点击上方蓝色【数据攻略】关注+星标~
第一时间获取最新内容
最近不少同学反馈
面试中碰到不少「留存」相关的问题
的确,流量红利逐渐消失
留存作为各大平台重要的KPI指标之一
当然也成为各大厂面试官的热门出题点
在笔试、面试中出现频率、花活也越来越多
所以本篇,咱们就从简到深
从指标定义、方法应用
再结合SQL实操(含数据集)
细细来唠唠
一、基础概念
二、衍生指标
三、留存分析方法
四、SQL实战(含数据集)
基础概念
▌高频概念
▼新注册留存用户
▼次日留存率
当日活跃用户中第二日依旧活跃的用户占比,也就是(当日活跃∩次日活跃用户)/ 当日活跃用户数
▼3日留存率
当日活跃且后3日依旧有活跃的用户占比,也就是(当日活跃∩后3日活跃用户)/ 当日活跃用户数
▼第3日留存率
当日活跃且第3日依旧有活跃的用户占比,也就是(当日活跃∩第日活跃用户)/ 当日活跃用户数,第三日留存率和三日留存率的差异就是分子统计活跃的时间窗口不一样
▼N日留存率
当日活跃且后N日依旧有活跃的用户占比,也就是(当日活跃∩后N日活跃用户)/ 当日活跃用户数
▼第N日留存率
当日活跃且第N日依旧有活跃的用户占比,(当日活跃∩第N日活跃用户)/ 当日活跃用户数
▌Case
这里引入一个简单的案例进行计算
下图是某平台每日的活跃用户:

下图是每日的次留率
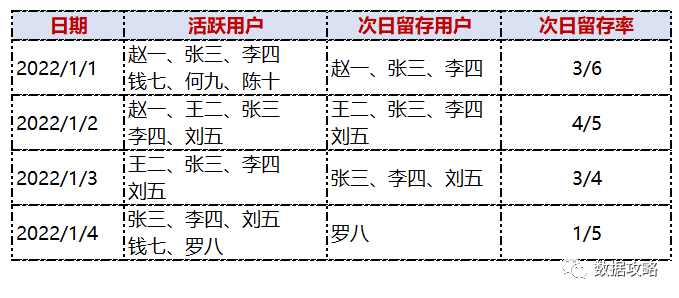
下图是三日和第3日的留存如下

衍生指标
了解了前面的基础概念
再来讲讲留存中常用的衍生指标
▼留存周期
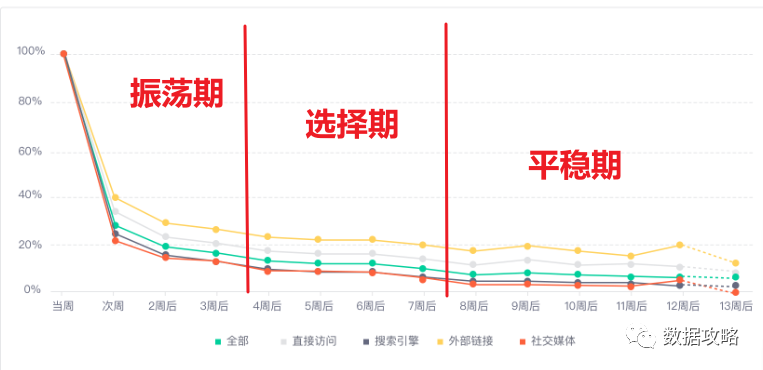
根据用户留存的下降趋势可以将用户留存分成三个周期
振荡期,我们主要关注用户激活,在这个阶段中,我们需要让用户迅速低成本地感受到产品的核心价值
选择期(蒸馏期、淘汰期),在这个阶段,用户对产品有初步了解,开始探索产品是否满足其核心需求,我们就要关注老用户的留存提升,打造好产品的核心功能,培养用户对产品的使用习惯。
平稳期,用户已经基本养成使用习惯,我们接下来就要思考产品对用户的长期价值是什么,如何才能让用户反复体验到产品的价值。
留存分析方法
在日常工作中会经常碰到例如
留存相关的异常分析\探索等问题
因此接下来讲讲有关留存的常用分析方法
为了让大家更好理解
我会引入一个具体的业务问题
将对应分析方法的应用做一个简单demo:
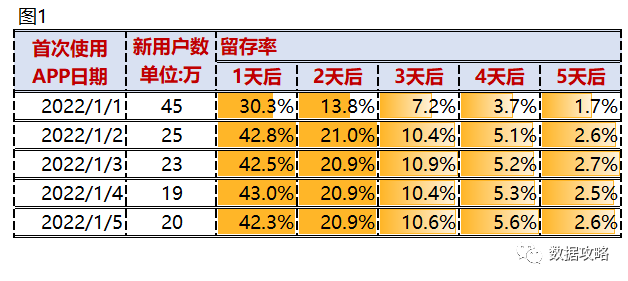
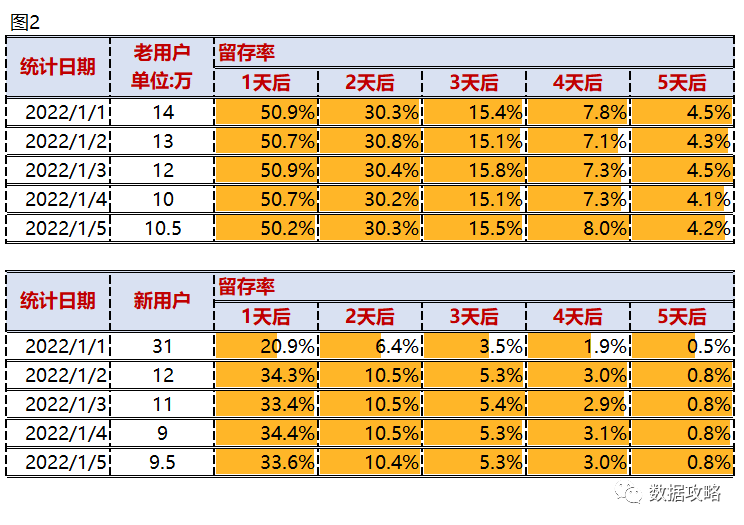
举例:比如下面根据每天的注册的用户进行拆分分组,观察用户1天~5天的留存情况。从下面的结果中发现,2022.1.1活跃度用户,1-5天的留存率均低于其他日期。但是2022.1.1当日活跃用户数也远高于其他日期。猜测是当日可能引入了一波新用户。
▼子方法① :新老用户同期群留存分析法
继续前面提到的数据和猜想,我们将用户拆分成新老客,数据如下:
老客的留存率相对比较稳定,每天无明显差异。 2022.1.1的新客引入量为31万,留存率远低于其他日期
▼Tips:
新老用户在留存上存在非常大的差异 新老用户的组成比例也容易出现辛普森悖论
关于辛普森悖论,可参考往期文章
由于每个渠道的获客成本不一样,分析每个渠道的留存率尤其是新用户的留存率就非常重要。留存率高说明是一个高价值渠道,后续可尝试做更多的投入。
图3
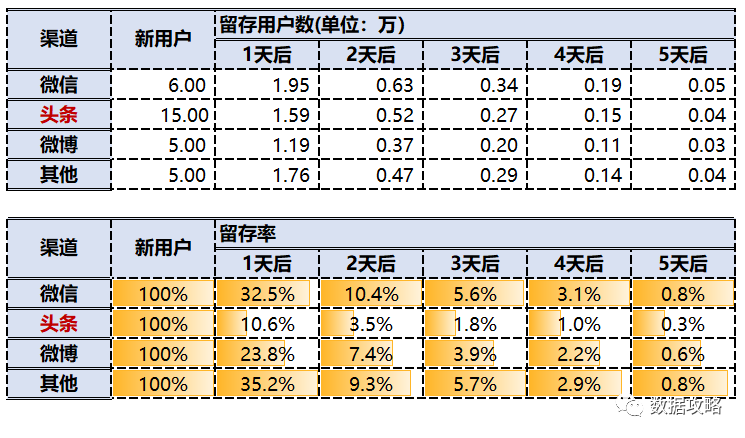
为了更加直观的看到头条与其他渠道的差异,下面用曲线图表示:
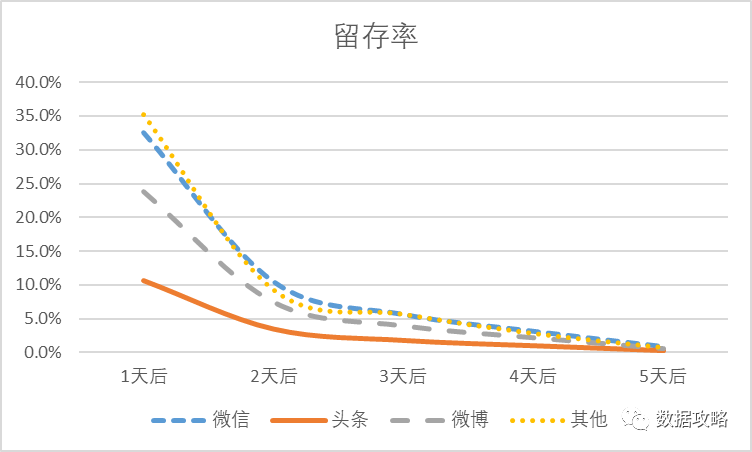
▼Tips: 图像相比表格数据更能直观获取到数据结果。
▌方法二:产品功能留存矩阵
对于平台不同的产品尤其是同类型产品,比如淘宝的种树浇水、种果树等均属于游戏类产品。可以通过分析不同产品/产品内的重要功能模块的使用量和留存率进行分析比对,进一步来定位留存表现。
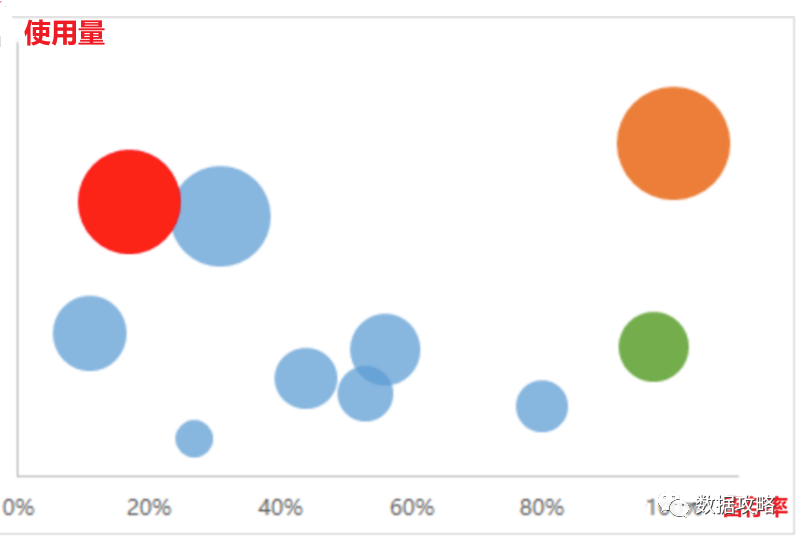
图中最右上的橘色代表该功能留存率和使用量均很高,这类产品可以进行监控,对流失用户进行预警挽留。 图中左上角的红色代表使用量高但是留存率低,这类产品应优化产品,增加用户粘性。
图中右下角绿色代表使用量低但是留存率高,这类产品应该扩大用户影响面,提高使用的用户量。
至此,结合新老用户,同期分期,渠道,产品功能,基本定位了2022.1.1留存异常的问题。
最后针对本次Case,再来做个小的总结:
① 首先通过同期群对比发现,1月1日的活跃用户多但是留存率低 ② 然后对用户进行新老客拆分,并进行同期群比较,得到①中的问题主要是新客引起的。
③ 为了进一步了解新用户的注册来源,对1月1日新注册的用户进行了渠道拆分,发现头条过来注册的新用户量大但是留存率较低,进而推导出头条注册新用户质量较差的结论。
④ 对头条新注册的用户再做进一步的拆分,结合平台的产品功能,分析产品功能留存矩阵,对比挖掘出具体是哪个产品功能的用户留存率更低,以便后续给到产品相关优化建议。
▌Tips
SQL实战
留存作为SQL笔面试中的高频考点
同时,也为了加强大家对留存指标的理解
这里我出一个SQL的测试题供大家自测
表①:用户活跃表(user_actv_log)
用户ID:uid
活跃日期:dt
表②:用户城市信息表(user_info)
用户ID:uid
用户所在城市: city
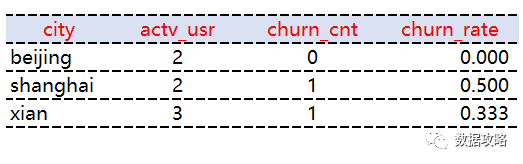
请统计每个城市2021年6月30日当天的活跃用户及流失情况。
6.30活跃定义为6.1~6.30期间活跃 6.30流失定义为7.1~7.30期间没有活跃
城市信息:city
活跃人数:actv_usr
流失人数: churn_cnt
流失率: churn_rate
SELECTc.city,COUNT(1) AS actv_usr,SUM(CASE WHEN b.uid IS NULL THEN 1 ELSE 0 END) AS churn_cnt,SUM(CASE WHEN b.uid IS NULL THEN 1 ELSE 0 END)/COUNT(1) AS churn_rateFROM(SELECTuidFROM user_actv_log aWHERE dt >= '2021-06-01'AND dt <= '2021-06-30'GROUP By uid)aINNER JOIN user_info cON a.uid = c.uidLEFT JOIN(SELECTuidFROM user_actv_log aWHERE dt >= '2021-07-01'AND dt <= '2021-07-30'GROUP By uid)bON a.uid = b.uidGROUP By c.cityorder by city , actv_usr
想动手实操的同学,可复制下面数据集到本地进行测试
CREATE TABLE user_actv_log(`uid` int, `dt` date);INSERT INTO user_actv_log(`uid`, `dt`)VALUES(1, '2021-06-01'),(1, '2021-06-03'),(2, '2021-06-30'),(4, '2021-06-03'),(5, '2021-06-30'),(1, '2021-07-02'),(2, '2021-07-02'),(3, '2021-07-02'),(4, '2021-07-03'),(5, '2021-08-30'),(6, '2021-07-02'),(7, '2021-07-02'),(8, '2021-07-03'),(9, '2021-08-30'),(7, '2021-06-02'),(8, '2021-06-03'),(9, '2021-06-30');CREATE TABLE user_info(`uid` int, `city` varchar(8));INSERT INTO user_info(`uid`, `city`)VALUES(1, 'shanghai'),(2, 'beijing'),(3, 'shanghai'),(4, 'beijing'),(5, 'shanghai'),(6, 'beijing'),(7, 'xian'),(8, 'xian'),(9, 'xian'),(10, 'beijing'),(11, 'shanghai');
资料库部分资料列举:

 往期好文推荐
往期好文推荐 更多 『求职干货』 & 『日常学习』 系列好文,等你发现~

Ps. 微信推文改了规则
看完记得设置为 “ 星标 ”
不然我会消失的