




Pipeline的背景
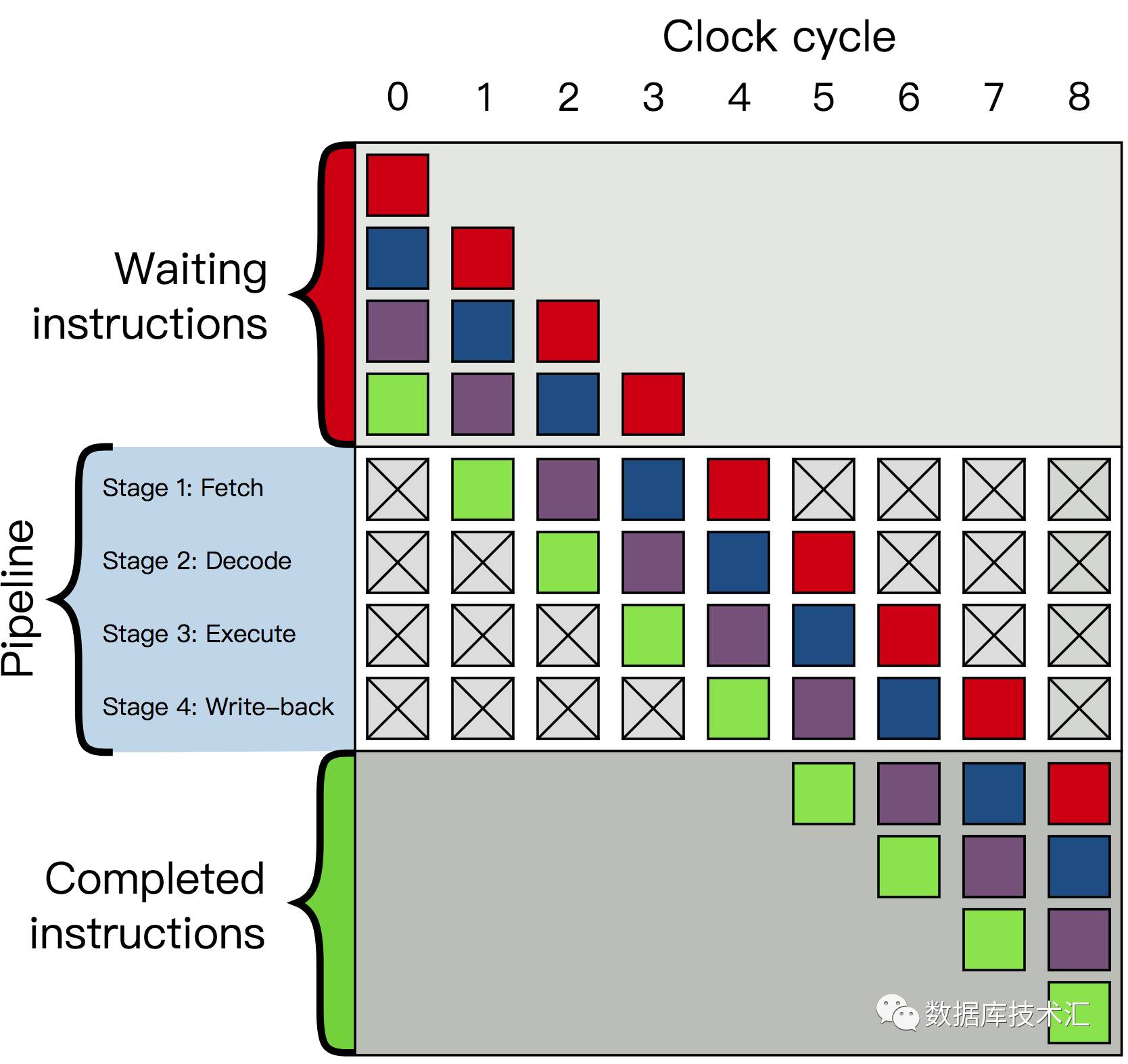
如果任务/数据的处理流程中,可以被分解成多个子任务或者多个阶段,那么通常都可以借鉴Pipeline思想来设计算法或者系统架构。 它表示“流水线”形式的并发模型,例如在流水线处理器中的使用。具体我们来定义Pipeline的适用场景:
如果我们要解决的问题是由一些列的计算操作组成的,每一个计算操作都可以划分成不同的阶段,同一个计算操作的多个阶段间的前后关系是固定不变的,但是不同计算操作的不同阶段是可以同时执行的。从本质上看,其实Pipeline可以用于一个复杂系统的总体架构,而不同的阶段内部,还可以设计成其他模式、采用其他数据结构来解决各阶段局部的问题。
Pipeline在下面两种情况下是十分有效的:
相比计算操作可以分解成的阶段数目,计算操作的量非常大
可以把一个处理单元或者至少是一个阶段,分派给一个线程(或者协程)
Pipeline的常见分类
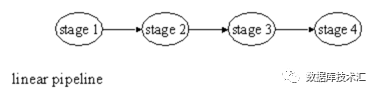
线性Pipeline
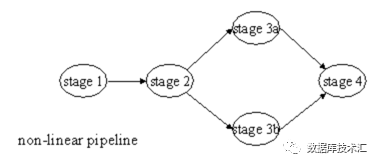
非线性Pipeline
Pipeline的核心思想及应用
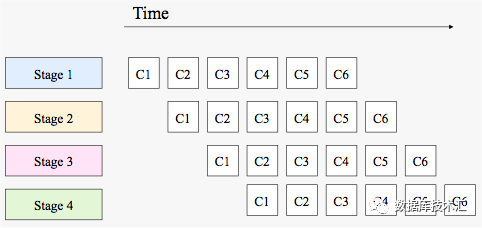
Pipeline的核心是一个计算操作被分解成前后相关的多个Stage,通常前一个Stage的输出作为后一个Stage的输入,而各个Stage之间没有其他的依赖关系。如下图所示,C1,C2,… ,Cn表示不同的待处理任务,每一个任务被分解为Stage1,Stage2,Stage3和Stage4一共4个阶段。从这个示意图可以看出,我们可以把各个Stage使用独立的线程(或者协程)来处理,每一个Stage之间可以通过Queue等方式来传递不同Stage间的输出和输入,因为上一个Stage的输出就是下一个Stage的输入。
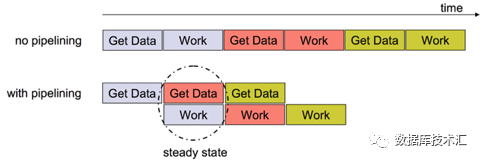
换一个方式来理解Pipeline的意义,如下图所示,如果我们的任务模型是Get Data — Work(对数据进行计算)这样一种常见的方式,为了保证任务处理的时序性,一般很难把这些任务分派到多线程中来执行,因为无法保证任务间的前后时序关系。有些情况下可以使用“乱序执行,顺序提交”的思路,但是应用这种思路需要有一些额外的前提,不是一种通常的处理办法。但Get Data — Work这种常见的任务模型,采用Pipeline模式的门槛就低了很多。
MySQL semi-sync复制的思路就是如此(https://dev.mysql.com/worklog/task/?id=6630):MySQL 5.7.4之前的semi-sync采用下图所示的no pipelining方式,发送binlog events的线程发送完毕后,自己再等待slave端回应的ack;MySQL 5.7.4通过将发送binlog events和接收slave端的回应ack的任务分解到不同的线程,极大地提高了MySQL semi-sync复制的性能,究其本质,其实核心的还是Pipeline的思想,将binlog events的复制分为sending和wait ack这样两个Stages。
当然Pipeline思想的应用其实有很多,在很多高并发/高性能的系统中都可以看到Pipeline思想的影子,比如非常经典的SEDA(https://en.wikipedia.org/wiki/Staged_event-driven_architecture)架构,其中核心思想和Pipeline有异曲同工之妙。在数据库系统中,log manager的实现通常也是应用了Pipeline,Parallel Buffering和Group Commit等核心思想。
Pipeline的限制
Pipeline提升并发需要一个窗口期,如果我们把每一个Stage放到独立的线程中来执行,那么所有Stage线程都在执行任务的时候才是最理想的并发状况。所以Pipeline模式任务流越持续、量越大,效果就会越好。强调持续性是因为如果频繁在no pipeline和pipeline模式间切换,那么总体效果就大打折扣了,因为进入和退出pipeline模式时,整个系统的并发程度是比较低的。
Pipeline的总体并发程度以及对系统吞吐量的影响,取决于最慢的Stage。所以在分解问题的时候,如何在不影响正确性的前提下,尽量让每一个Stage的处理(计算)开销均衡,是一个难点,有时甚至是无法做到的,例如一些Stage中包含网络IO或Disk IO,这些开销取决于设备和部署结构。
参考资料
https://msdn.microsoft.com/en-us/library/gg663538.aspx
https://dev.mysql.com/worklog/task/?id=6630
https://en.wikipedia.org/wiki/Staged_event-driven_architecture
https://en.wikipedia.org/wiki/Instruction_pipelining
