




问题描述
情况是这样的,有一套测试数据库所在的主机在最近几个月,每个月都会重启一至两次,由于数据库配置了开机自启动,且每次重启时间都比较短暂,便没有得到重视。最近由于测试人员的反馈,每当主机重启后呢会导致大片的测试应用由于断连导致无法使用,每次都需要重启应用才会好。那么我们就需要介入认真排查一下问题所在了,恰巧最近一次的重启时间为 11 月 10 日 18:29 左右,需要针对此问题分析 os 重启原因。
问题现象
测试数据库所在的主机每个月都会重启一至两次,主机重启时数据库 alert 没有任何日志,操作系统日志没有异常信息,监控平台也是到每次重启前就无法获取到数据了,由于操作系统层参数配置,每次宕机都会生成 core dump。
cat /etc/sysctl.conf | grep core
kernel.core_pattern = /home/backup/crash/core-%e-%u-%p-%s-%t
问题分析
AWR 报告分析
因为数据库因 os 重启而重启了,所以跨宕机时间点的 AWR 报告无法采集,只能采集宕机前的 AWR 报告,即 11 月 10 日 17:00—18:00,从这个时间段 AWR 报告来看,数据库负载不算太高,且数据库各指标也都比较正常,因为这个 AWR 报告距离宕机时间还有半个小时,所以也无法准确体现宕机时间点的数据库状态。
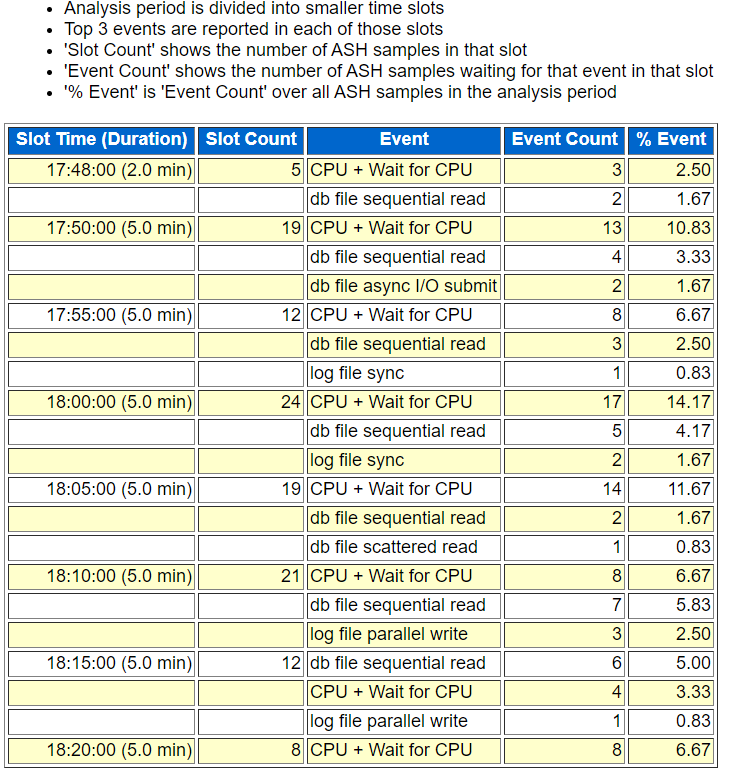
ASH 报告分析
通过收集到的 ASH 信息,当时数据库基本上是忙于 CPU 的调度与等待,“CPU + Wait for CPU” 等待事件比较多,但想要查看进一步的信息就没有了。
数据库日志分析
宕机时间点附近 alert 日志、数据库监听日志均没有异常信息打印。
OSW 日志分析
OSWatcher 使用简介
OSW 是用于采集 OS 性能指标的工具,调用 OS 的命令,对 OS 资源的占用可以忽略不计。
OSW 包含两个组件:
oswbb : 一组 shell 脚本,采集 OS 的性能指标数据。
oswbba : java 工具,分析 oswbb 采集的数据,提供一些建议,根据采集的数据绘制 CPU,内存,网络,I/O 的曲线图。
因为在上一次宕机也就是 11 月 2 日之后我部署了 OSW,可以看看宕机前的几分钟 OSW 抓取到的数据,以此数据来分析宕机前 OS 状态。
[root@oracle19c ~]# ps -ef | grep osw
root 20337 15300 0 21:21 pts/1 00:00:00 grep --color=auto osw
root 27118 1 1 Nov2 ? 10:14:05 /bin/sh /u01/soft/osw/oswbb/OSWatcher.sh 15 168 NONE /u01/soft/osw/oswbb/archive
root 28351 27118 0 Nov2 ? 00:05:16 /bin/sh ./OSWatcherFM.sh 168 /u01/soft/osw/oswbb/archive

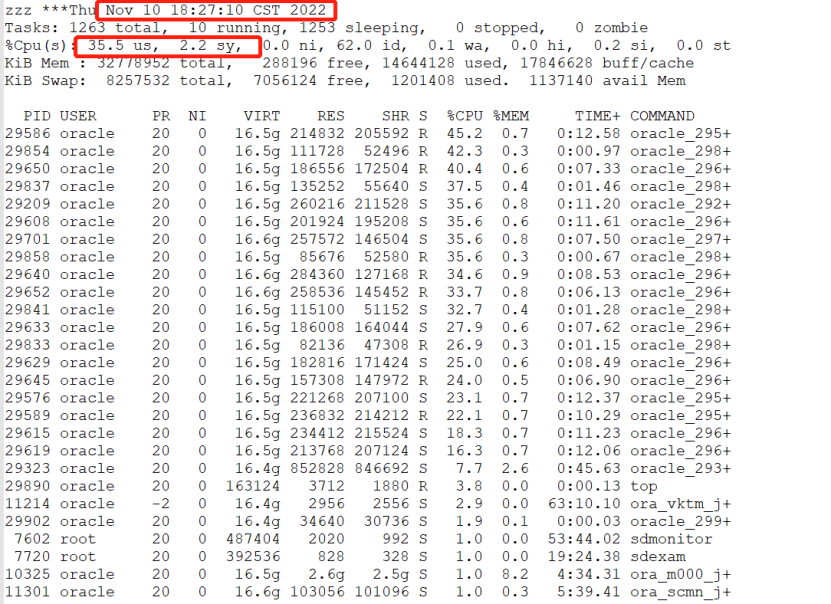
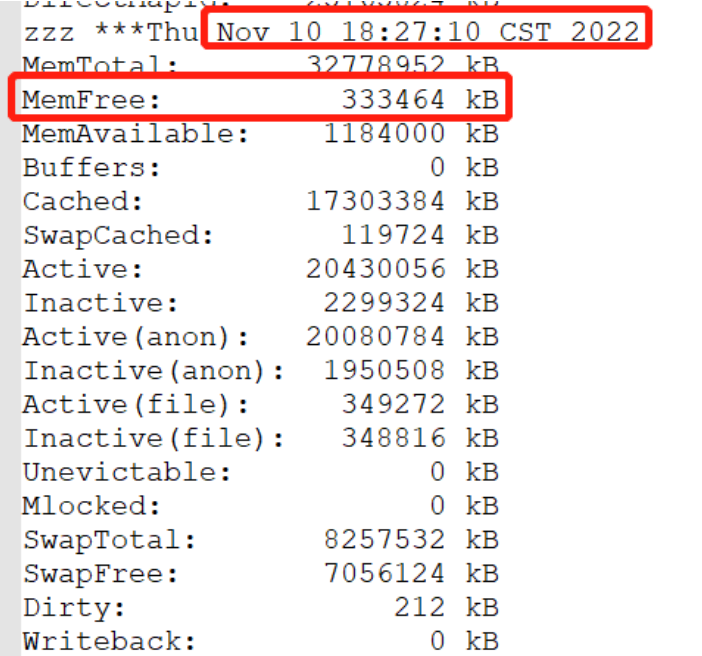
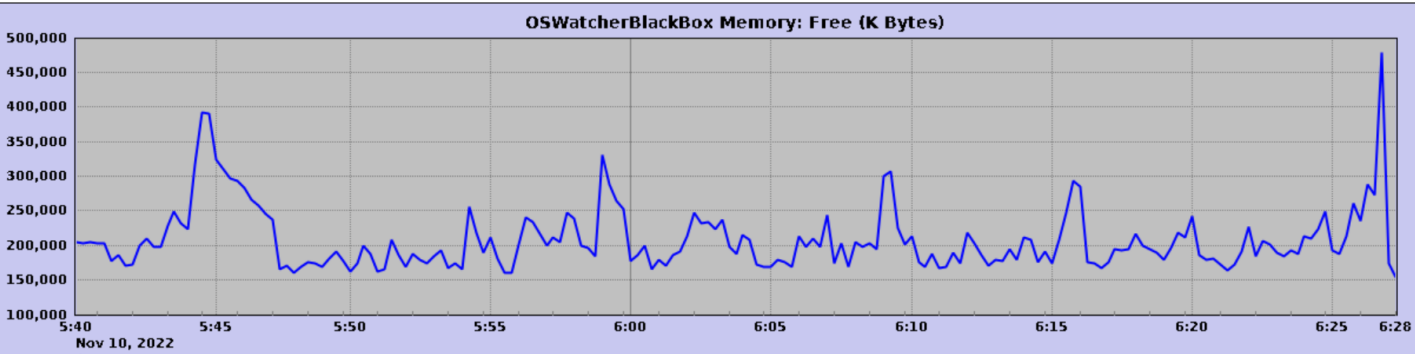
从宕机前收集到的 OSW 数据来看,IO 和 CPU 的使用率是比较正常的,但 free memory 只有 300M 多了,初步判断可能和操作系统内存有关。
收集特定时间段的 OSW 数据
查看 OSW 的数据存储位置
ps -ef | grep OSW
收集指定时间段的日志,例如:
cd /u01/soft/osw/oswbb/archive
find . -name "*19.02.18.0[5-9]00.dat*" -o -name "*19.02.18.1[0-2]00.dat*"| xargs tar zcvf osw.tar.gz
使用 oswbba 分析 OSW
注意要打开图形化
- 分析 archive 目录下的所有 OSW 数据采集文件,并生成 HTML 报告。
java -jar oswbba.jar -i xx -D
- 指定时间段分析 archive 目录下的 OSW 数据采集文件,并生成 HTML 报告。
java -jar oswbba.jar -i xx -b Dec 17 13:00:00 2021 -e Dec 17 14:00:00 2021 -D
oracle19c:/home/oracle(test)$ history | grep oswbba.jar
706 2022-11-16 10:15:53 java -jar oswbba.jar -i /u01/soft/osw/oswbb/archive -b Nov 10 17:40:00 2022 -e Nov 10 18:30:00 2022 -D
721 2022-11-16 10:20:28 java -jar oswbba.jar -i /u01/soft/osw/oswbb/archive -b Nov 10 17:40:00 2022 -e Nov 10 18:30:00 2022 -D
723 2022-11-16 10:21:00 java -jar oswbba.jar -i /u01/soft/osw/oswbb/archive -b Nov 10 17:40:00 2022 -e Nov 10 18:30:00 2022 -D
810 2022-11-16 10:07:34 java -jar oswbba.jar -i /u01/soft/osw/oswbb/archive -b Nov 10 17:40:00 2022 -e Nov 10 18:30:00 2022 -D
811 2022-11-16 10:16:55 java -jar oswbba.jar -i /u01/soft/osw/oswbb/archive -b Nov 10 17:40:00 2022 -e Nov 10 18:30:00 2022 -D Memory_BAK
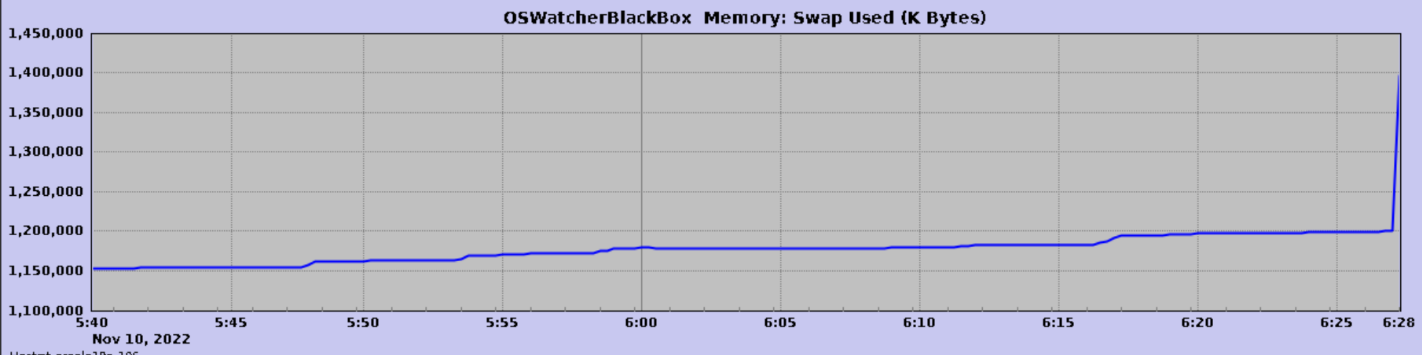
打开图形化界面然后执行 oswbba.jar 便会生成类似于下面的 gif 图形,通过此趋势图可以看到 18:28 分左右内存和 Swap 出现峰值,也说明当时内存使用过多了。
cd /u01/soft/osw/oswbb
java -jar oswbba.jar -i /u01/soft/osw/oswbb/archive -b Nov 10 17:40:00 2022 -e Nov 10 18:30:00 2022 -D
参考文档:
OSWatcher (Includes: [Video]) (文档 ID 301137.1)
OS Watcher User’s Guide (文档 ID 1531223.1)
OSWatcher Analyzer User Guide (文档 ID 461053.1)
操作系统日志分析
宕机时间点附近 /var/log/messages 中也没有异常信息打印。
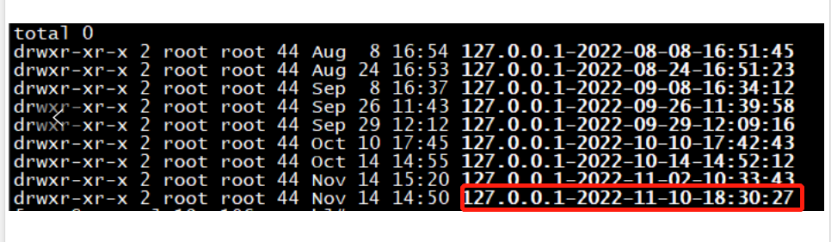
那么基于上面的这些信息基本上排查不到什么有用的信息了,唯一能有突破的就是前面说的每次重启都生成的 core 文件了。我们知道在 Linux 系统中,如果进程崩溃了,系统内核会捕获到进程崩溃信息,然后将进程的 coredump 信息写入到文件中,这个文件名默认是 core 。存储位置与对应的可执行程序在同一目录下,文件名是core,大家可以通过下面的命令看到 core 文件的存在位置,如下我的配置是在 /home/backup/crash/ 目录下。
cat /proc/sys/kernel/core_pattern
/home/backup/crash/core-%e-%u-%p-%s-%t
core 文件需要 gdb 命令打开分析,这里就不班门弄斧了,专业的事交给专业的人去干,通过系统工程师的分析,OS 所在主机的安全狗 watchdog 进程夯 120 秒导致主机重启。这里就要说明下为何夯 120 秒主机就会重启,因为配置了操作系统参数 kernel.hung_task_panic = 1 导致主机重启了。
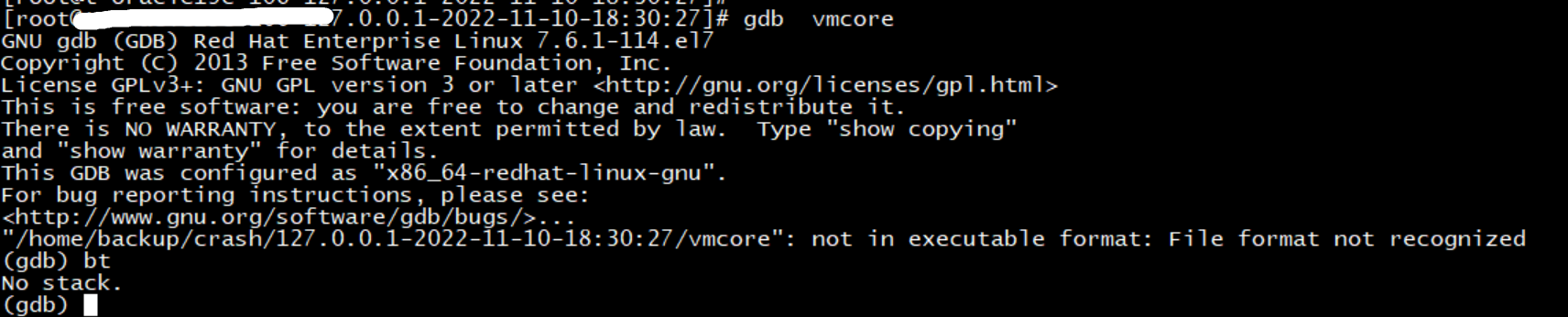
# gdb -c vmcore
GNU gdb (GDB) Red Hat Enterprise Linux 7.6.1-114.el7
Copyright (C) 2013 Free Software Foundation, Inc.
License GPLv3+: GNU GPL version 3 or later <http://gnu.org/licenses/gpl.html>
This is free software: you are free to change and redistribute it.
There is NO WARRANTY, to the extent permitted by law. Type "show copying"
and "show warranty" for details.
This GDB was configured as "x86_64-redhat-linux-gnu".
For bug reporting instructions, please see:
<http://www.gnu.org/software/gdb/bugs/>.
"/home/backup/crash/127.0.0.1-2022-11-10-18:30:27/vmcore" is not a core dump: File format not recognized
(gdb)
kernel.hung_task_panic
操作系统工程师配置了这个内核参数 kernel.hung_task_panic=1 ,意思是如果内核有进程处于 D 状态在 120s 内都没有被调度,则默认会触发 panic,说的通俗易懂点就是配置这个参数时当主机有进程夯 120 秒时就会触发主机重启机制。那么问题就很明白了,每次的重启都是由于有进程夯了 120 秒触发了这个参数的设置导致主机重启。如果要关闭 hung task panic,则可以设置内核参数 kernel.hung_task_panic=0 进行关闭。所以这里呢我也就将这个参数注释掉,默认值就是 0。
[root@oracle19c ~]# sysctl -a | grep hung
kernel.hung_task_check_count = 4194304 // khungtaskd 一次检测的最大线程数
kernel.hung_task_panic = 0 //是否将 hung task 检测结果转为panic
kernel.hung_task_timeout_secs = 120 //khungtaskd 两次检测的最大 timeout时间
kernel.hung_task_warnings = 10 //hung task警告信息的发送次数。
[root@oracle19c ~]# cat /etc/sysctl.conf | grep task
#kernel.hung_task_panic = 1
通过 crash 工具分析 core dump 可以看到宕机时的 os 内存使用已经达到了 98%,并且 swap 也已经使用了 68%。

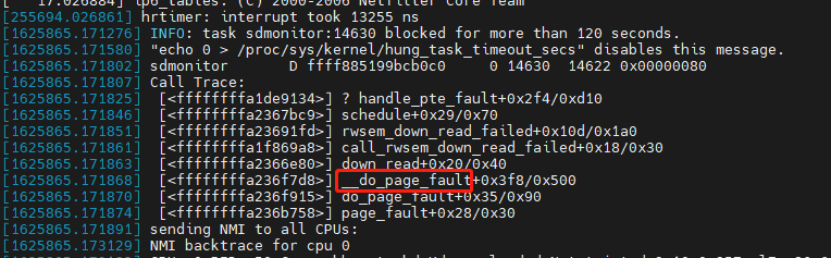
由此基本上可以看到是由于内存耗尽导致重启了。然后进一步检查数据库内存参数配置,目前此虚拟机的物理内存为 32G,sga 16G,pga 4G ,没有配置内存大页,数据库参数 processes 设置为 2000,pga_aggregate_limit 没有值。那么在这种配置下数据库连接数比较多的情况下,每个数据库连接占用 3-5m 内存多达 1000 多个链接的情况下在出现几个排序的大 SQL,很容易把内存占完。
问题总结及建议
通过以上的分析,基本可以确定,数据库主机宕机的原因是内存不足导致,一来操作系统内存 32G 对数据库而言没有限制,二来数据库存在大量连接会话,大量低效 SQL 占用大量内存空间导致内存资源不足。
建议:
1、增加主机物理内存,从现在的 32G,增加至 64G;
2、调整 SGA 和 PGA 大小并设置 pga_aggregate_limit;
3、开启内存大页;
4、在操作系统层面对数据库内存使用进行限制;
5、取消内核参数 kernel.hung_task_panic
后续处理步骤
先调整数据库 SGA 和 PGA 大小。参数 PGA_AGGREGATE_TARGET 起到的是目标的作用,而非限制实际 PGA 大小,参数 PGA_AGGREGATE_LIMIT 是 12c 以后开始的新参数,可以对 PGA 的内存使用量作“硬性规定”。如果 PGA 超过了 PGA_AGGREGATE_LIMIT 值,那么 Oracle 内部按照以下顺序,中断或者终止使用了最多不可优化的 PGA 内存(the most untunable PGA)的会话或进程:
-
CKPT 进程会检查(每三秒检查一次)并停掉使用了最多不可优化 PGA 内存的会话调用;
-
如果 PGA 内存使用量仍超过 PGA_AGGREGATE_LIMIT,则 CKPT 进程会终止使用了最多不可优化 PGA 内存的会话和进程.
在 Oracle 12.1 的版本中会选择以下三种情况中最大的值作为PGA_AGGREGATE_LIMIT 的值:
1)2 GB
2)PGA_AGGREGATE_TARGET 值的 2 倍
3)参数 PROCESSES 的值 * 3MB
另外需要注意的是:该参数不会超过物理内存大小减去总 SGA 大小的 120%。
在 18c 以后的版本中,PGA_AGGREGATE_LIMIT 的值计算方法大概是如下的公式:
PGA_AGGREGATE_LIMIT = (原始 PGA_AGGREGATE_LIMIT 值) + ((最大连接进程数) * 4M)
所以本次调整虚拟机内存为 64G 后,设置 SGA、PGA 参数如下:
alter system set sga_max_size=25G scope=spfile;
alter system set sga_target=25G scope=spfile;
alter system set pga_aggregate_target=8G scope=spfile;
alter system set pga_aggregate_limit=16G scope=spfile;
然后需要开启内存大页
vm.min_free_kbytes 这个参数可以控制预留给虚拟机多少内存,设置的太小会出现死锁,设置的过大会出现 OOM。为了满足 PF_MEMALLOC,需要一些最小的内存分配;如果您将其设置为低于1024KB,系统将会变得微妙地破碎,并且在高负载下容易死锁,设置过高会使你的机器立即 OOM;通常经验值是设置物理内存的 2%-5% 以内,单位是 KB,通常情况下 32G 内存配置 2G,64G 内存配置 5G 即 5242880 128G 内存 10G 即可。
参考链接:https://www.kernel.org/doc/Documentation/sysctl/vm.txt
内存大页,大内存页,标准大页等均是同一个东西,之前写的《Linux 透明大页 THP 和标准大页 HP》一文有过详细介绍,这里就不在介绍了。
vim /etc/sysctl.d/97-oracle-database-sysctl.conf
vm.min_free_kbytes = 5242880
vm.nr_hugepages = 12804
sysctl --system
memlock 参数指定用户可以锁定其地址空间的内存量。在 /etc/security/limits.conf 文件中添加 memlock 的限制,一般情况下该值略微小于实际物理内存的大小(单位为 KB),我的物理内存是 64GB,可以设置为如下:
oracle soft memlock 60397977
oracle hard memlock 60397977

通过以上设置后就可以关机修改内存至 64G 然后开机检查数据库状态了。
[root@oracle19c ~]# tail -9 /etc/security/limits.conf
##FOR Oracle BEGIN
oracle soft nofile 10240
oracle soft nproc 20470
oracle soft stack 10240
oracle hard nofile 65536
oracle hard nproc 16384
oracle hard stack 32768
oracle soft memlock 60397977
oracle hard memlock 60397977
[root@oracle19c ~]# grep -i page /proc/meminfo
AnonPages: 6405828 kB
PageTables: 561288 kB
AnonHugePages: 0 kB
HugePages_Total: 12804
HugePages_Free: 11
HugePages_Rsvd: 7
HugePages_Surp: 0
Hugepagesize: 2048 kB
[root@oracle19c ~]# free -m
total used free shared buff/cache available
Mem: 64264 32915 9735 1399 21613 14964
Swap: 8063 50 8013
[root@oracle19c ~]# uptime
20:47:58 up 33 days, 8:14, 1 user, load average: 3.93, 3.81, 3.90
经过以上设置,观察了一个多月的时间没有出现过重启或者资源不足的情况,在此简单记录一下排查过程以及用到的知识点,希望以后遇到类似的问题可以参考参考,如果小伙伴们有不同意见或建议,欢迎一起交流。
全文完,希望可以帮到正在阅读的你,如果觉得此文对你有帮助,可以分享给你身边的朋友,同事,你关心谁就分享给谁,一起学习共同进步~~~
欢迎关注我的公众号【JiekeXu DBA之路】,第一时间一起学习新知识!
————————————————————————————
公众号:JiekeXu DBA之路
CSDN :https://blog.csdn.net/JiekeXu
墨天轮:https://www.modb.pro/u/4347
腾讯云:https://cloud.tencent.com/developer/user/5645107
————————————————————————————

