




RDP的全称是Real-time Data Pipeline,是一个从关系数据库MySQL实时同步数据到NoSQL系统的数据管道。正如这个名字一样,RDP不生产数据,我们只是数据的“搬运工”。谈到数据传输管道,有几个基本的特性是使用方最关注的:
可用性:也就是系统可以对使用方提供什么样的SLA。在系统所承诺的SLA之外,使用方可以通过自己额外的设计、workaround来达成它们自己对其它系统(或者业务指标)的SLA承诺。
实时性:作为搬运工,“送货”时效如何?系统使用方注重总体端到端的延时。系统开发者,除了端到端,我们还关心每一个环节的延时,以及各个环节间交互是否合理、是否高效?
追溯性:作为“管道”,爬进管子里面去调查问题,或者凭经验规律揣测,显然都是比较不友好的体验。比较理想的状况是系统通过自证和他证两个方面,来达到可以让系统使用方、系统维护者可以轻松准确地找到问题所在。
总述
本文是RDP介绍系列的第二篇,我们首先从RDP团队理解数据实时性的视角,来分解RDP中关于实时性部分的设计及关键实现。在我们的理解中,提升系统实时性通常可以从下面两方面来想办法:a). 缩短数据处理过程中的I/O路径; b).精细化粒度的控制,使系统处理数据的并发度尽可能高。
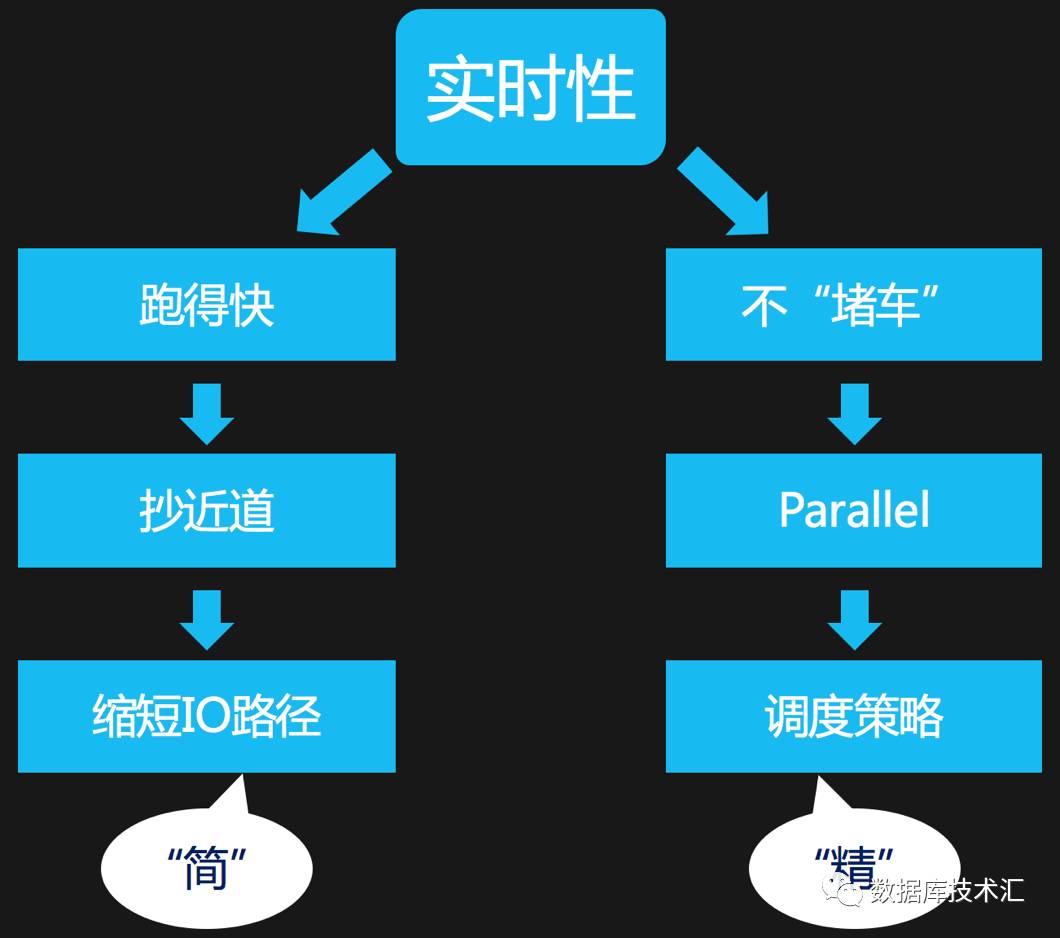
缩短数据IO路径的方向就是简化,避免不必要的环节和迂回,比如说把通过磁盘Relay的数据,换成通过内存队列来Relay。高并发在很多场合已经成为高性能的代名词,并发的粒度是多大,如何协调?如何调度?都是并发处理中必须要定义清楚的问题。通俗地讲,RDP项目中保障实时性的手段就是“精”和”简”,“精”是指如何精细化/细粒度地并发调度;“简”是指如何让整个系统流程简洁,简单的便是正确的;紧接着我们分开来讲这两点。
RDP如何缩短IO路径?
回到RDP项目的定位:数据管道,也就是将数据从MySQL搬运到其他地方,所以搬运途中要经过哪几站?每一站都干什么?哪些是必须完成的环节?这些是我们试图来精简IO路径前必须理清的问题。如下图所示:
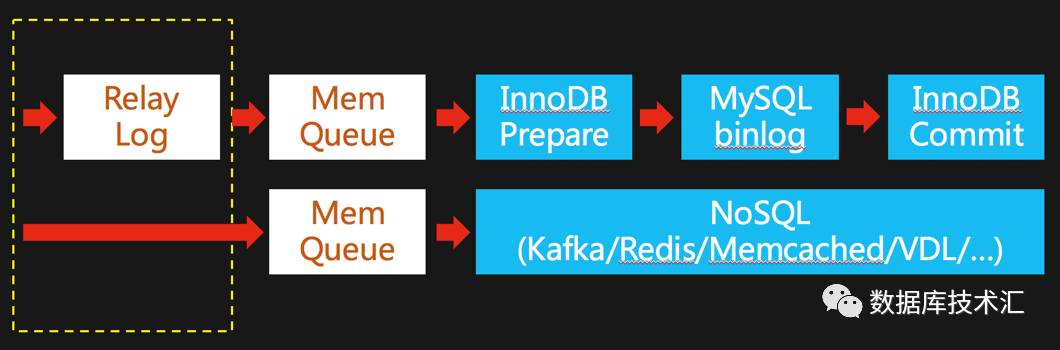
我们看到,还是老前提:因为我们依赖的基础还是MySQL主从复制技术。图中上面一部分是MySQL主从复制过程中MySQL Slave端的数据IO路径图:
1. IO线程收到数据先落盘到RelayLog文件中
2. [依赖不同的MySQL版本]SQL线程或者协调线程再从RelayLog中读取Binlog事件,以事务粒度回放到默认的InnoDB存储引擎
3. 在InnoDB内部,InnoDB Prepare环节
4. 从库MySQL Binlog落盘
5. 在InnoDB内部,InnoDB Commit环节。
MySQL配置为严格刷盘的模式,上述1/3/4/5步骤都会涉及到磁盘IO操作。我们分析一下,MySQL需要步骤1落盘,根源是以前MySQL Slave是单线程Replay事务,所以通常Slave的Replay速度要滞后于MySQL Master,所以通过RelayLog来缓冲。而对于RDP来说,只要我们后续环节的处理速度足够快,或者即便有数据Pending,我们任然可以保证数据的一致性,那么不用文件来缓冲也是可以的,MySQL worklog也曾提出过类似的想法:https://dev.mysql.com/worklog/task/?id=1616。而3/4/5三个步骤,主要是为了保证MySQL的ACID事务特性,需要在MySQL Binlog和InnoDB之间做(内部XA事务的)两阶段提交。RDP将数据推送到下游系统,我们并不完全关心下游系统内部处理的逻辑和细节(这是不同业务根据自身需求选择的)。所以我们只简单地作为一个Producer,把数据提交到下游系统就可以了,这个环节也没什么可以简化的了。
RDP之“高可用”篇中已经讲过,无论RDP是否优雅退出,Switchover/failover/Crash Recovery过程中,我们都可以保证RDP数据的一致性。所以我们在IO路径上直接使用内存队列,不再通过文件来先写后读缓冲MySQL Master端发送过来的Binlog事件。这也极大地减轻了RDP进程所在服务器的磁盘负载,让RDP进程成为CPU密集型的进程。由于通过内存队列来缓冲,数据处理的实时性上也得到了进一步的提升。
RDP如何并发处理数据?
在分析这个问题的时候,我们首先思考下面三个问题:
1. 并发的粒度或者单位是什么?
2. MySQL内核自身采用什么样的并发控制/回放技术?
3. RDP可以借鉴哪些方法和手段?
我们依次来回答这些问题,第一个问题:MySQL是一个严格遵循ACID属性的关系型数据库,是典型的OLTP型数据库,通常讲的MySQL MTS(Multi-thread Slave)是按照事务的粒度来并发控制的。第二个问题:MySQL内核中的并发回放技术,前后经历了很多个版本,简单总结如下:

仔细一想不难看出,所有并发控制的本质都是“剥离依赖”,实体A和实体B之间没有依赖、不会相互影响、执行顺序不会对最终结果产生影响,那么两者就可以并发执行。当然在关系数据库中,一个事务的“执行”和“提交”往往是两个不同的概念,而且通常是“执行”比较重(需要写日志、锁住资源等),“提交”比较轻(一般都是写一个标记)。所以保证并发“执行”是关键路径上的问题,为了保证Client看到的数据视图一致(避免Client查询到一个没有在主库上出现过的视图快照),“提交”顺序一般都需要保证和主库上完全一致,换句话说:“提交”的串行化是不可避免的。
但无论基于MySQL 5.7.2的Group Commit Parent还是MySQL 5.7.6的Lock Interval Based LogicalClock并发技术,始终存在的一个限制是:从库并发度小于(或等于)主库,如果主库压力小或者Client连接数少,这些并发技术的实际效果并不理想,如果是多级复制的架构,并发度会越来越低。最新的MySQL 8.0中http://mysqlhighavailability.com/improving-the-parallel-applier-with-writeset-based-dependency-tracking/,又提出了一种基于writeset的并发控制技术,核心手段是:Master在每一个事务的Binlog中记录其修改涉及的记录集,Slave上只要两个事务的记录集不冲突,就可以并发执行。如此以来,就解决了MySQL 8.0之前版本中限制!Oracle对MySQL内核并发控制技术的不断改进,足见并发控制技术在数据处理系统中的重要性。
最后回答第三个问题:RDP本质上是对数据进行搬运和翻译(或者叫做转换),可以借鉴的并发控制技术就是“剥离依赖”,只要乱序执行不会对最终下游系统查询到的数据产生影响,就可以并发处理。当然,并发的粒度就是以事务为单位。总的原则就是:乱序处理,顺序提交。紧接着我们细化下面两个问题:
1. RDP如何划分MySQL Binlog中事务的边界?
2. RDP并发调度的规则是什么?
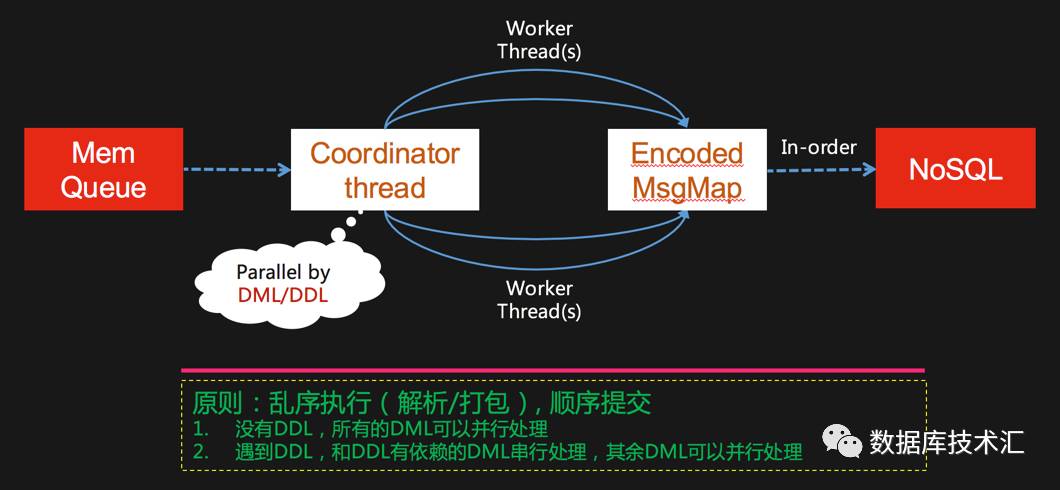
首先我们把事务分为DDL(DCL当成DDL的子集)和DML两大类,然后这两类事务的Binlog事件序列如下图左侧所示,下图右边的这个状态机示意图简单描述了如何根据Binlog事件类型来驱动判断事务的边界。

最后我们来讲到RDP提升整个系统实时性的关键部分,如下图所示,我们并发调度的原则是:DDL必须和其他所有事务串行处理,因为DDL会改变Schema,而RDP中每一个消息都会附带Schema版本信息,这样做的目的是保证其他系统可以通过RDP回溯任何时刻的数据,而且拿到的数据和其Schema是完全一一对应的。DDL之外,也就是DML是可以完全并发解析/打包的,由于生产环境的DDL不会特别频繁,所以这个并发调度策略的并行度是有保障的。另外,DDL和DML之间其实也是可以并行处理的,只要DML没有涉及到DDL变更中的Schema。
总结
总的来说,RDP通过在保证数据一致性的前提下,尽量简化不必要的IO操作环节,同时借鉴MySQL内核中多线程并发回放技术来尽量提升RDP数据处理的并发度这两个手段。确保了RDP处理数据的实时性,尤其是基于DDL/DML的并发处理技术,在我们所知的同质系统中,是第一次这么做。下一步,我们思考的问题包括:
1. RDP现在总体采用的是半同步/半异步的处理模型,这个模型的好处这里不展开,缺点是一个消息需要在queue中流转,要流经多个线程,(我们大多数场景下)线程切换的开销大不大?我们是否可以总体上采用Leader/Follower的处理模型,让所有的工作流环节在一个线程上下文中完成?
2. RDP现在的并发调度是一个Coordinator Thread分发Task给多个Worker Thread,调度过程中,允许一个Worker Thread有多个Task Pending到Worker的Task队列,还是执行完再分发下一个?前者阻塞Coordinator Thread的概率低,简单按Task队列深度来分发,很容易让某些Worker饥饿,某些过载。后者可以一定程度上避免负载不均的问题,但是可能阻塞Coordinator Thread。
大家有建议和想法,欢迎帮助我们~~~
