




一、RDD设计背景
在实际应用中,存在许多迭代式算法(比如机器学习、图算法等)和交互式数据挖掘工具,这些应用场景的共同之处是,不同计算阶段之间会重用中间结果,即一个阶段的输出结果会作为下一个阶段的输入。但是,目前的MapReduce框架都是把中间结果写入到HDFS中,带来了大量的数据复制、磁盘IO和序列化开销。虽然,类似Pregel等图计算框架也是将结果保存在内存当中,但是,这些框架只能支持一些特定的计算模式,并没有提供一种通用的数据抽象。RDD就是为了满足这种需求而出现的,它提供了一个抽象的数据架构,我们不必担心底层数据的分布式特性,只需将具体的应用逻辑表达为一系列转换处理,不同RDD之间的转换操作形成依赖关系,可以实现管道化,从而避免了中间结果的存储,大大降低了数据复制、磁盘IO和序列化开销。
二、RDD概念
一个RDD就是一个分布式对象集合,本质上是一个只读的分区记录集合,每个RDD可以分成多个分区,每个分区就是一个数据集片段,并且一个RDD的不同分区可以被保存到集群中不同的节点上,从而可以在集群中的不同节点上进行并行计算。RDD提供了一种高度受限的共享内存模型,即RDD是只读的记录分区的集合,不能直接修改,只能基于稳定的物理存储中的数据集来创建RDD,或者通过在其他RDD上执行确定的转换操作(如map、join和groupBy)而创建得到新的RDD。RDD提供了一组丰富的操作以支持常见的数据运算,分为“行动”(Action)和“转换”(Transformation)两种类型,前者用于执行计算并指定输出的形式,后者指定RDD之间的相互依赖关系。两类操作的主要区别是,转换操作(比如map、filter、groupBy、join等)接受RDD并返回RDD,而行动操作(比如count、collect等)接受RDD但是返回非RDD(即输出一个值或结果)。RDD提供的转换接口都非常简单,都是类似map、filter、groupBy、join等粗粒度的数据转换操作,而不是针对某个数据项的细粒度修改。因此,RDD比较适合对于数据集中元素执行相同操作的批处理式应用,而不适合用于需要异步、细粒度状态的应用,比如Web应用系统、增量式的网页爬虫等。正因为这样,这种粗粒度转换接口设计,会使人直觉上认为RDD的功能很受限、不够强大。但是,实际上RDD已经被实践证明可以很好地应用于许多并行计算应用中,可以具备很多现有计算框架(比如MapReduce、SQL、Pregel等)的表达能力,并且可以应用于这些框架处理不了的交互式数据挖掘应用。
Spark用Scala语言实现了RDD的API,架构师可以通过调用API实现对RDD的各种操作。RDD典型的执行过程如下:
1. RDD读入外部数据源(或者内存中的集合)进行创建;
2. RDD经过一系列的“转换”操作,每一次都会产生不同的RDD,供给下一个“转换”使用;
3. 最后一个RDD经“行动”操作进行处理,并输出到外部数据源(或者变成Scala集合或标量)。
需要说明的是,RDD采用了惰性调用,即在RDD的执行过程中,真正的计算发生在RDD的“行动”操作,对于“行动”之前的所有“转换”操作,Spark只是记录下“转换”操作应用的一些基础数据集以及RDD生成的轨迹,即相互之间的依赖关系,而不会触发真正的计算。
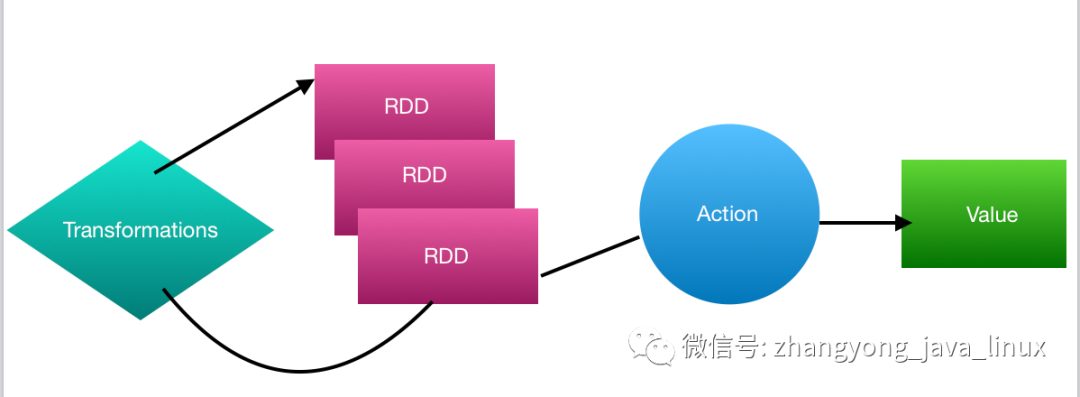
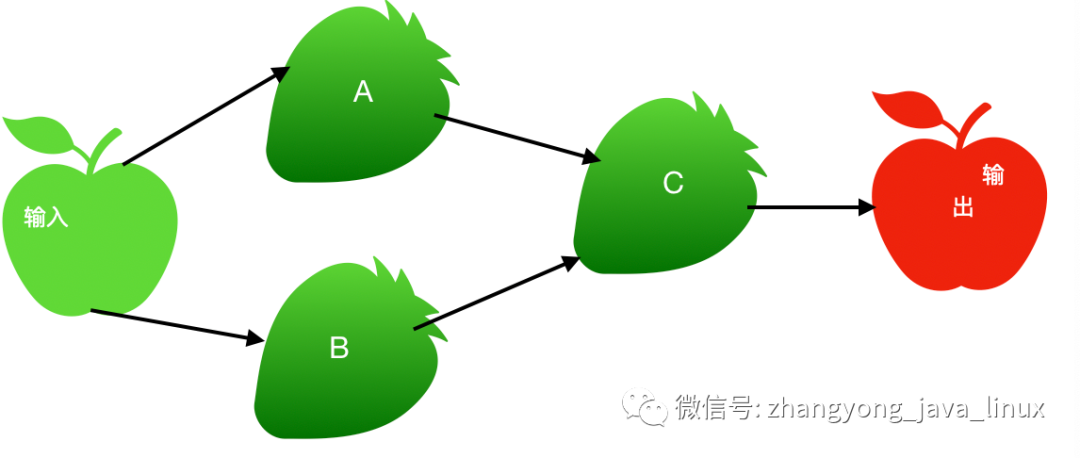
从输入中逻辑上生成A和B两个RDD,经过一系列“转换”操作,逻辑上生成了C(也是一个RDD),之所以说是逻辑上,是因为这时候计算并没有发生,Spark只是记录了RDD之间的生成和依赖关系。当C要进行输出时,也就是当C进行“行动”操作的时候,Spark才会根据RDD的依赖关系生成DAG,并从起点开始真正的计算。
三、RDD特性
总体而言,Spark采用RDD
以后能够实现高效计算的原因主要在于:
1、高效的容错性。
传统方式:现在的分布式共享内存、键值存储、内存数据库等,为了实现容错,必须在集群节点之间进行数据复制或者记录日志,也就是在节点之间会发生大量的数据传输,这对于数据密集型应用而言会带来很大的开销。
RDD
方式:在RDD
的设计中,数据只读,不可修改,如果要修改数据,必须从父RDD
转换到子RDD
,由此在不同的RDD
之间建立了血缘关系。所以,RDD
是一种天生具有具有容错机制的特殊集合,不需要通过数据冗余的方式(比如检查点)实现容错,而只需要通过RDD
父子依赖(血缘)关系重算计算得到丢失的分区来实现容错,无须回滚整个系统,这样就避免了数据复制的高开销,而且重算过程可以在不同节点并行进行,实现了高效的容错。此外:
RDD
提供的转换操作都是一些粗粒度的操作(比如map、filter和join),RDD依
赖关系只需要记录这种粗粒度的转换操作,而不需要记录具体的数据和各种细粒度操作的日志,这就大大降低了数据密集型应用中容错开销。2、中间结果持久化到内存,数据在内存中的多个
RDD
操作之间进行传递,不需要“落地”到磁盘上,避免了不必要的读写磁盘开销。3、存放的数据可以是Java对象,避免了不必要的对象序列化和反序列化。
四、RDD之间的依赖关系
RDD
是易转换、已操作的,这意味着用户可以从已有的RDD
转换出新的RDD
转换出新的RDD
。新、旧RDD
之间必定存在这某种联系,这种联系称为RDD
依赖关系。
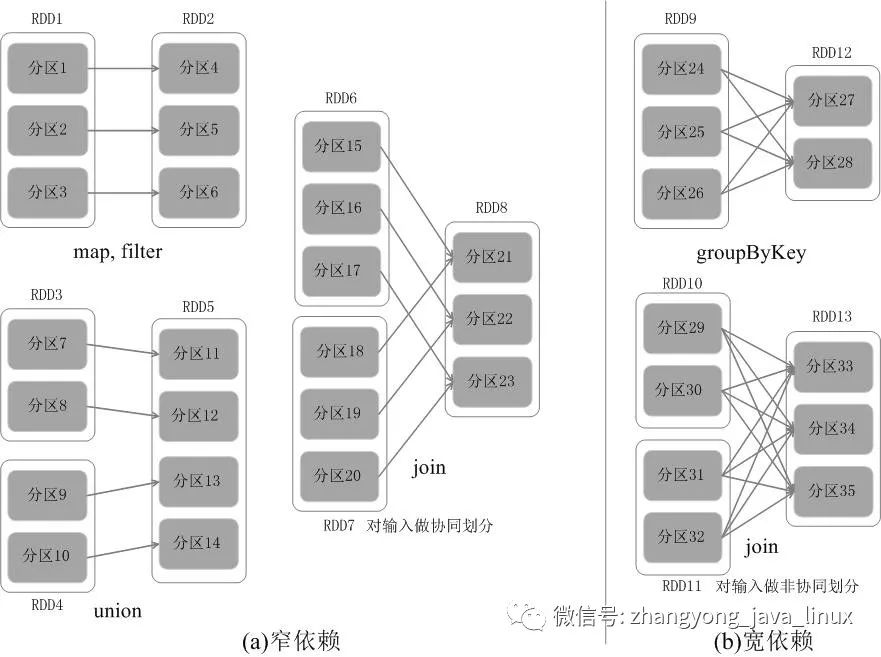
窄依赖:
父RDD
的每个子分区最后被其子RDD
的一个分区所依赖,也就是说子RDD
的每个分区依赖于常数个父分区,子RDD
每个分区的生成与父RDD
的数据规模无关。宽依赖:
父RDD
的每个分区被其子RDD
的多个分区所依赖,子RDD
每个分区的生成与父RDD
的数据规模相关。
五、Stage的划分
Spark通过分析各个RDD的依赖关系生成了DAG
,再通过分析各个RDD
中的分区之间的依赖关系来决定如何划分Stage
,具体划分方法是:
在
DAG
中进行反向解析,遇到宽依赖就断开遇到窄依赖就把当前的
RDD
加入到Stage
中将窄依赖尽量划分在同一个
Stage
中,可以实现流水线计算
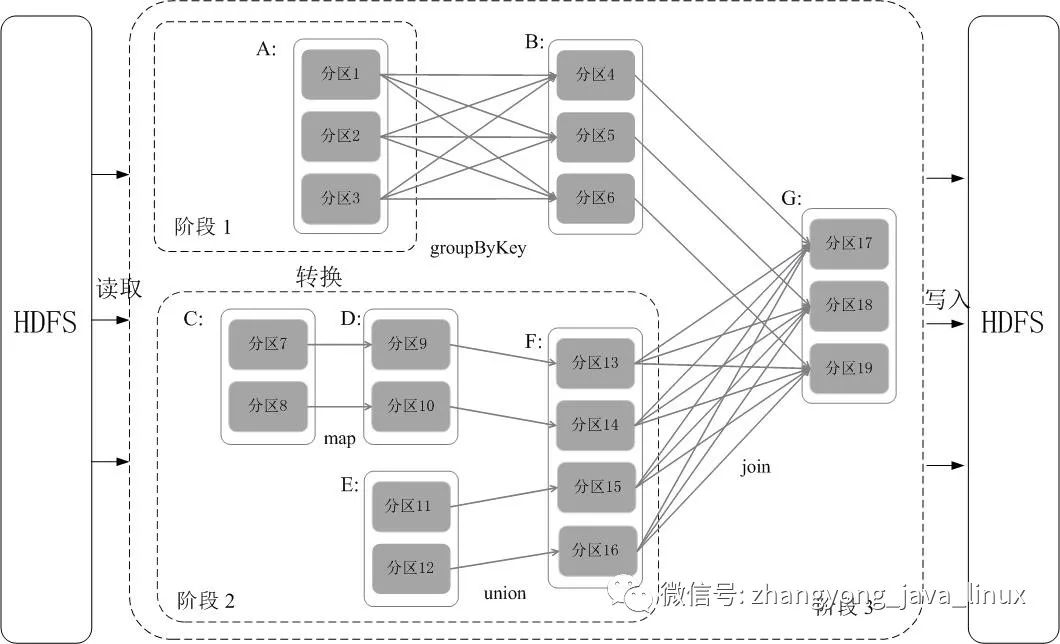
5.1流水线操作实例
分区7通过map
操作生成的分区9,可以不用等待分区8到分区10这个map
操作的计算结束,而是继续进行union
操作,得到分区13,这样流水线执行大大提高了计算的效率。RDD被分成三个Stage
,在Stage2
中,从map
到union
都是窄依赖,这两步操作可以形成一个流水线操作。
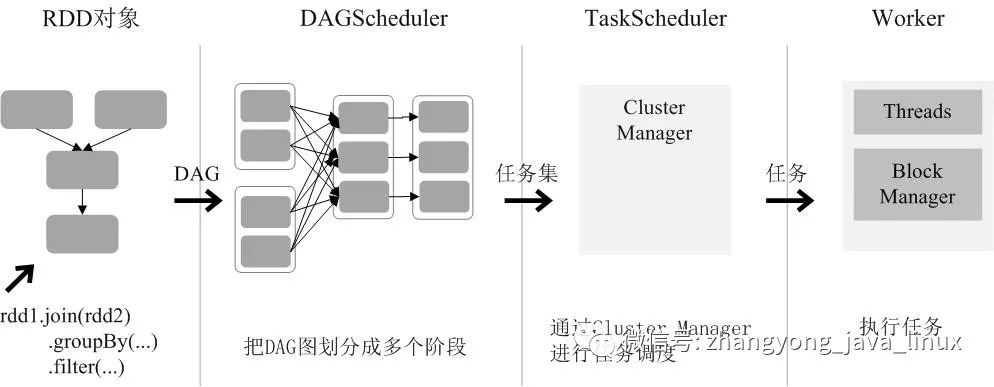
六、RDD运行过程
通过上述对RDD
概念、依赖关系和Stage
划分的介绍,结合之前介绍的Spark运行基本流程,再总结一下RDD
在Spark架构中的运行过程:
1、创建RDD对象;
2、
SparkContext
负责计算RDD
之间的依赖关系,构建DAG
;3、
DAGScheduler
负责把DAG
图分解成多个Stage
,每个Stage
中包含了多个Task
,每个Task
会被TaskScheduler
分发给各个WorkerNode
上的Executor
去执行。
package main.scala.com.web.zhangyong168.cn.spark.testimport java.util.Propertiesimport com.web.zhangyong168.cn.spark.util.{PropertiesUtils, SparkTool}import org.apache.spark.rdd.RDDimport org.apache.spark.sql.types._import org.apache.spark.sql.{Column, DataFrame, Row}import org.slf4j.{Logger, LoggerFactory}/** *** @description Spark中DataFrame转RDD在转新的DataFrame* @author 张勇* @version 0.0.1* @date 2020年08月15日下午20:23:39*/object SparkRddMethod {val log: Logger = LoggerFactory.getLogger(getClass)val spark = SparkTool.getSparkSession()spark.sql("show databases").show()val pro: Properties = PropertiesUtils.loadProps("jdbc.properties")val map = Map[String, String]("driver" -> pro.getProperty("mysql.driver"),"url" -> pro.getProperty("mysql.url"),"user" -> pro.getProperty("mysql.user"),"password" -> pro.getProperty("mysql.password"),"dbtable" -> "tb_address_district_copy")val df = spark.read.format("jdbc").options(map).loaddef main(args: Array[String]): Unit = {df.show()dataDf(df)}def dataDf(df:DataFrame): Unit ={log.info("========================打印将原来的df所有的类型转成String类型begin========================")val cols: Array[String] = df.columnsval colsd: Array[Column] = cols.map(f => df(f).cast(StringType))val df2: DataFrame = df.select(colsd: _*)df2.printSchema()log.info("========================打印将原来的df所有的类型转成String类型end========================")val dataRdd:RDD[Row]=df2.rdd.filter(r => r.getString(2)=="285").groupBy(r => r.getString(2)).flatMap(obj =>{val row:Iterable[Row]=obj._2var list:List[Row]=List()var r1:Row=nullrow.foreach(r =>{ //注意类型要跟遍历的df类型一致// val id=r.getLong(0)// log.info("打印数据id:"+id)// val district_name=r.getString(1)// log.info("打印数据district_name:"+district_name)// val city_id=r.getLong(2)// log.info("打印数据city_id:"+city_id)// val isdel=r.getInt(3)// log.info("打印数据isdel:"+isdel)// val intime=r.getTimestamp(4)// log.info("打印数据intime:"+intime)//test(id)r1=rlist=list.+:(r1)log.info("打印数据r:"+r)})log.info("打印数据list:"+list)list.distinct})log.info("打印类型:"+df.schema)df.printSchema()val schemaString="id,district_name,city_id,isdel,intime"val newDF=spark.createDataFrame(dataRdd,getSchema(schemaString))log.info("========================================================打印新集合的数据========================================================================")log.info("打印新数据总数:"+ newDF.count())newDF.filter("city_id='285' and id='10'").sort("id").show()}/*** 更改要创建的df里面每个字段的不同类型*/val schema:StructType = StructType(List(StructField("id", LongType, true),StructField("district_name", StringType, true),StructField("city_id", LongType, true),StructField("isdel", IntegerType, true),StructField("intime", TimestampType, true)))def test(id :Long): Unit ={println("打印id:"+id)}// 创建 StructType 来定义结构def getSchema(schemaString:String):StructType={val fields:Array[StructField] =schemaString.split(",").map(fileName => StructField(fileName,StringType,nullable = true))//转化为schemaStructType(fields)}
