




全文下载链接:http://tecdat.cn/?p=3200
本文在数据集上展示了如何使用dendextend R软件包来增强Hierarchical Cluster Analysis(更好的可视化和灵敏度分析)。
相关视频
背景
鸢尾花数据集
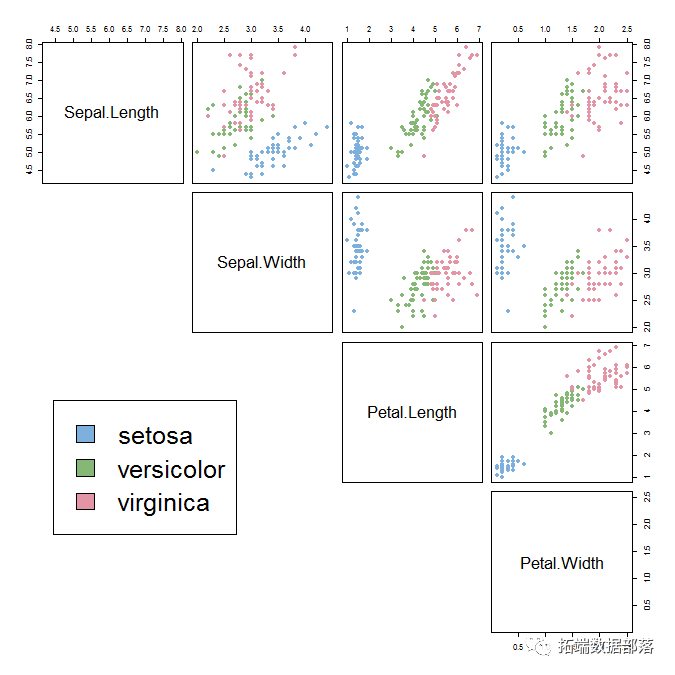
我们可以看到,Setosa物种与Versicolor和Virginica明显不同(它们具有较低的花瓣长度和宽度)。但是,基于对萼片和花瓣宽度/长度的测量,不易将Versicolor和Virginica分开。
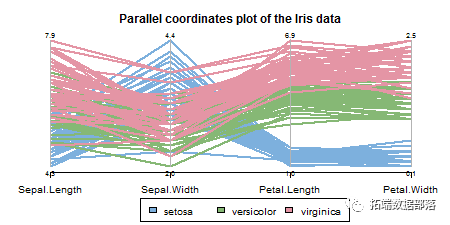
通过查看数据的平行坐标图可以得出同样的结论:
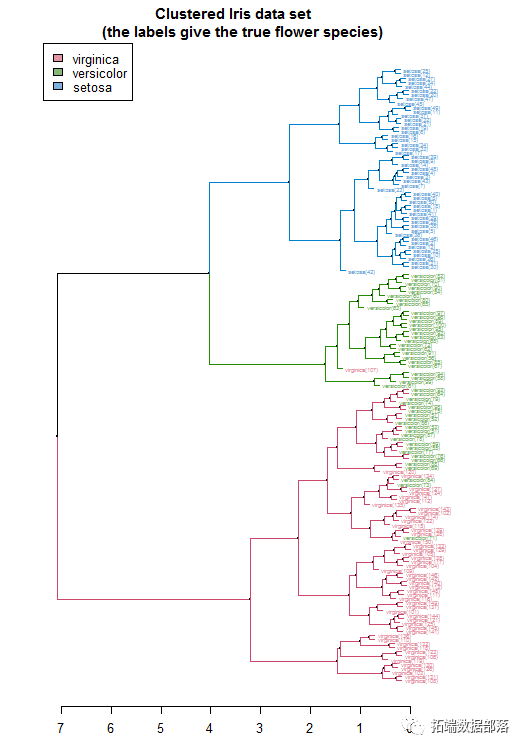
我们可以通过将对象转化为树状图并对对象进行一些调整来可视化运行它的结果
点击标题查阅往期内容


左右滑动查看更多
相同的可以在圆形布局中呈现:
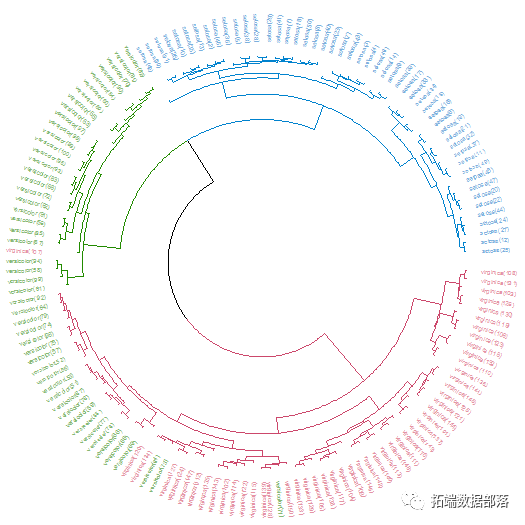
这些可视化很容易证明分层聚类的分离对于“Setosa”物种来说是非常好的,但是在将许多“Versicolor”物种标记为“Virginica”时未能实现。
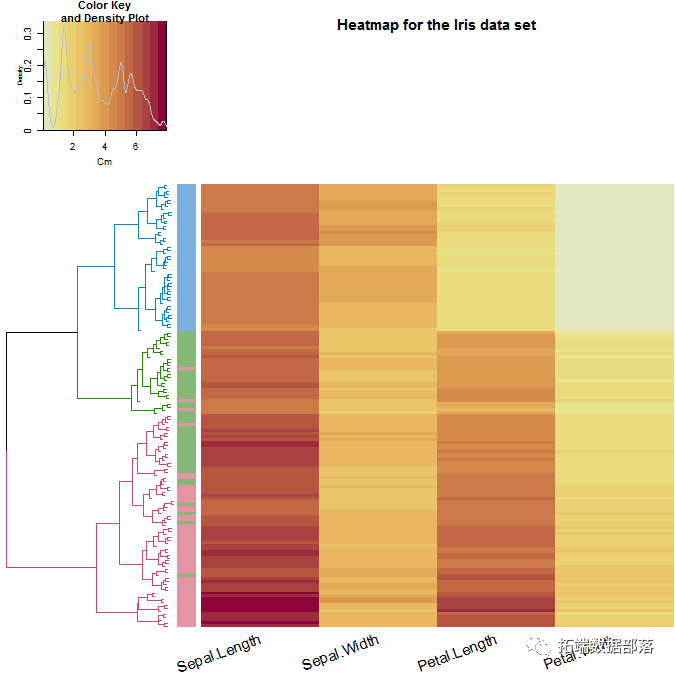
我们也可以使用热图探索数据。
在热图中,我们还可以看到Setosa物种的花瓣值如何(浅黄色),但很难看出其他两种物种之间的明显区别。
各种聚类算法之间的相似/不同
为了进行这种分析,我们将创建所有8个hclust对象,并将它们链接在一起成为一个dendlist对象(顾名思义,它可以将一组树状图组合在一起用于进一步分析)。
接下来,我们可以看看每个聚类结果之间的同源相关性cor.dendlist。(这可以使用corrplot包中的corrplot函数很好地绘制):
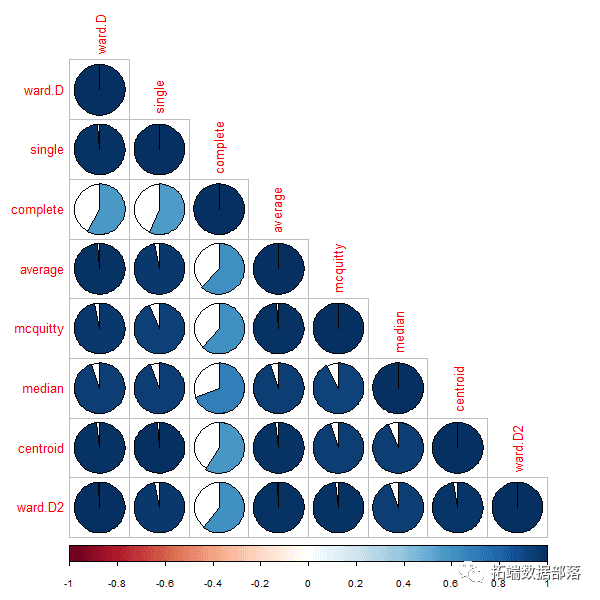
从上图中我们可以很容易地看到,除了完整的方法(默认方法in hclust),大多数聚类方法的结果非常相似,其结果相关度大约为0.6。
默认的同源相关使用皮尔逊的度量,但如果我们使用spearman的相关系数呢?
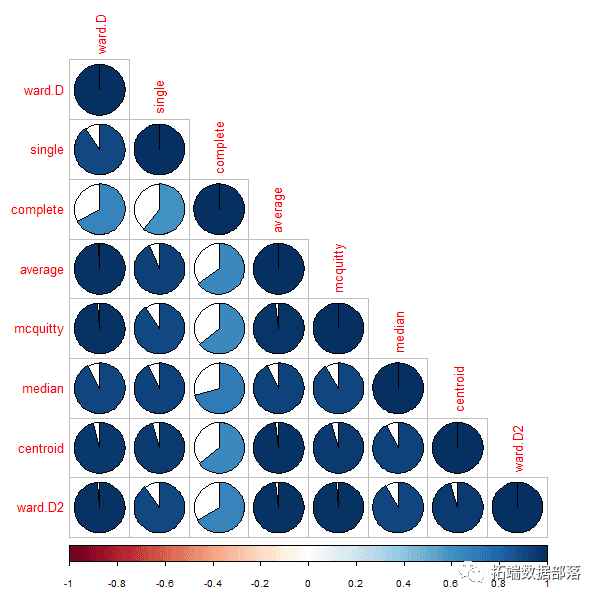
我们可以看到,相关性不是很强,表明一个行为依赖于彼此距离很远的一些项目,这些项目对皮尔森相关性的影响相关性更大。

点击文末“阅读原文”
获取全文完整代码数据资料。
本文选自《R语言鸢尾花iris数据集的层次聚类分析》。
点击标题查阅往期内容



