




注意:我们已经意识到我们的 Databricks 结果存在几个问题,我们目前正在重新运行基准测试的这一部分。
在过去两年中,主要的云数据仓库继续进行渐进式改进,为客户提供更快的性能和更低的成本。与流行的看法相反,这些供应商不断提高效率,尽管对收入有短期影响,但仍能为客户节省资金[1]。由于主要供应商在性能方面几乎持平,因此客户在选择数据仓库时应关注用户体验。
Fivetran 是一种数据管道,可将来自应用程序、数据库和文件存储的数据同步到我们客户的数据仓库中。我们最常被问到的问题是,“我应该选择什么样的数据仓库?” 为了更好地回答这个问题,我们与Brooklyn Data Co.合作,比较了五个最受欢迎的数据仓库的速度和成本:
- Amazon Redshift
- Snowflake
- Google BigQuery
- Databricks
- Azure Synapse
基准都是关于做出选择的:我将使用什么样的数据?多少?什么样的查询?如何做出这些选择很重要:改变数据的形状或查询的结构,最快的仓库可能会变成最慢的。我们试图以代表典型Fivetran用户的方式做出这些选择,因此结果将对使用 Fivetran 的公司有用。
典型的 Fivetran 用户可能会将 Salesforce、JIRA、Marketo、Adwords 及其生产 Oracle 数据库同步到数据仓库中。这些数据源并没有那么大:一个典型的数据源将包含数十到数百 GB 的数据。它们很复杂:它们在规范化模式中包含数百个表,我们的客户编写复杂的 SQL 查询来汇总这些数据。
此基准测试的源代码可在https://github.com/fivetran/benchmark获得。
云数据仓库基准报告下载完整报告:https://go.fivetran.com/reports/cloud-data-warehouse-benchmark
我们查询了哪些数据?
我们生成了 1TB 规模的 TPC-DS [2]数据集。TPC-DS 在雪花模式中有 24 个表;这些表格代表一个虚构的零售商的网络、目录和商店销售。最大的事实表有 40 亿行[3]。
我们运行了哪些查询?
我们在 2022 年 5 月至 10 月运行了 99 个 TPC-DS 查询[4]。这些查询很复杂:它们有很多连接、聚合和子查询。我们只运行每个查询一次,以防止仓库缓存以前的结果。查询按顺序运行,一次一个,这与许多用户同时运行查询的典型实际用例不同。
我们如何配置仓库?
我们以 3 种配置运行每个仓库,以探索成本与性能的权衡。我们从我们在 2020 年基准测试中使用的相同配置(下面标记为 1x)开始,并添加了两个旨在使用原始设置的一半(0.5x)和两倍(2x)的计算能力。
| 配置 | 成本/小时[5] | |
|---|---|---|
| Redshift[6] | 5x ra3.4xlarge (1x) | 16.30 美元 |
| Snowflake[7] | 中 (0.5x) | 8.06 美元 |
| 大 (1x) | $16.13 | |
| 特大 (2x) | 32.26 美元 | |
| Databricks[8] | 中 (0.5x) | 4.64 美元 |
| 大 (1x) | 9.28 美元 | |
| 特大 (2x) | 18.56 美元 | |
| Synapse | DW500c (0.5x) | 6.00 美元 |
| DW1000c (1x) | 12.00 美元 | |
| DW2000c (2x) | 24.00 美元 | |
| BigQuery[9] | On-Demand | 不适用 |
我们如何调整仓库?
这些数据仓库各自提供高级功能,如排序键、聚类键和日期分区。我们选择不在此基准测试中使用任何这些功能[10]。我们确实在 Redshift 中应用了列压缩编码,在 Synapse 中应用了列存储索引;Snowflake、Databricks 和 BigQuery 自动应用压缩。
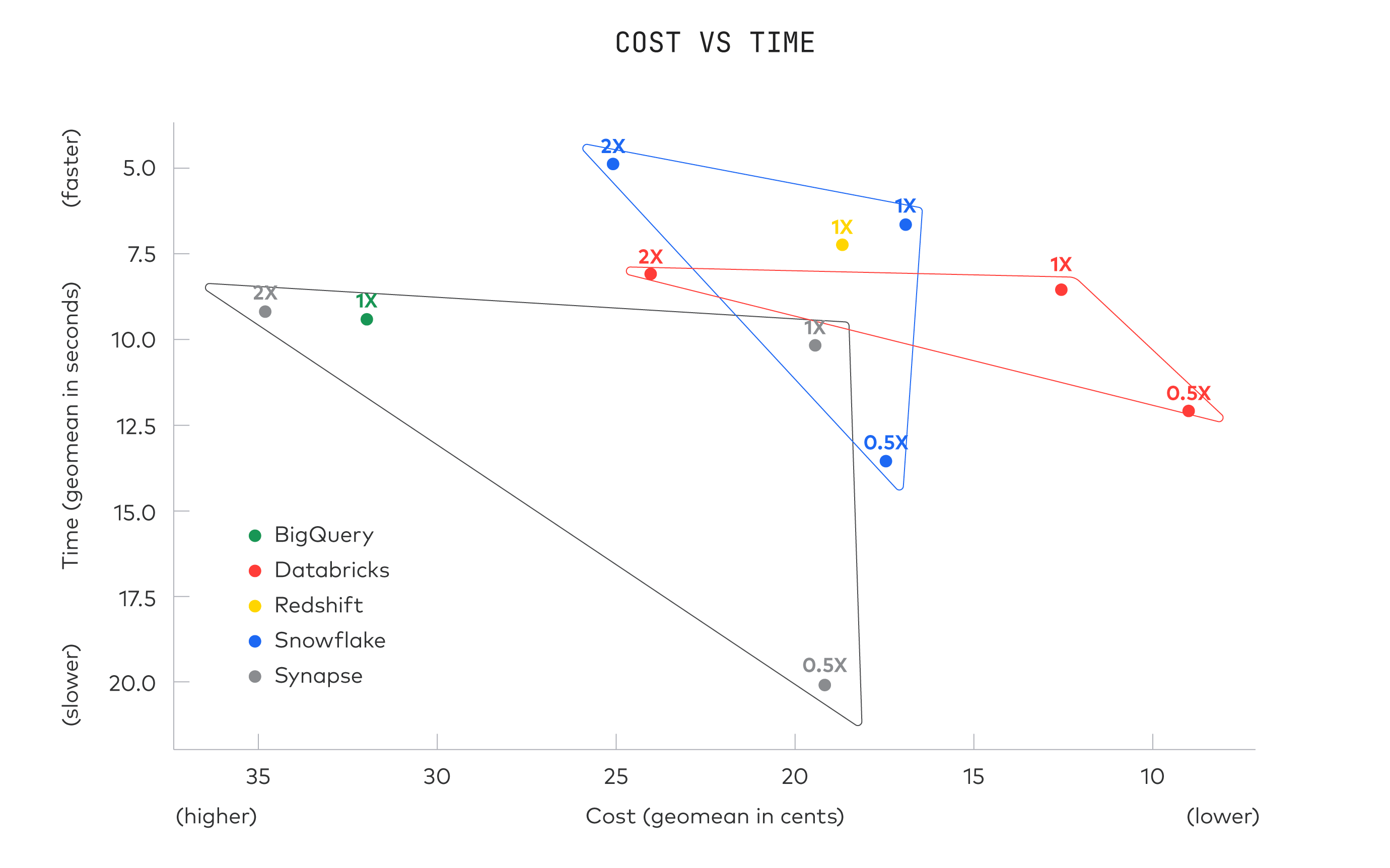
结果
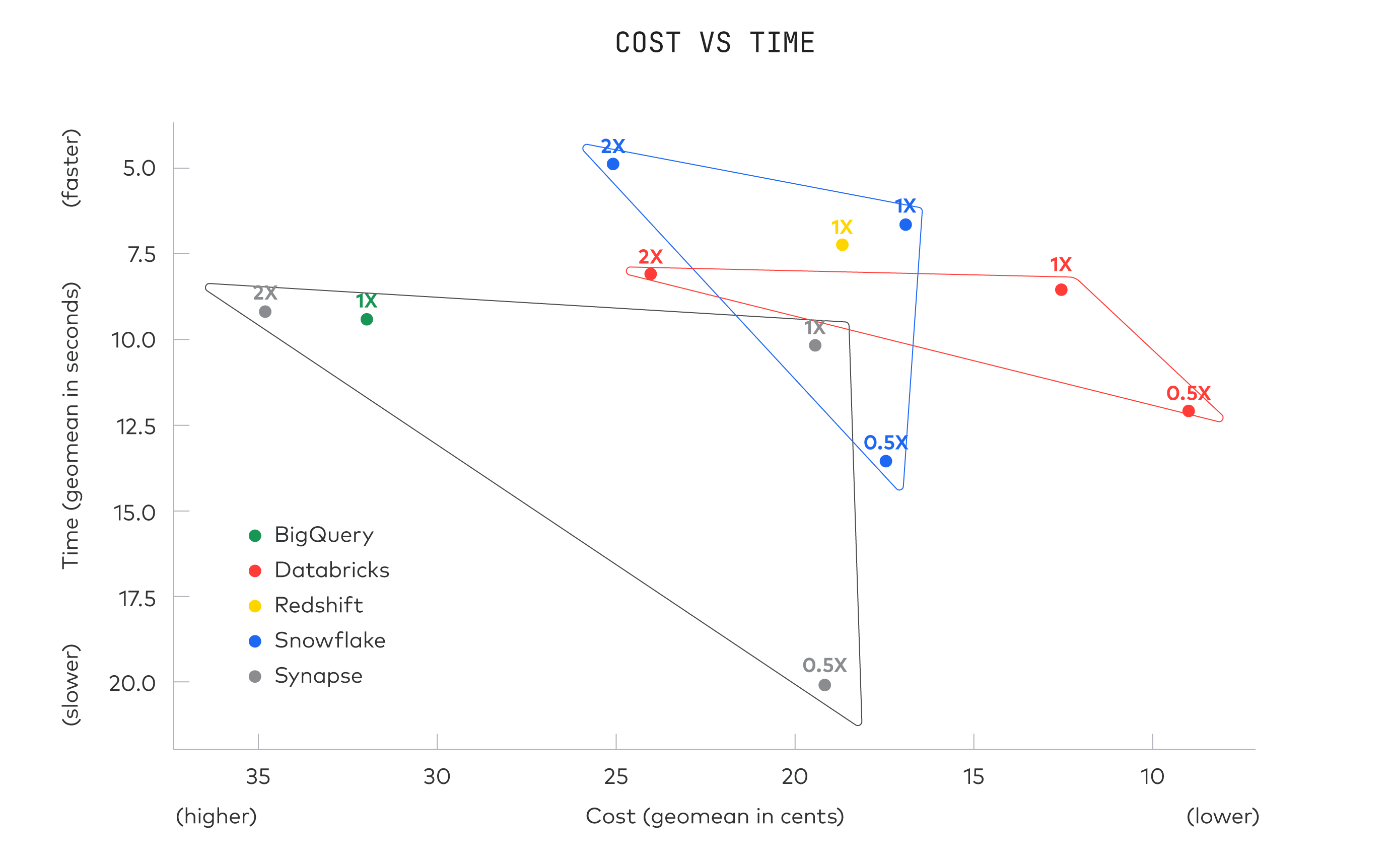
所有仓库都具有出色的执行速度,适合即席的交互式查询。为了计算成本,我们将运行时间乘以每秒配置成本,然后除以估计的仓库利用率[11]。
性能提升了多少?
我们在 2020 年执行了相同的基准测试。所有系统的性能在过去 2 年中都有所提高[12]:
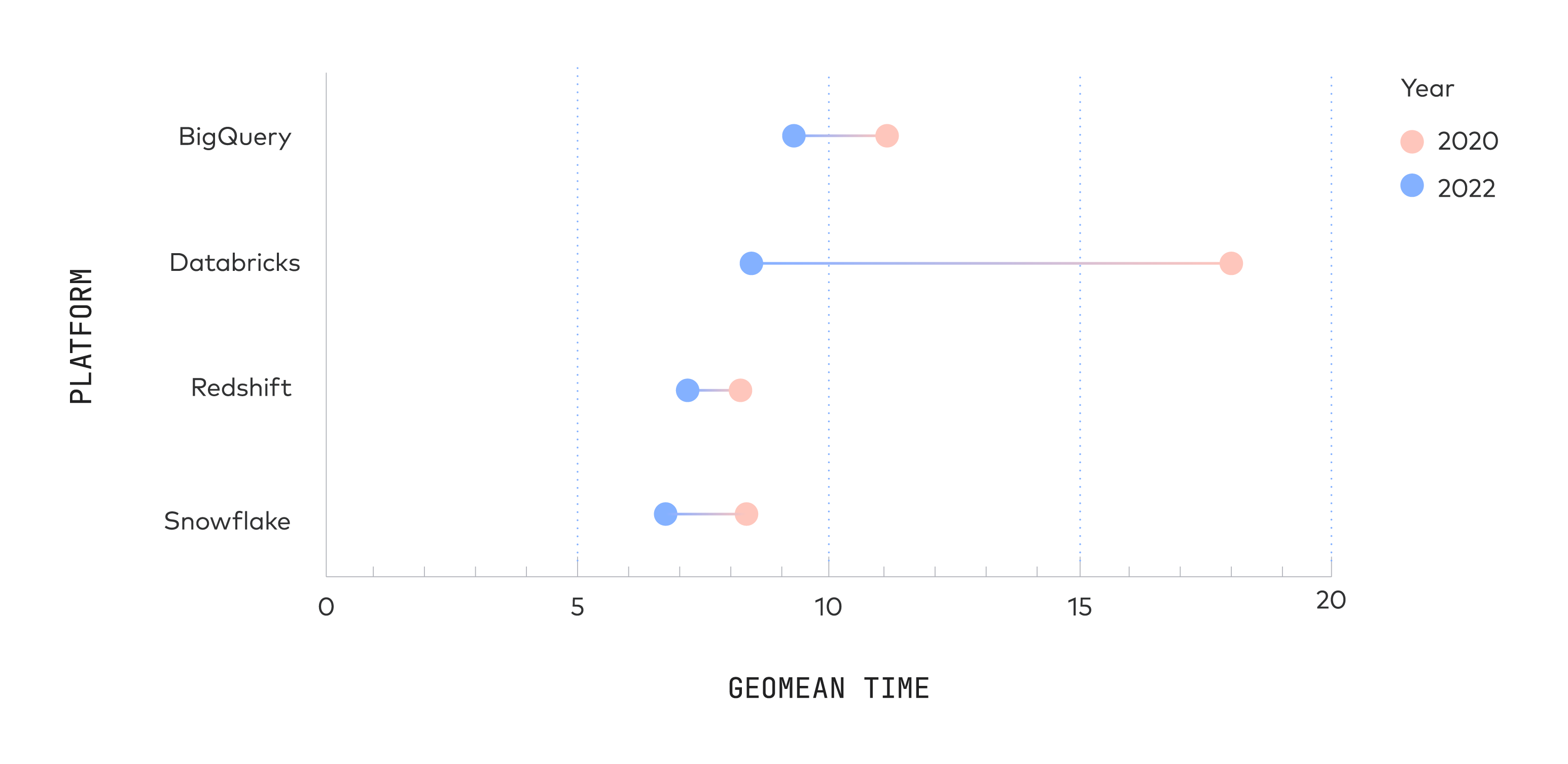
Databricks 做出了最大的改进,这并不奇怪,因为他们完全重写了 SQL 执行引擎。
为什么我们的结果与以前的基准不同?
Databricks 的 TPC-DS 基准
2021 年 11 月,Databricks 发布了官方 TPC-DS 基准测试,展示了他们新的“Photon”SQL 执行引擎的性能。他们还发布了 Databricks 与 Snowflake 的比较,发现他们的系统速度快 2.7 倍,成本低 12 倍。与我们的相比,Databricks 的基准测试有很多不同之处:
- 他们使用了 100 TB 的数据集,而我们使用了 1 TB 的数据集。
- 他们使用 4XL 端点,而我们使用 L 端点。
- 他们在一些表中使用了日期分区,用于 Databricks 以及它们与 Snowflake 的比较。
- 他们在加载后立即运行“分析”命令以更新列统计信息。
- Databricks 报告总运行时间,而我们报告 geomean 运行时间。总运行时间由运行时间最长的查询决定,而 geomean 对所有查询给予同等权重。
Databricks 在 TPC-DS 网站上发布了重现其基准测试的代码,这对于理解我们的基准测试与他们的基准测试之间的关键差异非常有帮助。
Gigaom 的云数据仓库性能基准
2019 年 4 月,Gigaom 在 BigQuery、Redshift、Snowflake 和 Azure SQL 数据仓库上运行了一个版本的 TPC-DS 查询。该基准测试由 Microsoft 赞助。他们使用了 30 倍以上的数据(30 TB 对比 1 TB 规模)。他们为不同的系统配置了不同大小的集群,并观察到运行时间比我们慢得多:
奇怪的是,他们观察到如此缓慢的性能,因为他们的集群比我们大 5-10 倍,但他们的数据只比我们大 3 倍。
Amazon 的 Redshift 与 BigQuery 基准测试
2016 年 10 月,亚马逊在 BigQuery 和 Redshift 上运行了一个版本的 TPC-DS 查询。亚马逊报告称,Redshift 的速度提高了 6 倍,而 BigQuery 的执行时间通常超过一分钟。他们的基准测试与我们的基准测试之间的主要区别是:
- 他们使用了 10 倍大的数据集(10TB 对比 1TB)和 2 倍大的 Redshift 集群(38.40 美元/小时对比 19.20 美元/小时)。
- 他们使用 sort 和 dist 键来调整仓库,而我们没有。
- BigQuery Standard-SQL 在 2016 年 10 月仍处于测试阶段;当我们运行这个基准测试时,到 2018 年它可能会变得更快。
来自声称自己的产品是最好的供应商的基准应该有所保留。亚马逊的博文中有许多细节没有具体说明。例如,他们使用了一个巨大的 Redshift 集群——他们是否将所有内存分配给单个用户以使该基准测试以超快的速度完成,即使这不是一个现实的配置?我们不知道。如果 AWS 发布重现其基准测试所需的代码,那就太好了,这样我们就可以评估它的真实性。
Periscope 的 Redshift vs. Snowflake vs. BigQuery 基准测试
同样在 2016 年 10 月,Periscope Data 使用每小时聚合查询的三种变体比较了 Redshift、Snowflake 和 BigQuery,这些变体将 10 亿行的事实表连接到购物中心维度表。他们发现 Redshift 的速度与 BigQuery 大致相同,但 Snowflake 慢了两倍。他们的基准测试与我们的基准测试之间的主要区别是:
- 他们多次运行相同的查询,从而消除了 Redshift 缓慢的编译时间。
- 他们的查询比我们的 TPC-DS 查询简单得多。
使用“简单”查询进行基准测试的问题是每个仓库在这个测试中都会做得很好;Snowflake 是否快速执行简单查询而 Redshift 是否真的非常快速地执行简单查询并不重要。重要的是您是否可以足够快地执行硬查询。
Periscope 也比较了成本,但他们使用了一种稍微不同的方法来计算每次查询的成本。和我们一样,他们查看了客户的实际使用数据,但他们没有使用空闲时间百分比,而是查看了每小时的查询次数。他们确定大多数(但不是全部)Periscope 客户会发现 Redshift 更便宜,但这并没有太大的区别。
Mark Litwintschik 的 11 亿次出租车出行基准
Mark Litwintshik 在 2016 年 4 月和 2016 年 6 月对 BigQuery 和 Redshift 进行了基准测试。他对一个包含 11 亿行的表运行了四个简单查询。他发现 BigQuery 的速度与 Redshift 集群的速度大致相同,大约是我们集群的 2 倍(41 美元/小时)。两个仓库都在 1-3 秒内完成了他的查询,所以这可能代表了“性能底线”:即使是最简单的查询也有最短的执行时间。
结论
这些仓库都具有优良的性价比。我们不应该对它们的相似感到惊讶:自从 2005 年C-Store论文发表以来,制作快速列式数据仓库的基本技术就广为人知。这些数据仓库无疑使用了标准的性能技巧:列式存储,基于成本的查询计划、流水线执行和即时编译。我们应该对任何声称一个数据仓库比另一个数据仓库快得多的基准表示怀疑。
仓库之间最重要的区别是由它们的设计选择引起的质的差异:一些仓库强调可调性,另一些则强调易用性。如果您正在评估数据仓库,您应该演示多个系统,然后选择一个最适合您的系统。
更正
2022 年 12 月 20 日:我们根据供应商的反馈澄清了一些描述。
云数据仓库基准报告下载完整报告:https://go.fivetran.com/reports/cloud-data-warehouse-benchmark
[1] Snowflake Inc. Q1 2023 earnings call transcript
[2] TPC-DS is an industry-standard benchmarking meant for data warehouses. Even though we used TPC-DS data and queries, this benchmark is not an official TPC-DS benchmark, because we only used one scale, we modified the queries slightly, and we didn’t tune the data warehouses or generate alternative versions of the queries.
[3] This is a small scale by the standards of data warehouses, but most Fivetran users are interested in data sources like Salesforce or MySQL, which have complex schemas but modest size.
[4] We had to modify the queries slightly to get them to run across all warehouses. The modifications we made were small, mostly changing type names.
[5] To calculate a cost per query, we assumed each warehouse was in use 35% of the time. For BigQuery, we used pay-per query at $5 / TB scanned.
[6] We are only reporting one configuration of Redshift because we were not able to reproduce results across different configurations.
[7] Snowflake cost is based on "Standard" pricing in AWS. If you use a higher tier like "Enterprise" or "Business Critical," your cost would be higher.
[8] Databricks cost is based on “Standard” pricing in AWS. If you use a higher tier like “Premium” or “Enterprise,” your costs would be higher.
[9] BigQuery is a pure shared-resource query service, so there is no equivalent “configuration”; you simply send queries to BigQuery, and it sends you back results.
[10] If you know what kind of queries are going to run in your warehouse, you can use these features to tune your tables and make specific queries much faster. However, typical Fivetran users run all kinds of unpredictable queries on their warehouses, so there will always be a lot of queries that don’t benefit from tuning.
[11] We assume that real-world data warehouses are in use 35% of the time. We derived this figure by studying our own usage pattern; Fivetran has over 1000 employees and makes extensive use of business-intelligence across the organization.
[12] We previously benchmarked Databricks using a 4xi3.8xlarge configuration, and BigQuery using a 600-slot flat-rate configuration.
文章来源:https://www.fivetran.com/blog/warehouse-benchmark
