




分布式管控
分布式系统通常包含三个重要组成部分:
存储引擎
计算引擎
分布式管控层
ClickHouse 有一个非常突出的高性能存储引擎,但在分布式管控层显得较为薄弱,使得运营、使用成本偏高。主要体现在:
1.1 分布式表
ClickHouse 对分布式表的抽象并不完整,在多数分布式系统中,用户仅感知集群和表,对分片和副本的管理透明,而在 ClickHouse 中,用户需要自己去管理分片、副本。
例如前面介绍的建表过程:用户需要先创建本地表(分片的副本),然后再创建分布式表,并完成分布式表到本地表的映射。
1.2 弹性伸缩
ClickHouse 集群自身虽然可以方便的水平增加节点,但并不支持自动的数据均衡。例如,当包含 6 个节点的线上生产集群因存储或计算压力大,需要进行扩容时,我们可以方便的扩容到 10 个节点。但是数据并不会自动均衡,需要用户给已有表增加分片或者重新建表,再把写入压力重新在整个集群内打散,而存储压力的均衡则依赖于历史数据过期。
ClickHouse在弹性伸缩方面的不足,大幅增加了业务在进行水平伸缩时运营压力。基于 ClickHouse 的当前架构,实现自动均衡相对复杂,导致相关问题的根因在于 ClickHouse 分组式的分布式架构:同一分片的主从副本绑定在一组节点上。更直接的说,分片间数据打散是按照节点进行的,自动均衡过程不能简单的搬迁分片到新节点,会导致路由信息错误。
而创建新表并在集群中进行全量数据重新打散的方式,操作开销过高。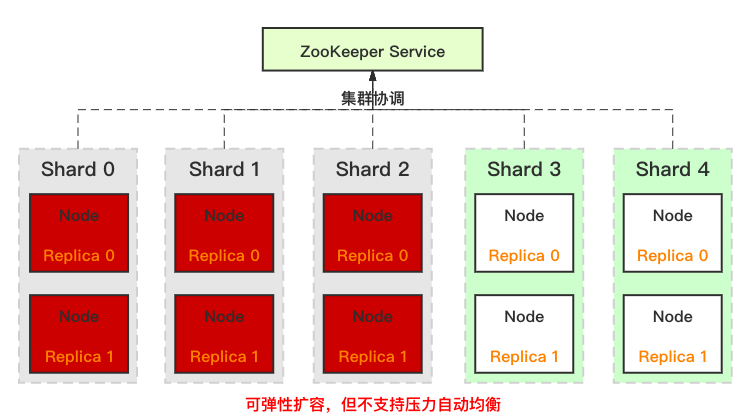
1.3 故障恢复
与弹性伸缩类似,在节点故障的情况下,ClickHouse 并不会利用其它机器补齐缺失的副本数据。需要用户先补齐节点后,然后系统再自动在副本间进行数据同步。
原文链接:https://blog.csdn.net/shan19920501/article/details/125235310
