer_id, balance + 20 from bankaccount where customer_id = 'CU002';1 row affected (0.349 seconds)// Rollback the changes0: jdbc:phoenix:> !rollbackRollback complete (0.007 seconds)// Should get the same result as above after rollback.0: jdbc:phoenix:> select * from bankaccount;+-------------+------+---------+| CUSTOMER_ID | NAME | BALANCE |+-------------+------+---------+| CU001 | foo | 50.0 || CU002 | baa | 150.0 |+-------------+------+---------+2 rows selected (0.038 seconds)
1(b):Phoenix胖瘦客户端(使用Java应用):
try (Connection conn = DriverManager.getConnection(jdbcUrl)) {Statement stmt = conn.createStatement();stmt.execute("CREATE TABLE IF NOT EXISTS ITEM " +" (id varchar not null primary key, name varchar, quantity integer) transactional=true");conn.setAutoCommit(false);stmt = conn.createStatement();stmt.execute("UPSERT INTO ITEM VALUES('ITM001','Book', 5)");stmt.execute("UPSERT INTO ITEM VALUES('ITM002','Pen', 5)");conn.commit();stmt.execute("UPSERT INTO ITEM VALUES('ITM003','Soap', 5)");conn.rollback();ResultSet rs = stmt.executeQuery("SELECT count(*) FROM ITEM");// The number of rows should be two.System.out.println("Number of rows " + rs.next());}
异常处理
try (Connection conn = DriverManager.getConnection(jdbcUrl)) {try {Statement stmt = conn.createStatement();stmt.execute("CREATE TABLE IF NOT EXISTS ITEM " +" (id varchar not null primary key, name varchar, quantity integer) transactional=true");conn.setAutoCommit(false);stmt = conn.createStatement();stmt.execute("UPSERT INTO ITEM VALUES('ITM001','Book', 5)");stmt.execute("UPSERT INTO ITEM VALUES('ITM002','Pen', 5)");conn.commit();} catch (SQLException e) {LOG.error("Error occurred while performing transaction:", e);conn.rollback();// handling the exception objectthrow new RuntimeException(e);}}
2:Phoenix spark 应用程序
如果与其他作业或流应用程序有任何冲突,您可以使用 Phoenix-Spark 连接器事务来重试 Spark 任务。
COD 在写入表时支持以下两种类型的事务。
Batch wise transactions :将phoenix.upsert.batch.size设置为任何正整数值以为特定行数的批次创建事务。
Partition wise transactions :将phoenix.upsert.batch.size设置为 0 以便为每个任务创建一个事务。
示例代码的 Git 链接:https://github.com/cloudera/cod-examples/tree/main/phoenix-spark-transactions
val tableName: String = "SPARK_TEST"val conn = DriverManager.getConnection(url)var stmt = conn.createStatement();stmt.execute("CREATE TABLE SPARK_TEST" (ID INTEGER PRIMARY KEY, COL1 VARCHAR, COL2 INTEGER) TRANSACTIONAL=true" +" SPLIT ON (200, 400, 600, 800, 1000)")val spark = SparkSession.builder().appName("phoenix-test").master("local").getOrCreate()val schema = StructType(Seq(StructField("ID", IntegerType, nullable = false),StructField("COL1", StringType),StructField("COL2", IntegerType)))// Write rows from 1 to 500.var dataSet = List(Row(1, "1", 1), Row(2, "2", 2))for (w <- 3 to 500) {dataSet = dataSet :+ Row(w, "foo", w);}var rowRDD = spark.sparkContext.parallelize(dataSet)var df = spark.sqlContext.createDataFrame(rowRDD, schema)// Batch wise transactions:// ========================// Setting batch size to 100. For each batch of 100 records one transaction gets created.var extraOptions = "phoenix.transactions.enabled=true,phoenix.upsert.batch.size=100";df.write.format("phoenix").options(Map("table" -> tableName, PhoenixDataSource.ZOOKEEPER_URL -> zkUrl,PhoenixDataSource.PHOENIX_CONFIGS -> extraOptions)).mode(SaveMode.Overwrite).save()// Write rows from 500 to 1000.dataSet = List(Row(501, "500", 500), Row(502, "502", 502))for (w <- 503 to 1000) {dataSet = dataSet :+ Row(w, ""+w, w);}// Partition wise transactions:// ===========================// Setting batch size 0 means for partition one transaction gets created.rowRDD = spark.sparkContext.parallelize(dataSet)df = spark.sqlContext.createDataFrame(rowRDD, schema)extraOptions = "phoenix.transactions.enabled=true,phoenix.upsert.batch.size=0";df.write.format("phoenix").options(Map("table" -> tableName, PhoenixDataSource.ZOOKEEPER_URL -> zkUrl,PhoenixDataSource.PHOENIX_CONFIGS -> extraOptions)).mode(SaveMode.Overwrite).save()
如何使用不同工具的事务
您在访问 COD 事务时使用的主要操作是自动提交开/关、提交和回滚。这些操作使用不同的工具以不同的方式执行。
在本节中,您可以找到流行的 SQL 开发工具(如DbVisualizer )的链接和示例片段。
数据库可视化工具:
https://confluence.dbvis.com/display/UG100/Auto+Commit%2C+Commit+and+Rollback
总结
在这篇博文中,我们讨论了 COD 如何使用 OMID 管理在多个终端发生的事务。我们还包括各种场景,您可以在其中包含 COD 事务和描述如何在实时场景中实施事务的端到端流程。
那么,您准备好试用 COD 事务支持了吗?这是使用 COD 创建数据库的第一步。
附件
附件一:
第 1 步:HBase UI > Configurations选项卡中的以下属性设置为“true”。
phoenix.transactions.enabled=true
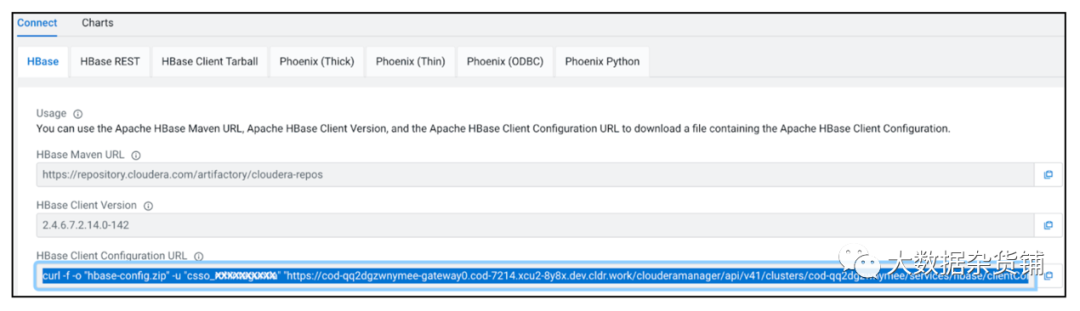
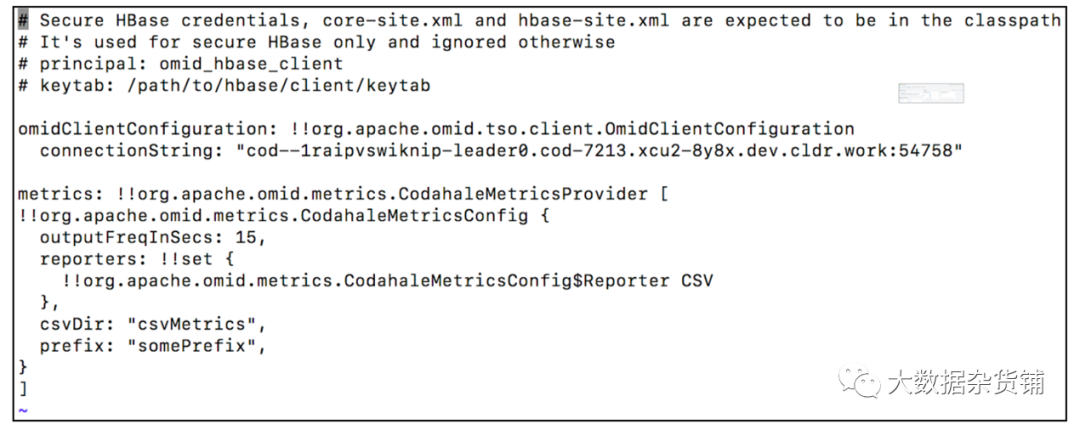
第 2 步:COD 生成 OMID 客户端配置文件hbase-omid-client-config.yml,其中包含事务服务器地址。
您可以使用以下命令下载客户端配置文件并使用应用程序类路径中的配置以及 hbase-site.xml。


原文作者:Raj Rathee, Biplab Chakraborty, Thiriguna Rao, and Rajeshbabu Chintaguntla
原文链接:https://blog.cloudera.com/transaction-support-in-cloudera-operational-database-cod/
