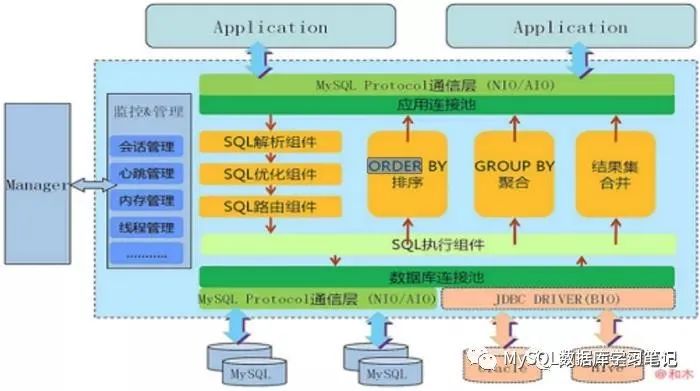
| 数据库中间件可以被看做是一个或多个数据库集群构成的逻辑库。也可以以多租户的形式给一个或多个应用提供服务,每个应用访问的可能是一个独立或者是共享的物理库。 |
| 分布式数据库中,对应用来说,读写数据的表就是逻辑表。可以是数据切分后分布在不同的库中,也可以不切分。 |
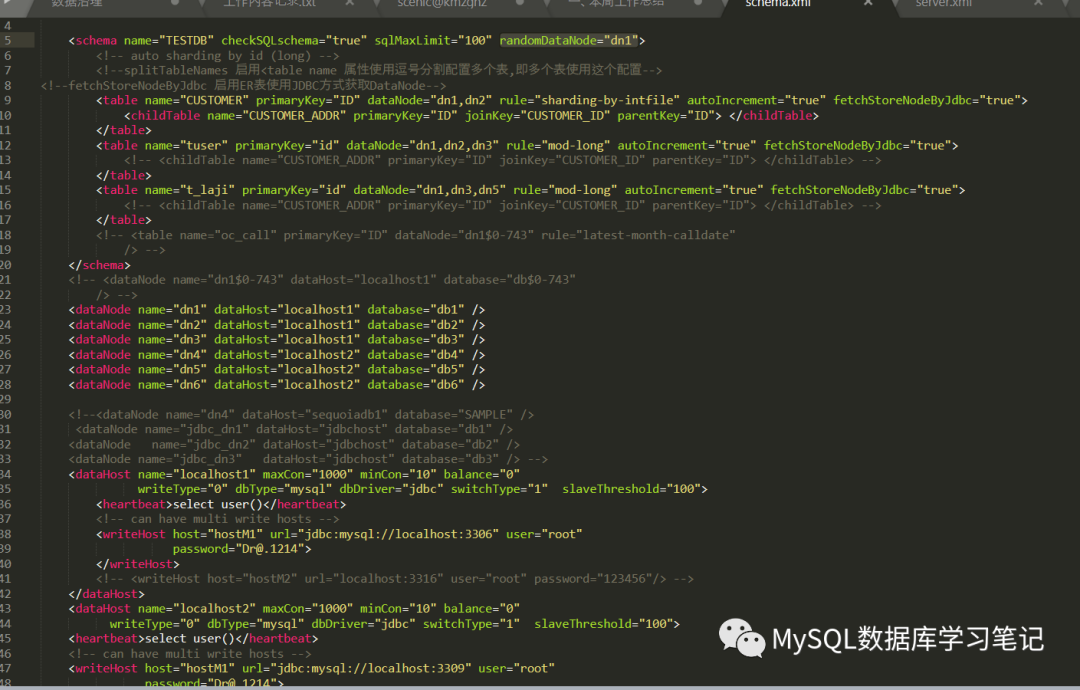
| 大表按照一定的分片规则分配数据到不同的节点,每个分片都有一部分数据,所有分片构成了完整的数据。 |
| 不是所有表都需要切分,非分片是相对分片表来说的,就是那些不需要进行数据切分的表。 |
| 数据切分后,每个分片节点(dataNode)不一定都会独占一台机器,同一机器上面可以有多个分片数据库,这样一个或多个分片节点(dataNode)所在的机器就是节点主机(dataHost),为了规避单节点主机并发数限制,尽量将读写压力高的分片节点(dataNode)均衡的放在不同的节点主机(dataHost)。 |
| 一个大表被分到不同的分片数据库上面,每个表分片所在的数据库就是分片节点 (dataNode ) |
| 一个大表被分成若干个分片表,就需要一定的规则,这样按照某种业务规则把数据分到某个分片的规则就是分片规则。 |
| 关系型数据库是基于实体关系模型(Entity-Relationship Model)之上,通过其描述了真实世界中事物与关系,Mycat 中的 ER 表即是来源于此。根据这一思路,提出了基于 E-R 关系的数据分片策略,子表的记录与所关联的父表记录存放在同一个数据分片上,即子表依赖于父表,通过表分组(Table Group)保证数据 Join 不会跨库操作。 |
| 在分片的情况下,当业务表因为规模而进行分片以后,业务表与这些附属的字典表之间的关联,就成了比较棘手的问题,所以 Mycat 中通过数据冗余来解决这类表的 join,即所有的分片都有一份数据的拷贝,所有将字典表或者符合字典表特性的一些表定义为全局表。数据冗余是解决跨分片数据 join 的一种很好的思路,也是数据切分规划的另外一条重要规则。 |
| 数据切分后,原有的关系数据库中的主键约束在分布式条件下将无法使用,因此需要引入外部机制保证数据唯一性标识,这种保证全局性的数据唯一标识的机制就是全局序列号(sequence)。 |