





论文链接: https://arxiv.org/abs/2211.12561



一、引言
作者首先调研了其他图像文本合成方面的多模态模型,例如DALL-E[1]和Parti[2],这些模型的训练往往需要超大规模的训练数据量(1-10B图像)和可学习参数量(10-80B)来涵盖更丰富的知识。但这其实也是这些大模型目前所遇到的一个性能瓶颈,如果希望这些模型能够随着训练的不断进行而达到一种终生学习的效果,那考虑在模型中加入访问外部存储库应该是目前一个比较明智的做法。并且这种做法对于涉及独特实体知识的任务时会更有用,例如上面所列举的“法国国旗在月球表面飘扬”的例子,参考外部知识库可以帮助模型提高生成的准确性和可解释性。
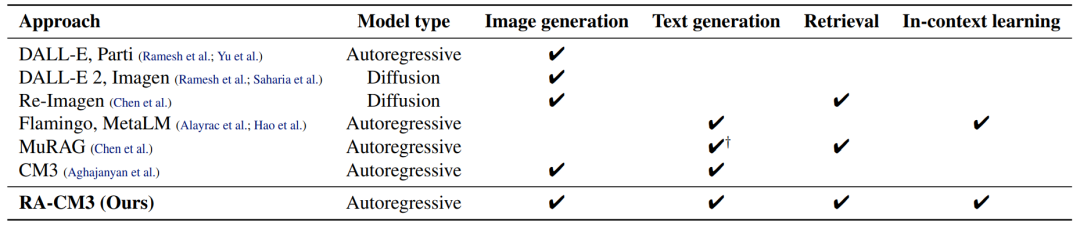
此外,本文作者在设计模型时还加入了检索增强技术,该技术其实在自然语言理解领域已有应用,例如给定一段输入文本,模型可以使用一个检索器,从外部知识库中检索相关文件,并让生成器使用检索到的文件来进行更好的预测。然而,这些检索增强的方法主要是针对文本研究的,将它们扩展到多模态环境仍然是一个具有挑战性的开放性问题。作者调研了一些在多模态领域研究数据检索增强的方法,但是这些工作的生成器都局限于单一的模式,要么是文本生成,要么是图像生成,如下表所示:
在本文中,作者提出了目前第一个利用检索增强技术的多模态模型RA-CM3,它可以同时检索和生成文本和图像。RA-CM3的输入数据和外部存储器由一组多模态文件组成,其中包含图像和文本的混合数据。为了应对这些输入数据,作者使用预训练的CLIP作为多模态编码器,然后基于CM3架构[3]设计了检索增强的生成器,其本质上是一个能够同时生成文本和图像的Transformer序列模型。在模型的具体操作中,作者将检索到的文件作为主输入文件的上下文信息,并通过联合优化主文件和检索到的文件的token预测损失来训练生成器。
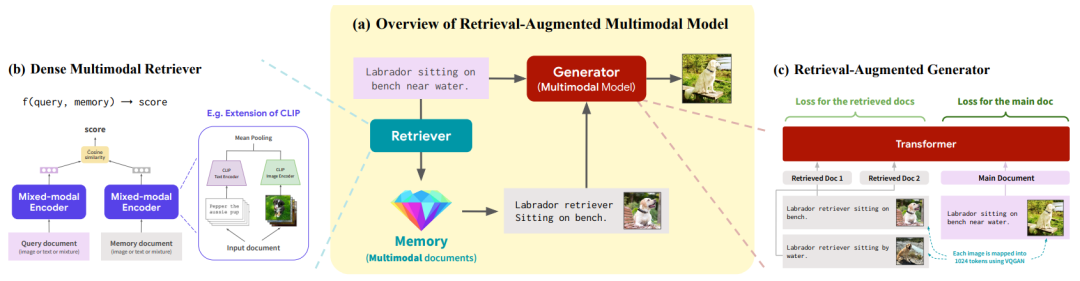
RA-CM3模型主要由三个核心模块构成:检索器(retriever),外部存储(memory)和生成器(generator)。整体框架图如下图所示。RA-CM3是一种可以同时检索和生成文本和图像混合模态的新架构。给定模型一个输入的多模态文件,RA-CM3先使用检索器从外部存储器中检索相关的多模态文件,送入生成器中来对输入文件进行预测。作者将多模态检索器设计成一个密集的、具有混合模态编码特性的检索器,可以对文本和图像的混合文件进行编码。随后基于CM3 Transformer架构构建了一个检索增强的生成器用来合成准确的图像。下面我们将详细介绍这些模块的主要技术细节。
2.1 预定义
RA-CM3框架由检索器模块 和生成器模块 组成。其中检索模块 将输入序列 和外部存储器中的文档 作为输入,并返回检索目标文档列表 。随后生成器 将输入序列 和检索到的文档 合并作为输入,并返回生成目标 ,其中 是传统语言建模任务中单独文本生成 的延续。
2.2 多模态检索
上文提到,RA-CM3的检索器设计为密集编码型检索器,在实际操作时,检索器 首先从外部存储 中获取查询 (例如,输入序列 )和相关文档 ,并返回相关性分数,操作过程可以形式化表示如下:
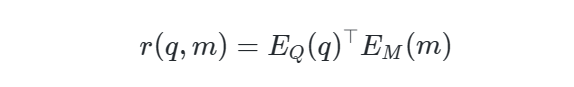
其中,查询编码器 和存储编码器 分别为查询和存储文件产生密集向量(如下图所示)。由于这里的输入和存储数据均为多模态文件,因此 和 必须是混合模态编码器,才可以对文本和图像同时进行混合编码。作者通过实验表明,这里直接采用CLIP作为混合编码器可以获得非常好的效果。
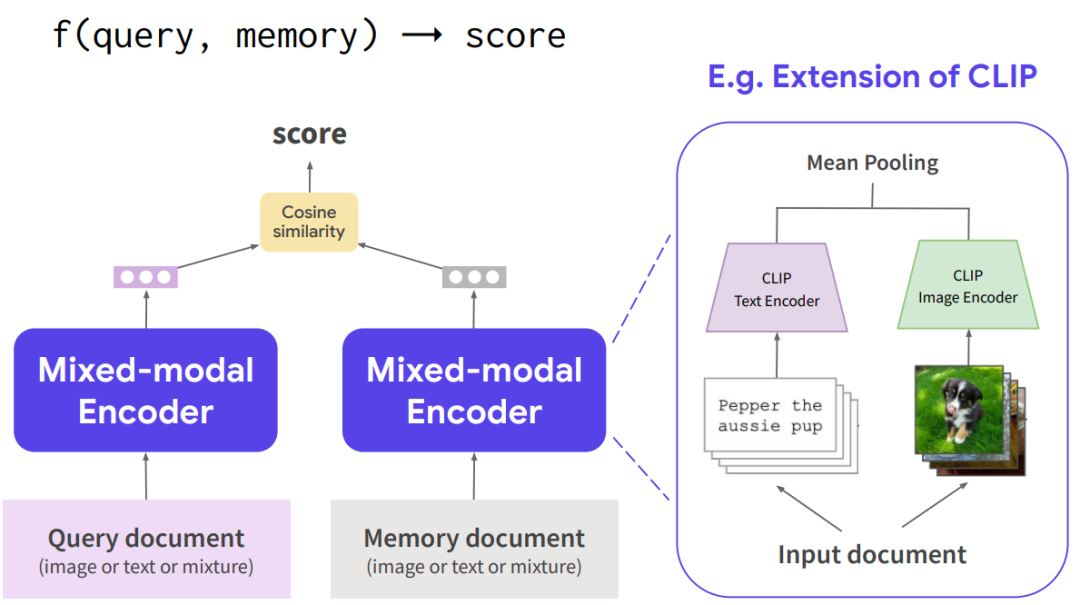
具体来说,给定一个多模态文档,首先将其分成文本部分和图像部分,用预训练的CLIP文本和图像编码器分别对这两部分进行编码,然后对这两部分进行融合并执行规范化,作为文档的向量表示。随后在存储模块中执行最大内积搜索并按照相关性得分对候选文档列表进行排序,最终从这个列表中选取 个最接近的检索文档。此外作者还发现保证检索文档的多样性对最终的生成效果至关重要。如果简单地根据相关性得分从文档列表中抽样或取前 个文件可能会得到重复或高度相似的图像或文本,从而导致生成器性能不佳。因此在获取文档时还需要将其与已检索到的文档计算相似性来排除冗余的文件。
2.3 多模态生成
RA-CM3的生成器遵循CM3 Transformer架构,为了将检索到的文档 合理的送入到生成器中,作者将它们添加到主输入序列 之前,得到一个整体输入序列 ,我们可以将其理解为:检索到的文档 是主输入序列 的上下文示例,如下图所示:
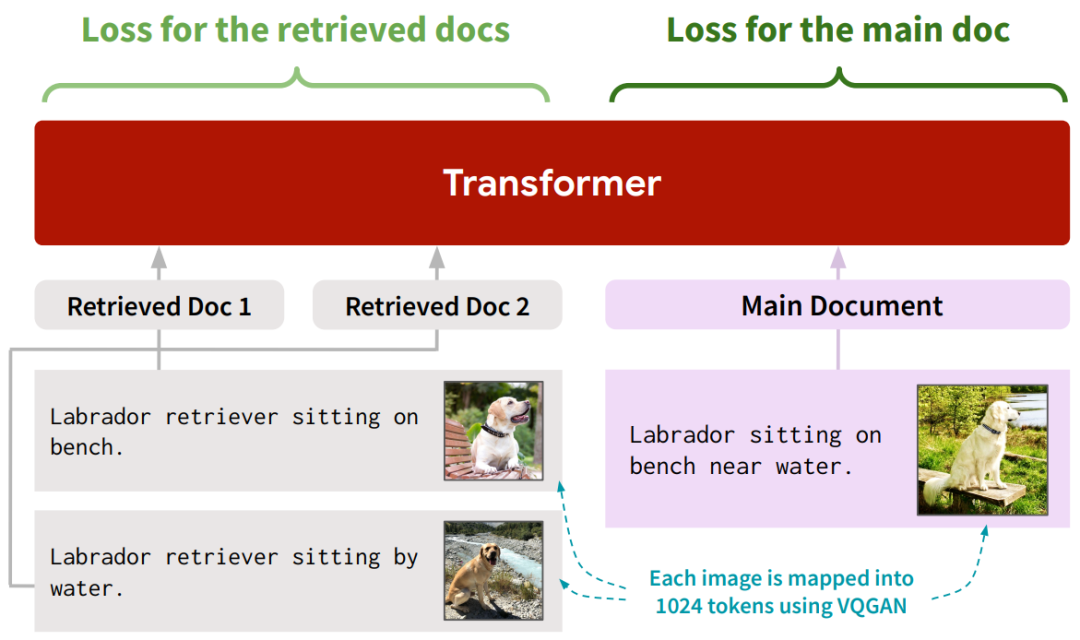
为了训练生成器,作者迭代优化下面的目标函数:
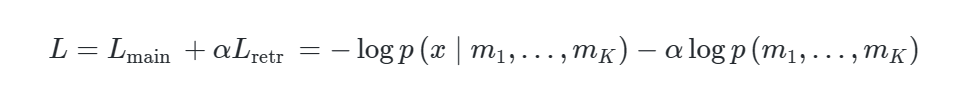
其中 和 分别是主输入序列 和检索到的文档 的CM3 token预测损失。相比之前方法只优化主序列 ,这里作者同时优化主序列和检索序列的token,有效提高了模型的训练效率。
三、实验结果
为了验证本文提出的RA-CM3模型,作者先在LAION多模态数据集上训练模型,随后在MS-COCO上进行图像文本合成任务评估,评估任务主要包括文本到图像生成(Caption-to-image)、图像到文本生成(Image-to-caption)和图像填充和编辑(Image infilling and editing)。
3.1 文本到图像生成
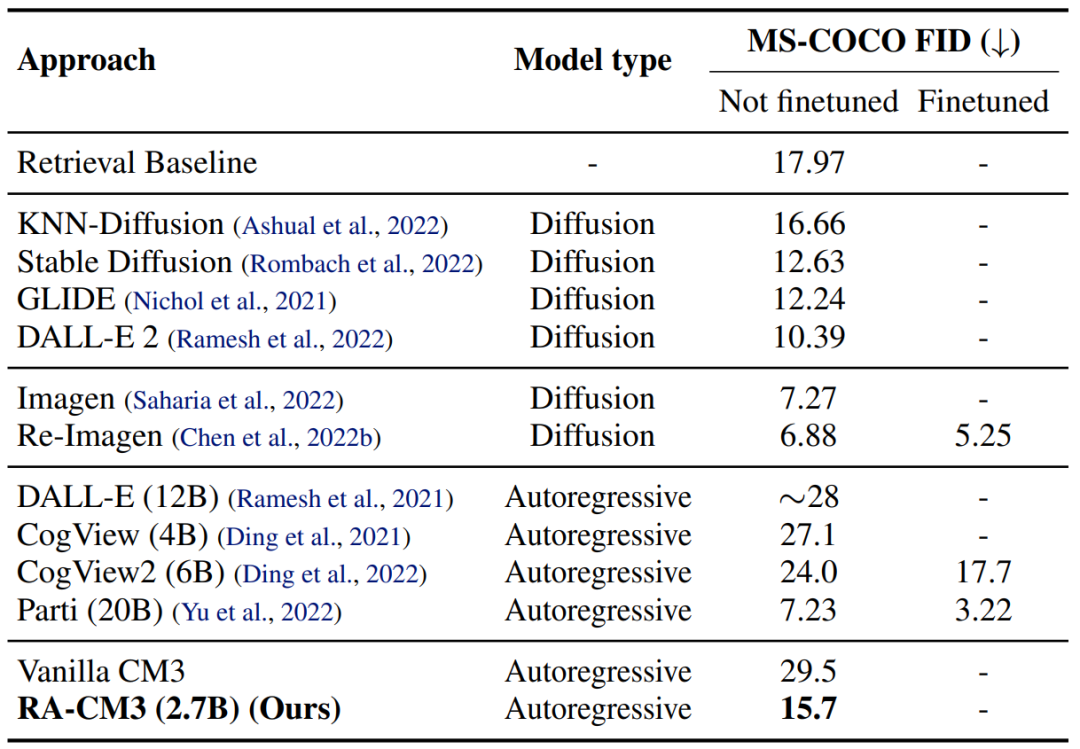
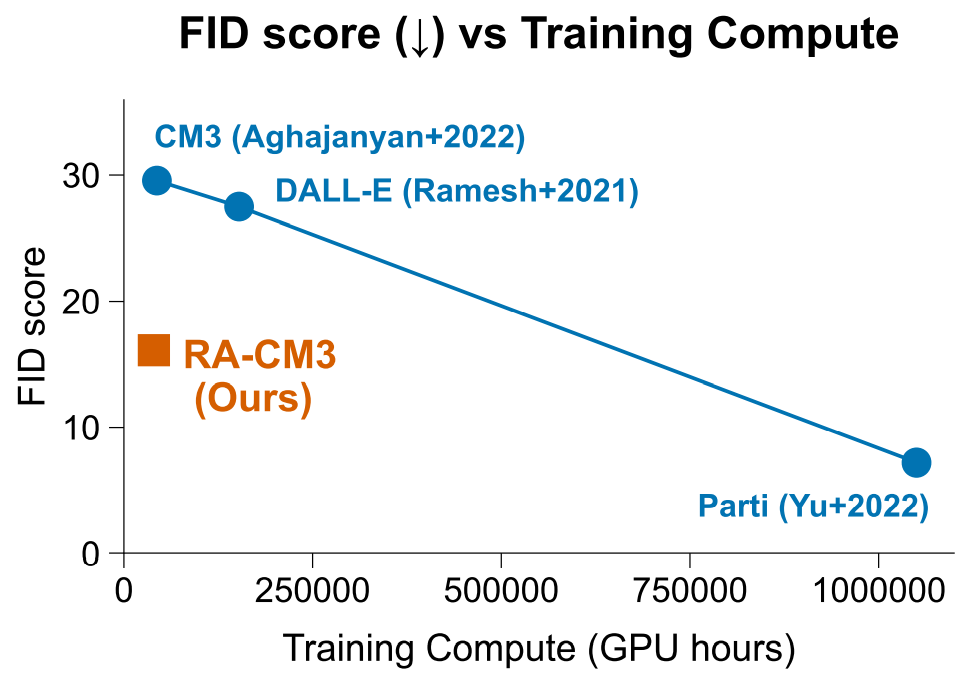
3.2 图像到文本生成
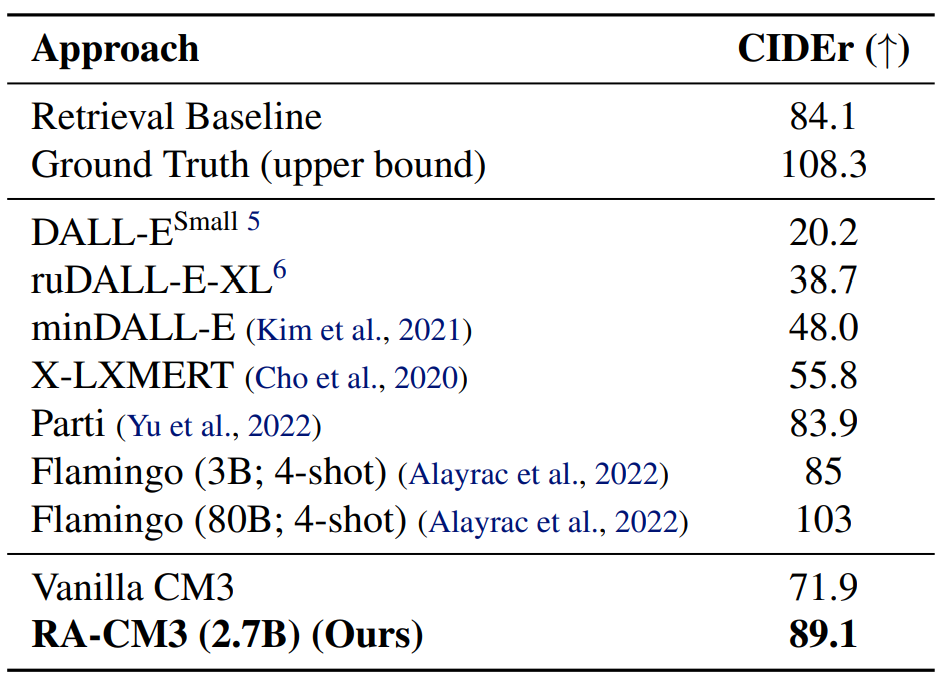
3.3 图像填充和编辑


四、总结
在这项工作中,作者直面目前文本图像合成领域中的痛点问题,提出了一个更加智能的AI大模型RA-CM3。RA-CM3在原有预训练大模型的基础上引入了检索增强机制,以便于模型从外部存储库中检索和引用新知识参与到新图像的合成中。这种设计赋予了模型可以同时对图像和文本混合数据进行编码的能力,同时也大大降低了模型的训练成本和参数容量。此外,RA-CM3在一些精确度要求较高的图像合成场景中会有更好的可信度和可解释性。从另一个角度来看,RA-CM3的提出为社区提供了一种全新通用的、模块化的检索增强多模态框架,相信其能够为这一领域开辟更多有趣的研究途径。
参考
[1] Ramesh, A., Pavlov, M., Goh, G., Gray, S., Voss, C., Radford, A., Chen, M., and Sutskever, I. Zero-shot text to-image generation. In International Conference on Machine Learning (ICML), 2021.
[2] Yu, J., Xu, Y., Koh, J. Y., Luong, T., Baid, G., Wang, Z., Vasudevan, V., Ku, A., Yang, Y., Ayan, B. K., et al. Scaling autoregressive models for content-rich text-to-image generation. arXiv preprint arXiv:2206.10789, 2022.
[3] Aghajanyan, A., Huang, B., Ross, C., Karpukhin, V., Xu, H., Goyal, N., Okhonko, D., Joshi, M., Ghosh, G., Lewis, M., and Zettlemoyer, L. CM3: A causal masked multimodal model of the internet. arXiv preprint arXiv:2201.07520, 2022.
作者:seven_

扫码观看!
本周上新!

多家技术企业招聘来啦!
扫描了解详情~


关于我“门”
▼

点击右上角,把文章分享到朋友圈
