




全文链接:http://tecdat.cn/?p=30925
近年来商业银行利用先进数据挖掘技术对信用卡客户进行分类,区分不同的客户群体,然后针对不同客户群体,采取不同的发卡方式,营销策略,风险控制措施(点击文末“阅读原文”获取完整代码数据)。
这些举动都是十分有必要的,也是对信用卡产品获得市场份额有巨大帮助作用的。
在信用卡分析时,我们向客户演示了用SQL Server的数据挖掘算法可以提供的内容。
查看数据
查看信用卡资料库:
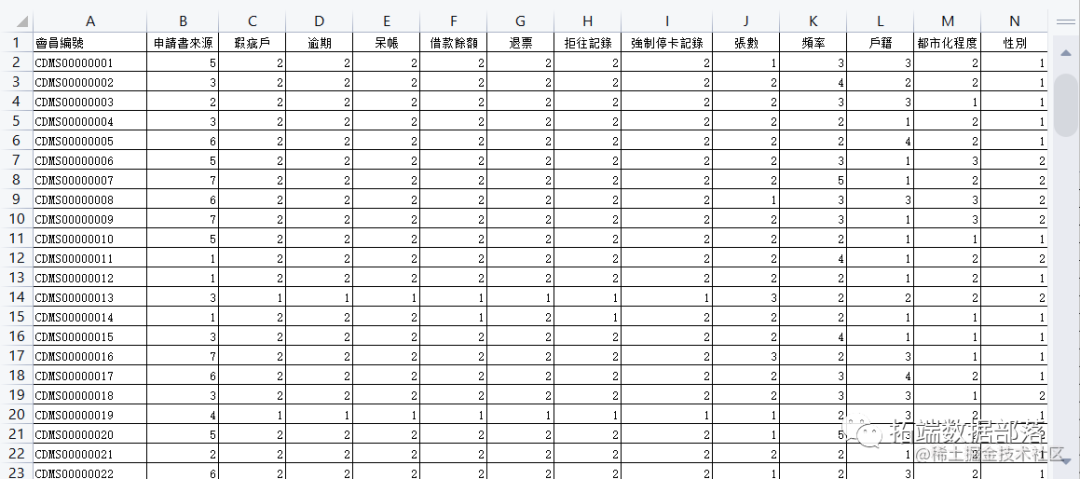 变量信息:
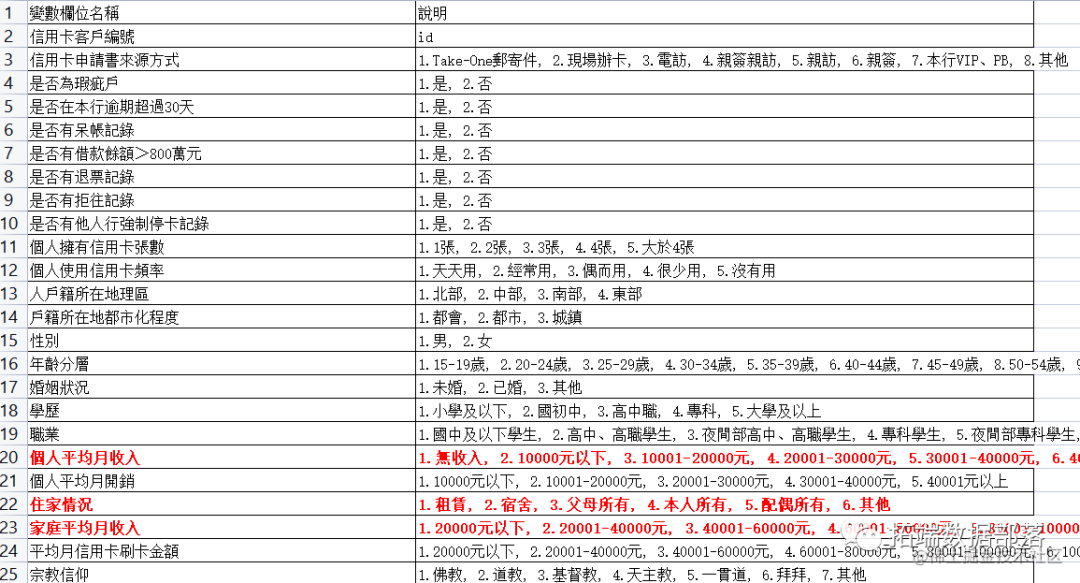
变量信息:
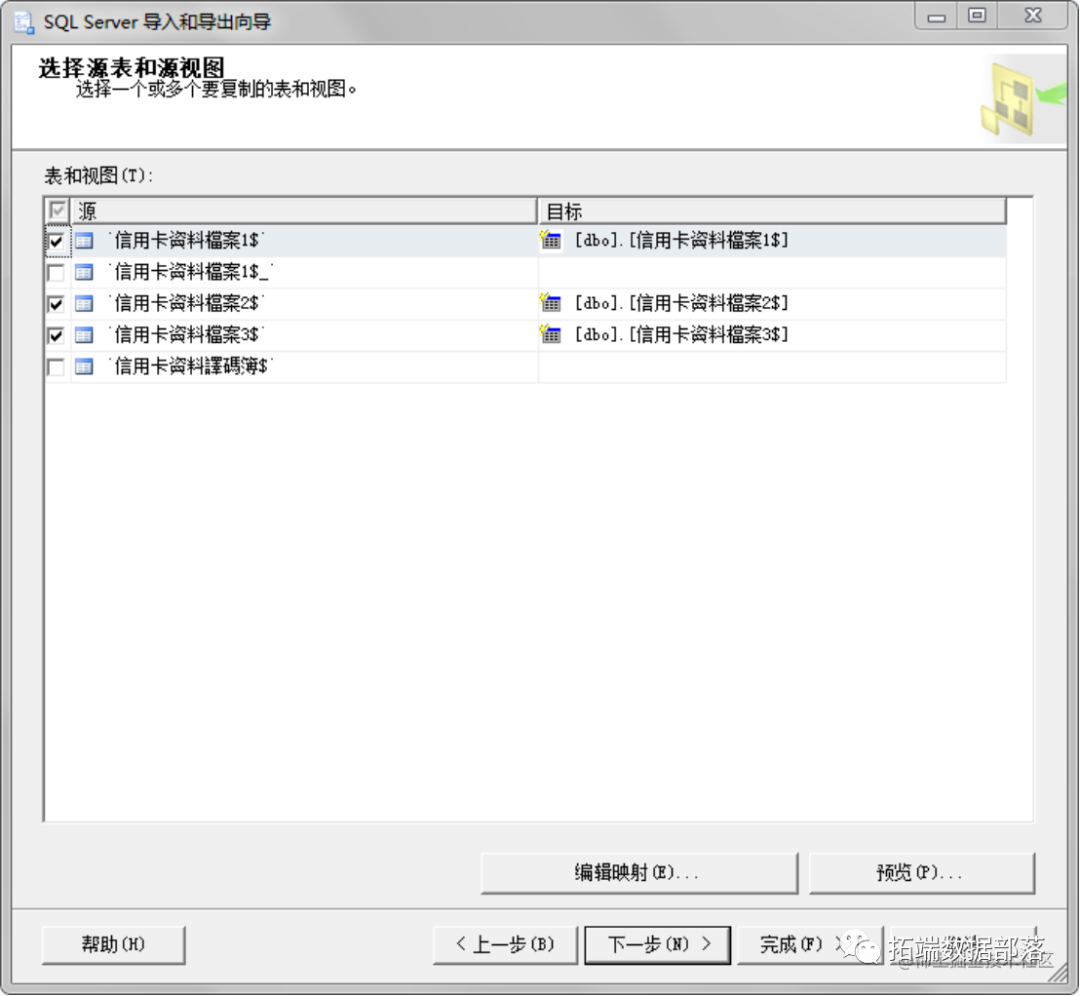
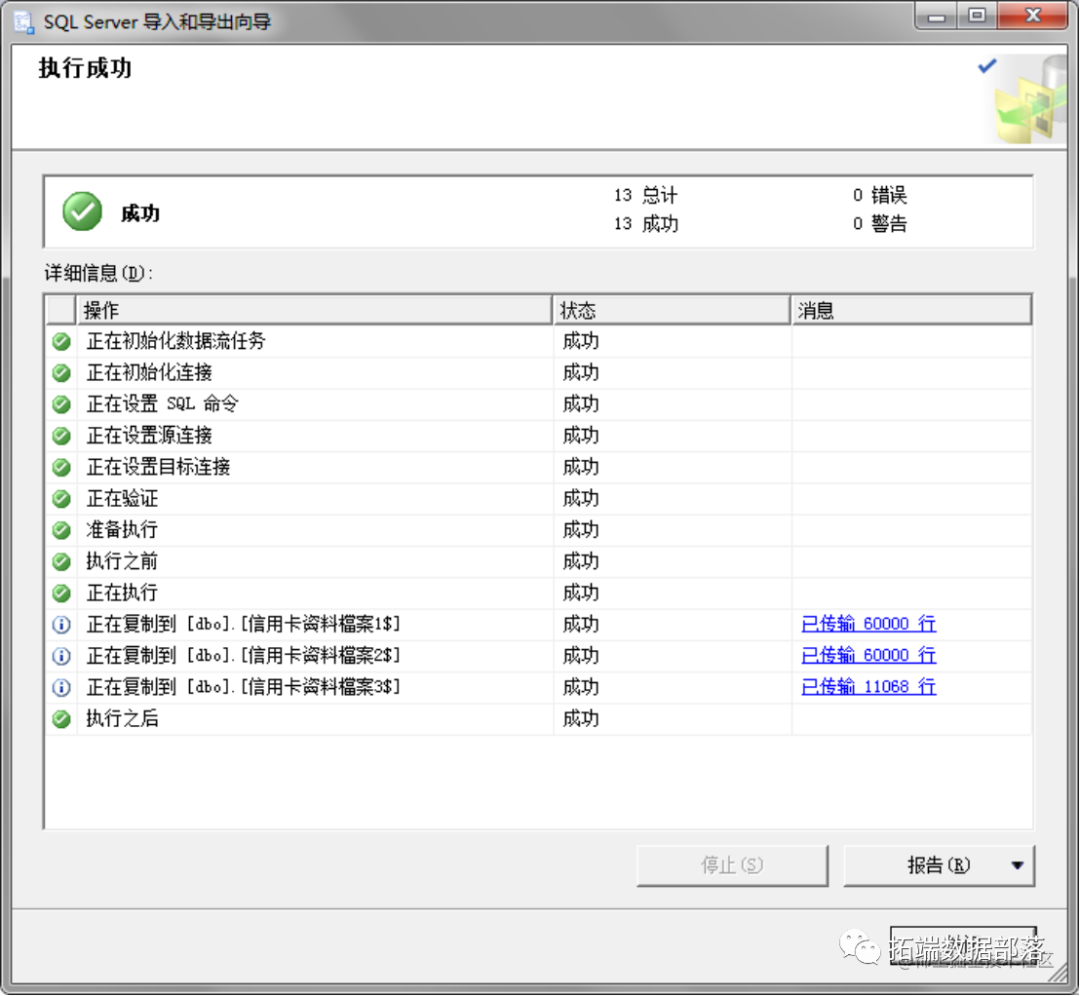
导入数据库
数据导入数据库中。
数据挖掘
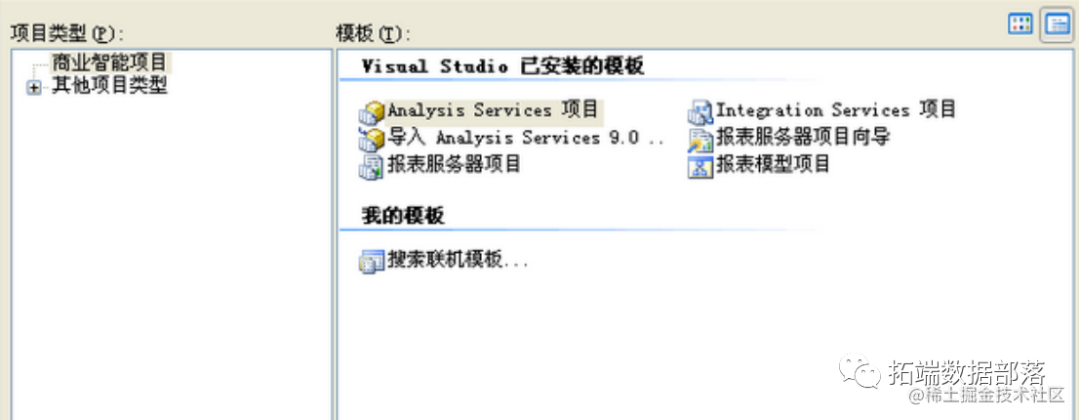
(1) 打开visual studio ,新建项目,选择商业智能项目,analysis services项目
(2) 在解决方案资源管理器中,右键单击数据源,选择新建数据源
(3)数据源名称保持默认,完成
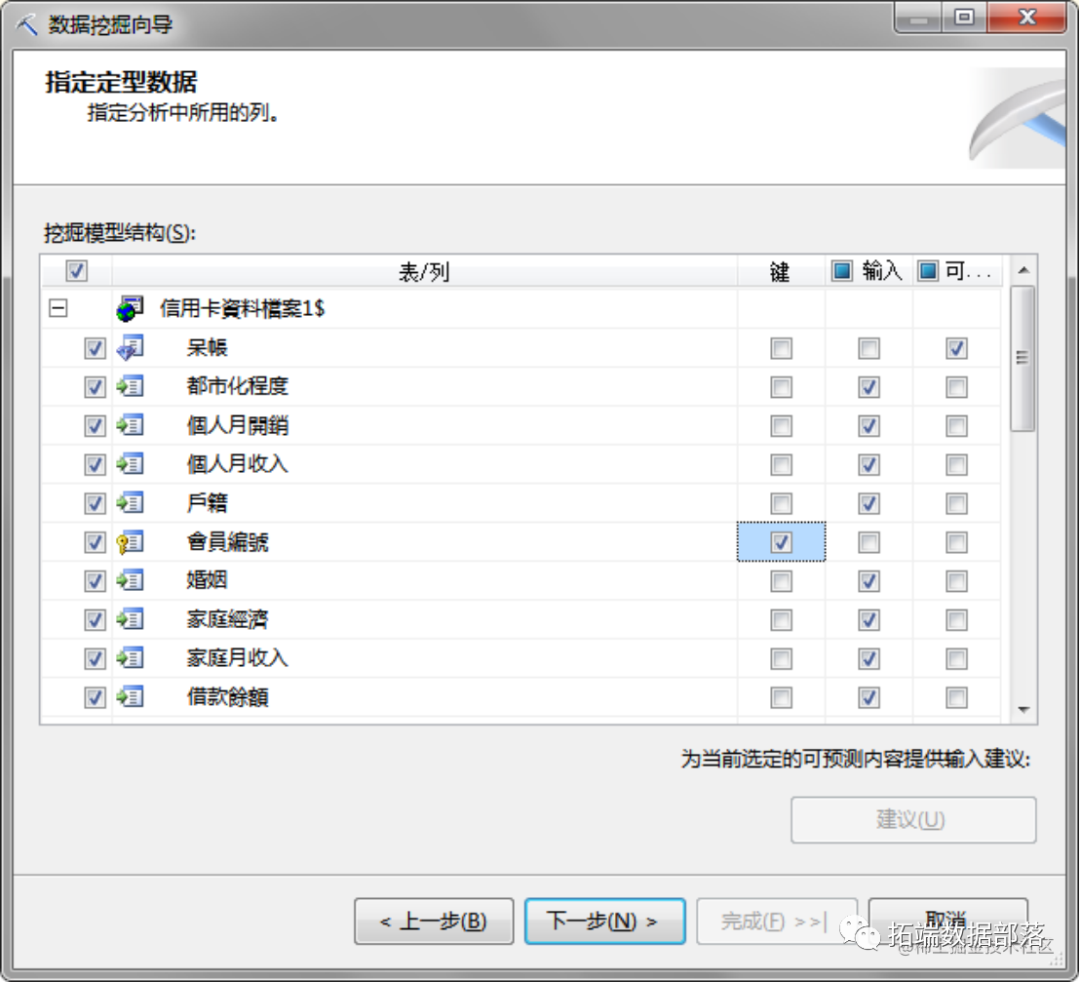
选择聚类,继续下一步
相关视频
关闭处理窗口后,就可在挖掘模型查看器看到系统经过分析得出的结果和文件:
从聚类结果可以看到,聚类将所有用户分成了10个信用级别。
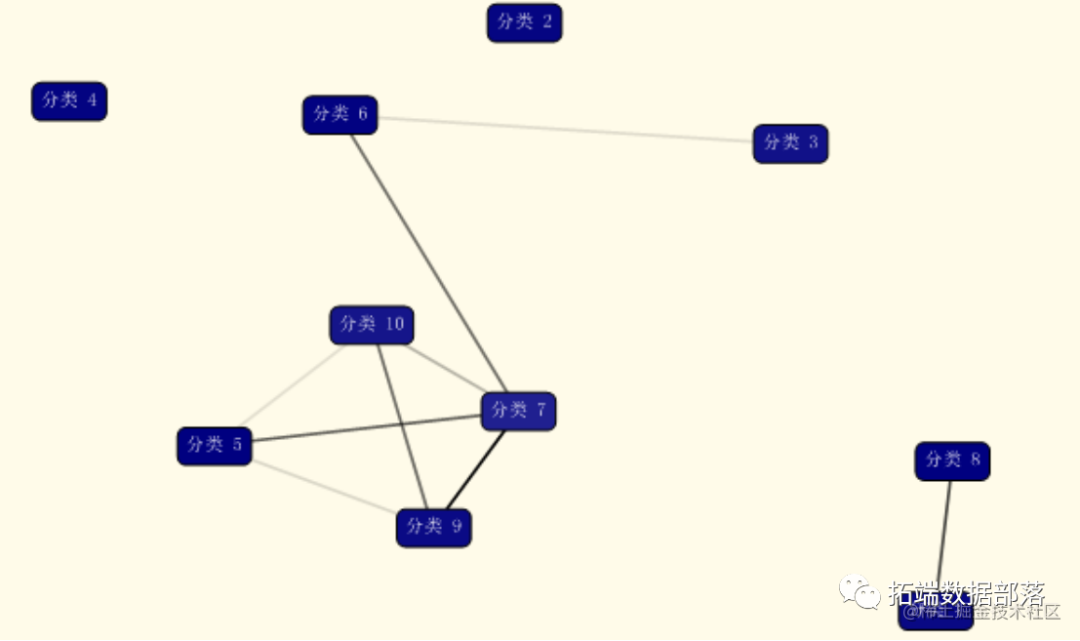
从不同类别的依赖图可以看到,类别10、7、9、5之间具有较强的相关关系。说明这几个类别中的信用级别是类似的。下面可以具体看下每个类别中的各个属性的分布的比例。
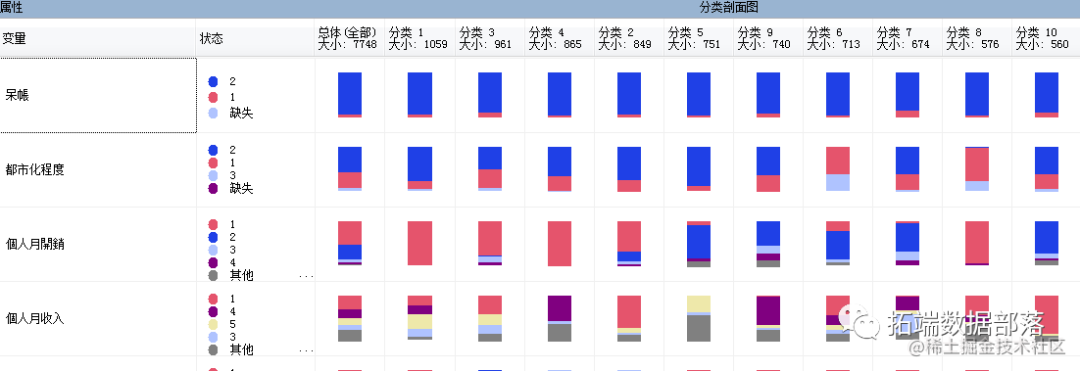
从上图可以看到不同类别的呆账比例是不同的。
从结果来看,相对来说,第7、10类别的呆账比例最小的,其他几个类别中呆账比例较高,因此可以认为这些类别中的用户的信用级别较高。同时可以看到这些类别的其他信息,这类用户的月开销较低,大多在10000元以下。同时可以看到,这类用户大多是都是都市用户,较少的城镇用户,说明都市用户的信用等级相对城镇用户的信用等级较高。另一方面,可以看到呆账用户中 ,有大部分是高收入人群,而低收入用户的呆账比例反而较低,可以认为低收入用户的信用等级反而较高。

从每个类别的倾向程度来看,月开销较低的用户呆账比例较低。从另一方面来看,月收入较低的用户,倾向于是分类10的用户,也就是它们的信用等级较好。同时可以看到,户籍为都市的用户倾向于分类10的用户,而户籍为城镇的用户倾向于其他分类。说明都市用户的信用等级相对较高。同时,可以看到与收入越高的用户,更倾向于非10类别,因此,可以认为,收入越高的用户,越存在信用风险。

本文中分析的数据分享到会员群,扫描下面二维码即可加群!

点击文末“阅读原文”
获取全文完整代码数据资料。
本文选自《SQL Server聚类数据挖掘信用卡客户可视化分析》。
点击标题查阅往期内容



