




导读:大家好,今天和大家分享一下 Apache Doris 以及百度基于 Apache Doris 研发的商业化产品 Palo 的原理和应用实践,首先做一个简单的自我介绍,我叫杨政国,是 Apache Doris 的 PMC,同时也是百度资深研发工程师。
今天的分享主要分以下几个部分,首先介绍一下 Doris 的发展历程,之后会介绍 Doris适用场景,之后会比较详细的介绍 Doris 核心的产品特性,最后会介绍一下 Doris未来的发展的趋势和在规划中的一些新的 Feature。
全文目录:
Doris 的发展的历程
Doris 的应用场景
Doris 的核心特性
Doris的未来展望
Palo
01
Doris 的发展的历程


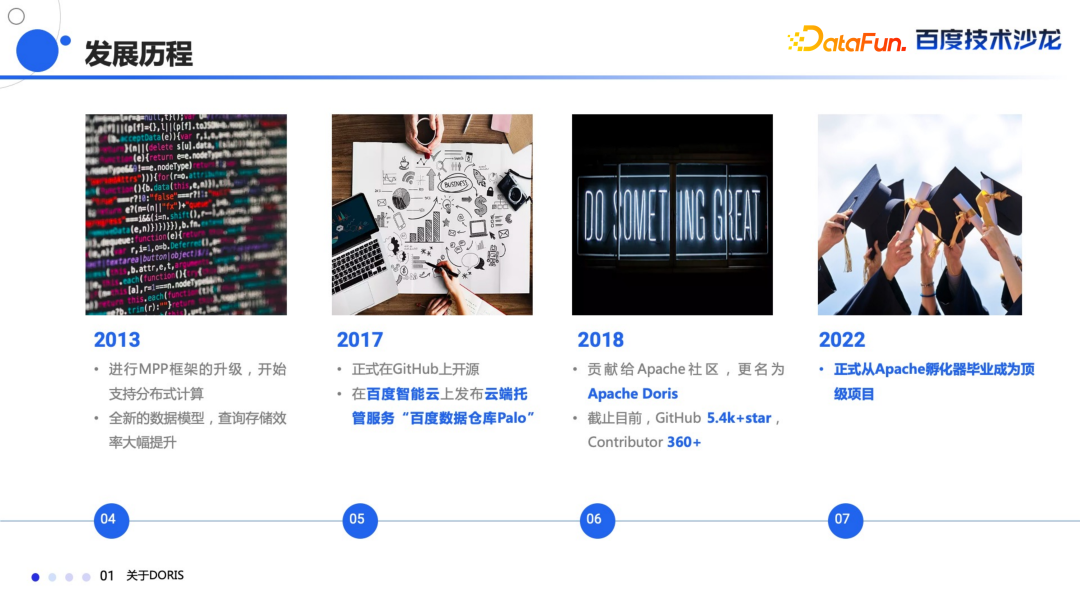
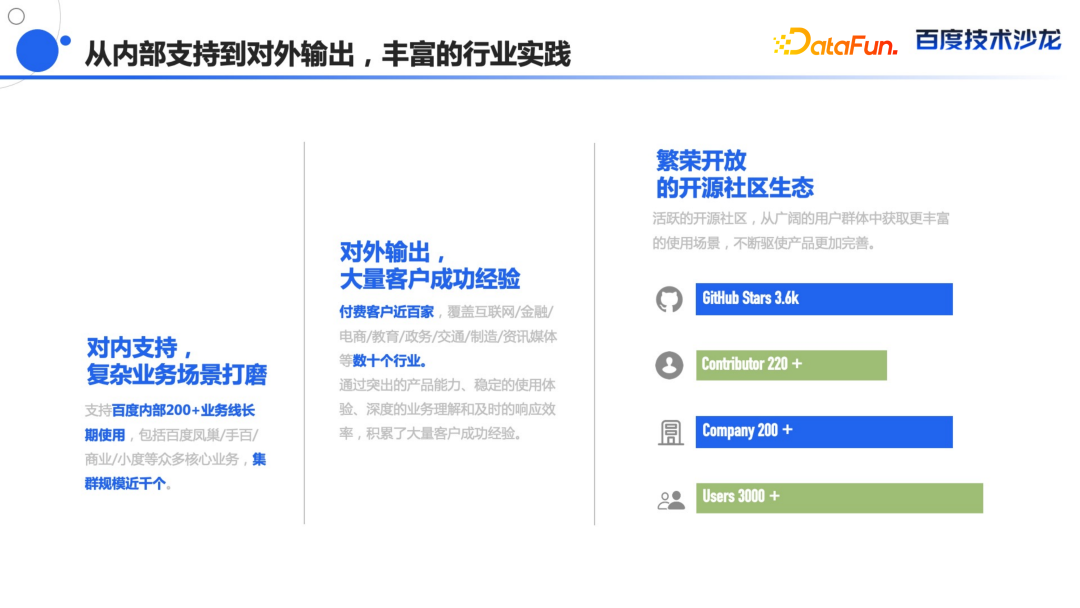
2008 年正式上线,服务于百度的凤巢,上线之后数据的更新频率从原来的天级变成了分钟级; 2009 年内部进行了通用化的改造,开始承接公司内部其他的报表需求; 2012 年承接了百度内部几乎所有的报表业务; 2013 年进行全面 MPP 框架升级,开始支持分布式计算,对于底层的数据模型做了大规模的改进,查询和存储效率都有极大的提升; 2017 年决定把 Doris 在 GitHub 上进行开源; 2018 年贡献给 Apache 社区,并正式更名为 Apache Doris,截至目前在 GitHub 有 5.4k 多的 Star,Contributor 数量超过了 360; 2022年 6 月份正式从 Apache 孵化器毕业,成为 Apache 的顶级项目。
02

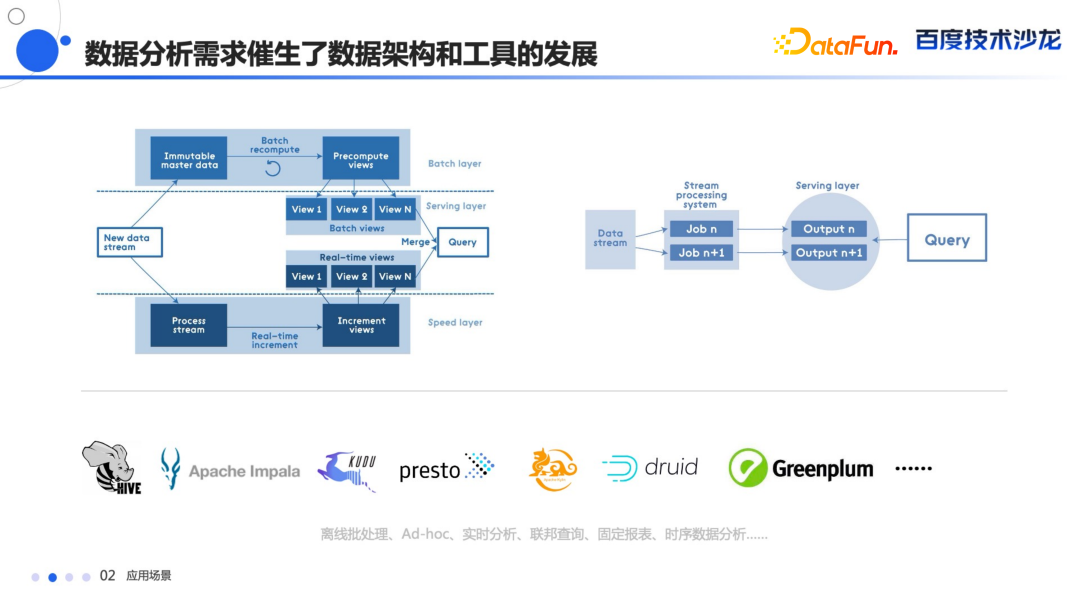
查询效率低下,需要一个快速查询响应的工具。 分析时效性提高,随着业务的发展,T+1 的分析已经不能够满足业务要求。 需要更灵活的方式去应对业务趋势和系统建设滞后的矛盾,以及交付周期长的问题。 随着业务分析人员的增多,需要更低门槛的分析工具,来满足全民数据探索的需求。
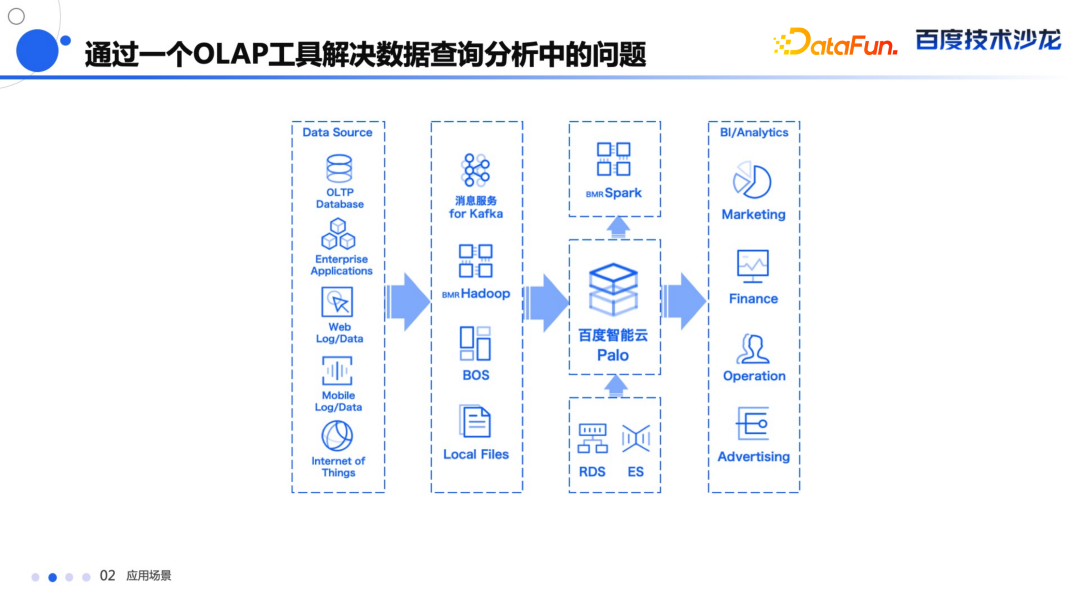

海量数据上面提供亚秒级查询延迟响应。 支持流式数据的导入,完成实时的业务洞察。 统一大数据平台平台架构和数据流。 还能通过跨多数据源的联邦查询,支持像 ODBC,Hive,Iceberg,Hudi,ES等多种数据源。 能通过多种 Connector 和 Flink、Spark 这些数据分析工具有非常良好的交互,满足业务人员多元化查询需求。 通过 MySQL 协议能够方便地和其他的 BI 工具进行无缝的对接,提供对海量数据的自助探查和多维度分析的能力。
通过内部的各种优化手段,提供极致的性能。 通过灵活的种资源配置能够同时支持高并发和高吞吐的大查询,支持非常丰富的查询场景。 兼容 MySQL 协议,支持标准 SQL,非常简单易用,能够与现有系统非常好的融合。 内部提供多种高可用的策略的保证,像单点故障和系统升级等对线上业务基本无感。
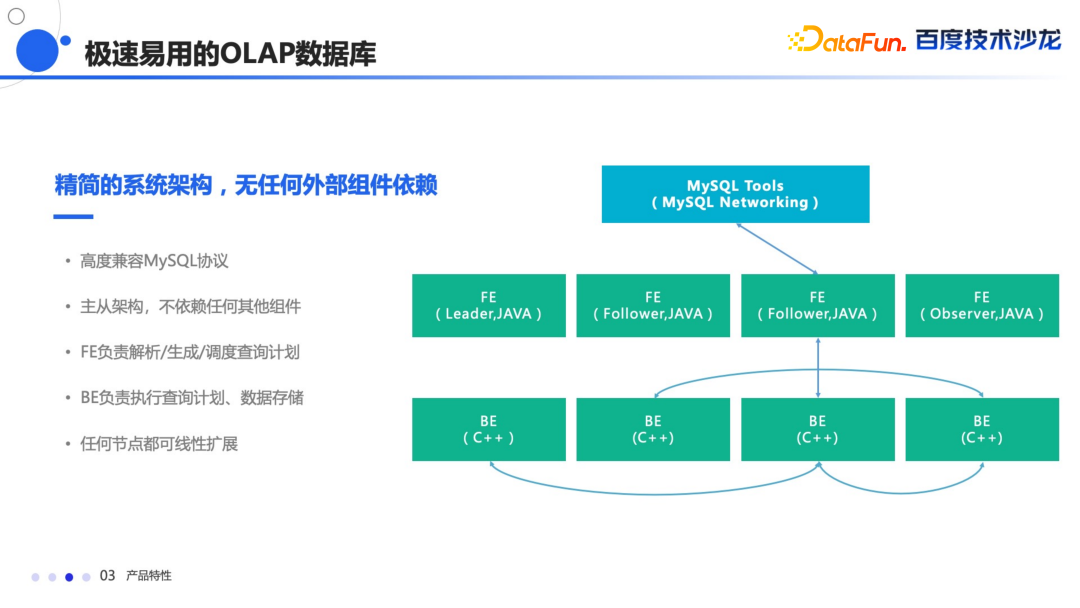
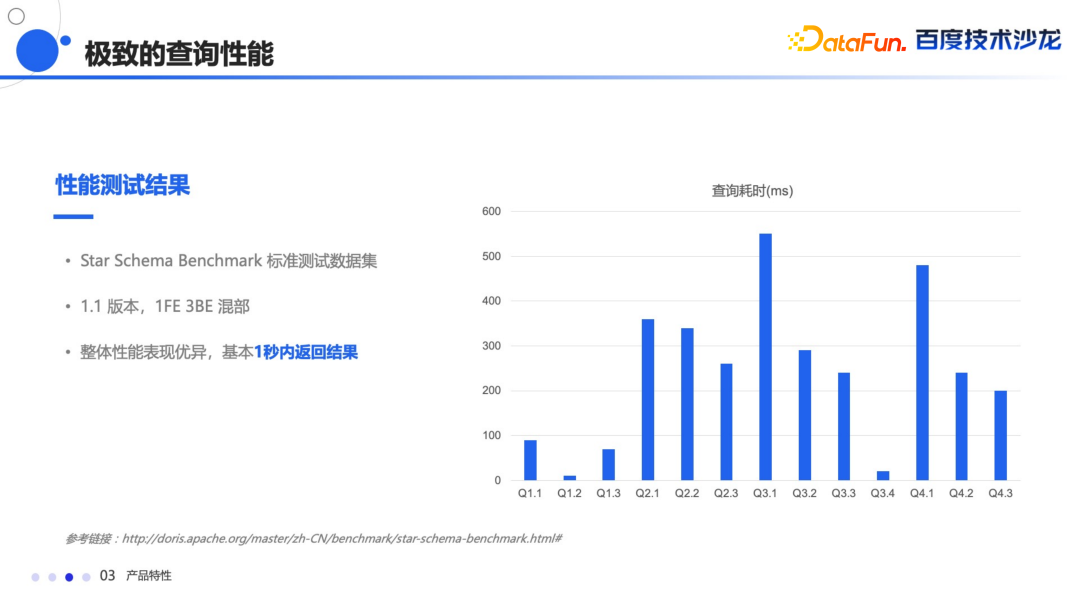
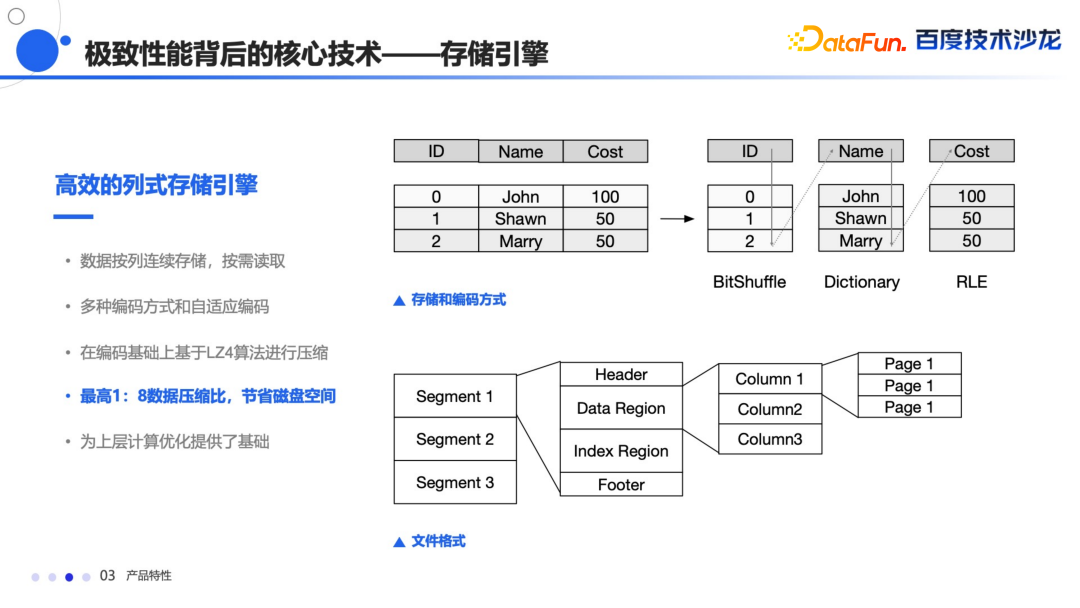
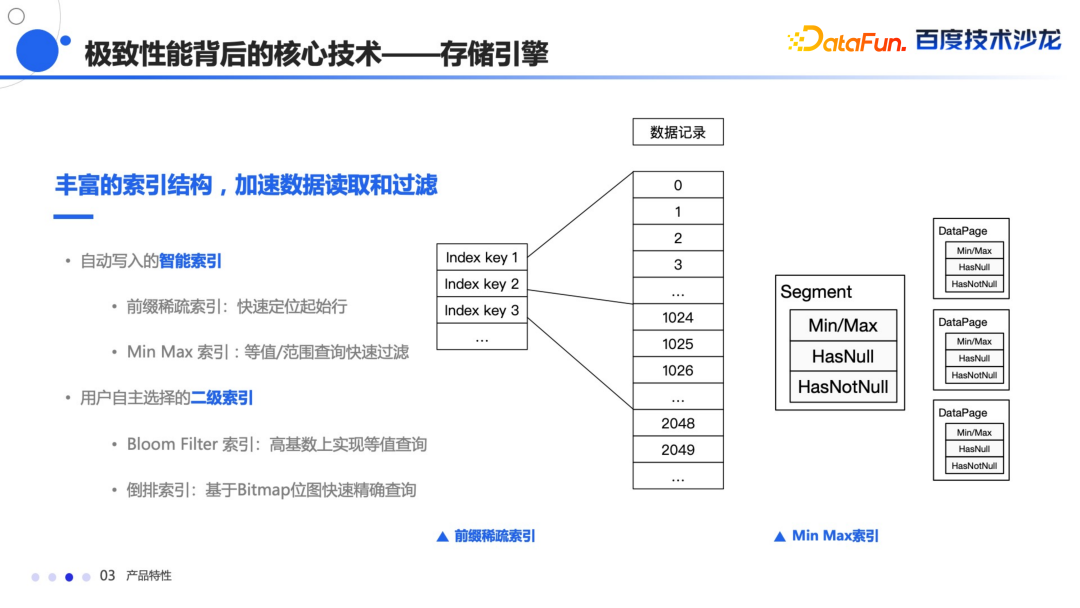
Bloom Filter 索引主要提高高基数上的等值查询的性能 Bitmap 索引能够快速的进行精确的查询定位
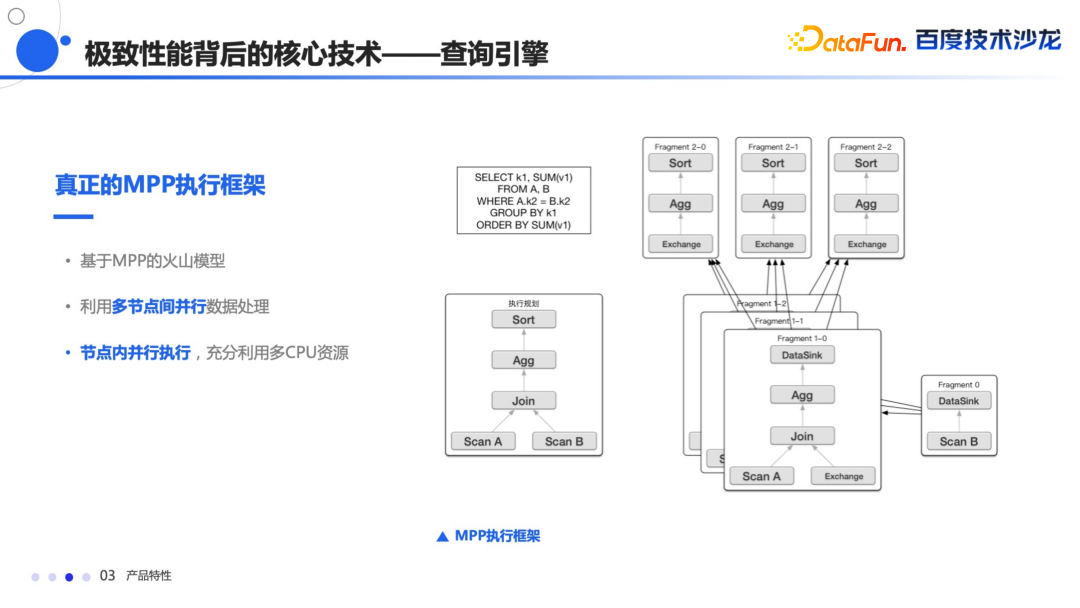
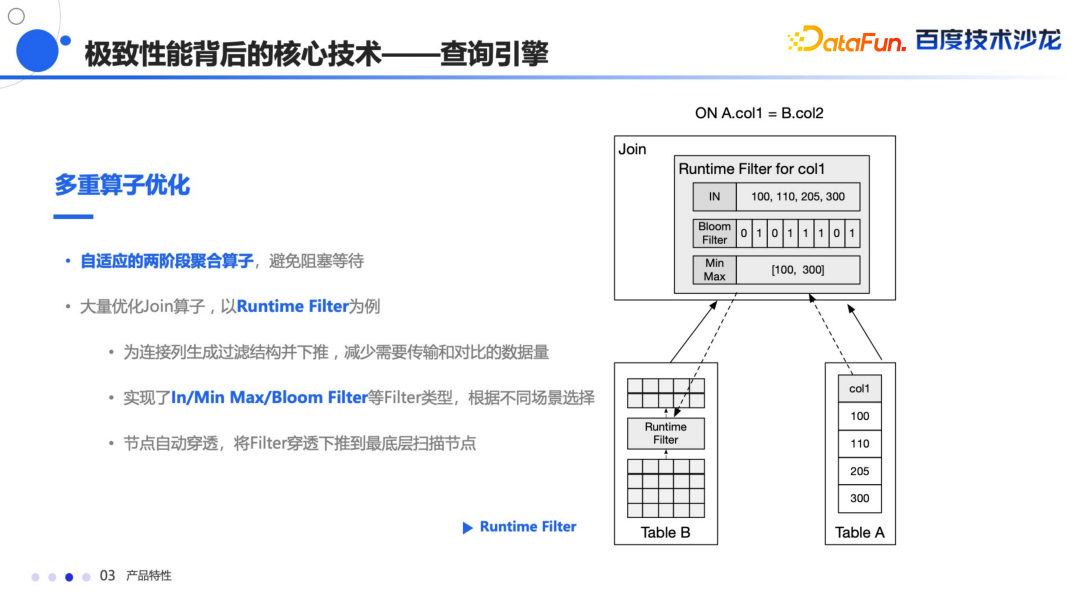
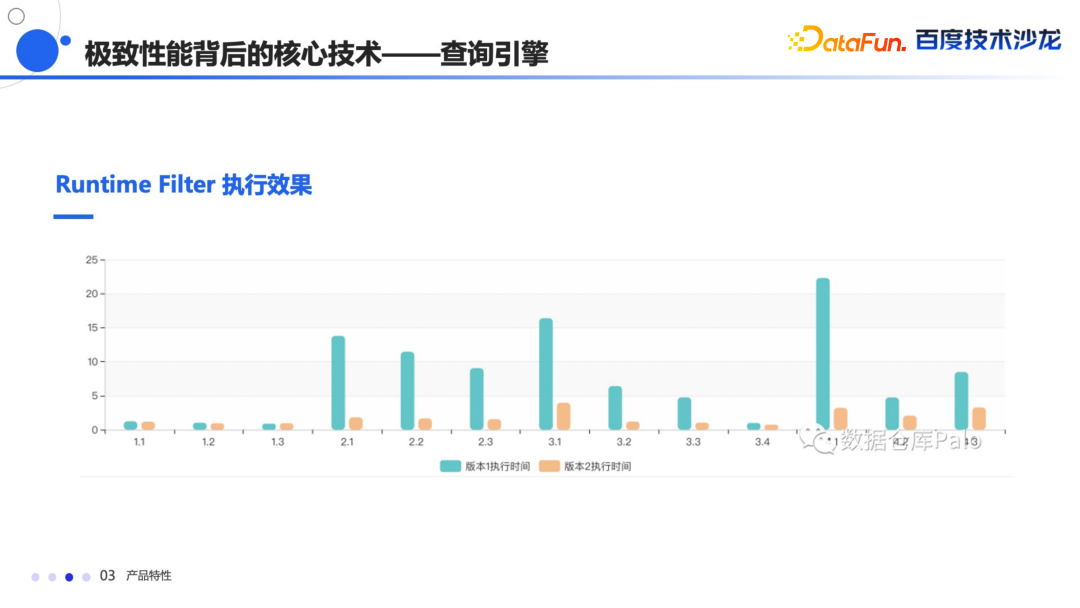
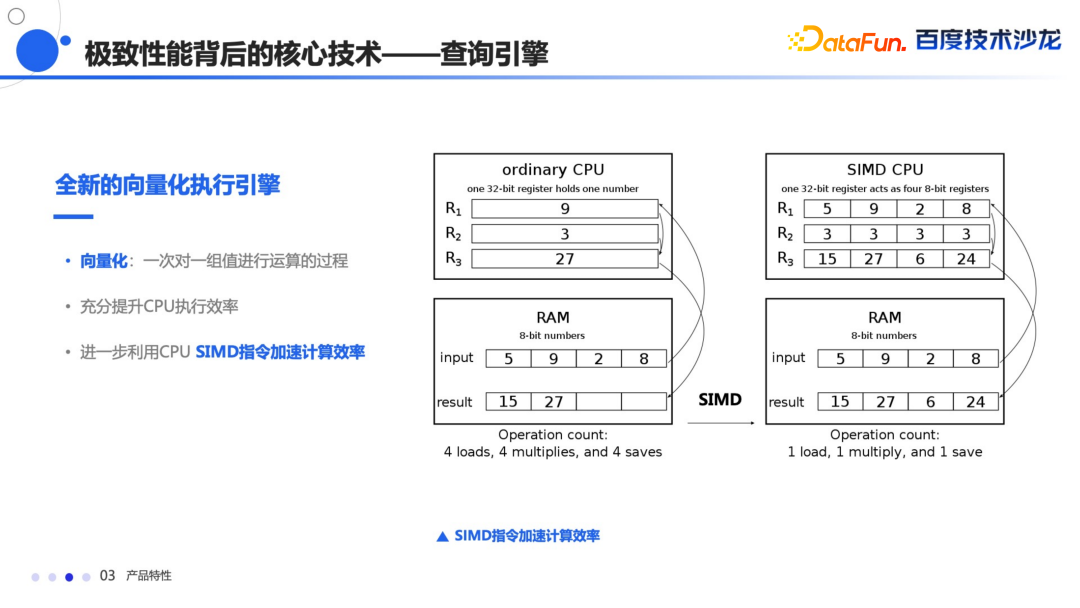
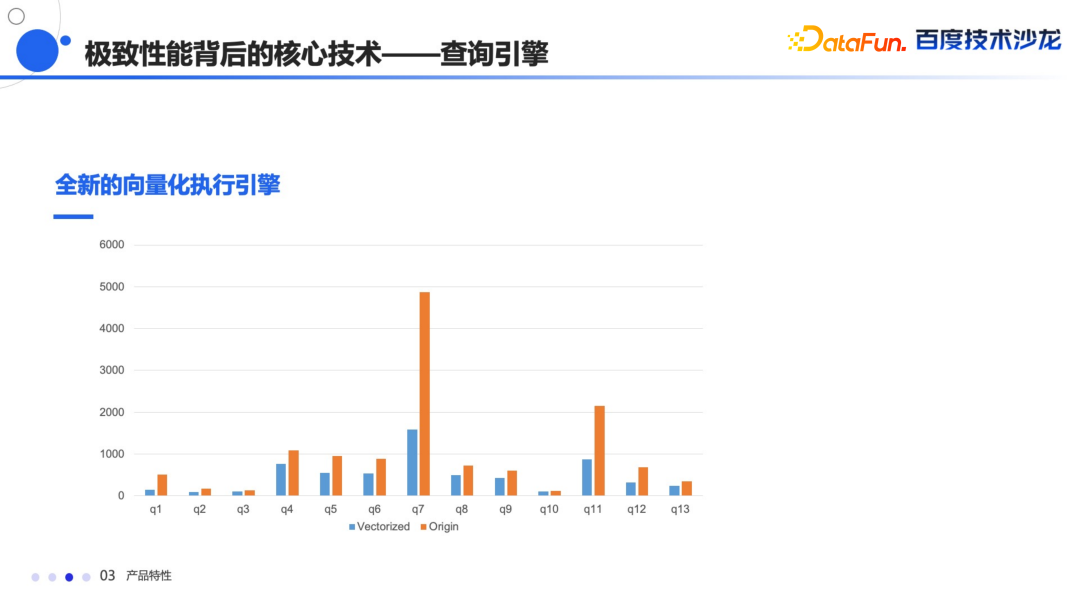
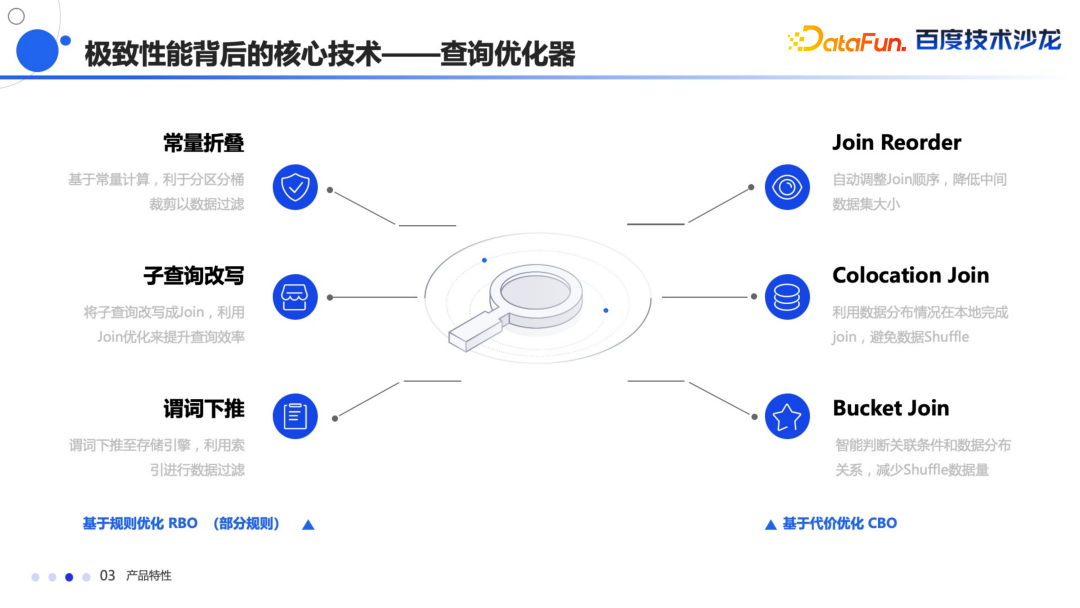
常量折叠 子查询的改写 还有谓词下推
Join Reorder:自动根据数据的分布和大小自动调整 Join 顺序。 Colocation Join:在数据存储的时候,会根据规则,将数据按照一定顺序规则分布到相同的节点上,在 Join 的时候能够完成本地 Join,避免数据 Shuffle,从而大幅提升查询性能。 Bucket Join:这是 Colocation Join 的升级版本,它会自动判断关联条件中的数据分布关系,如果符合要求,会自动进行 Colocation Join,从而减少数据的 Shuffle。
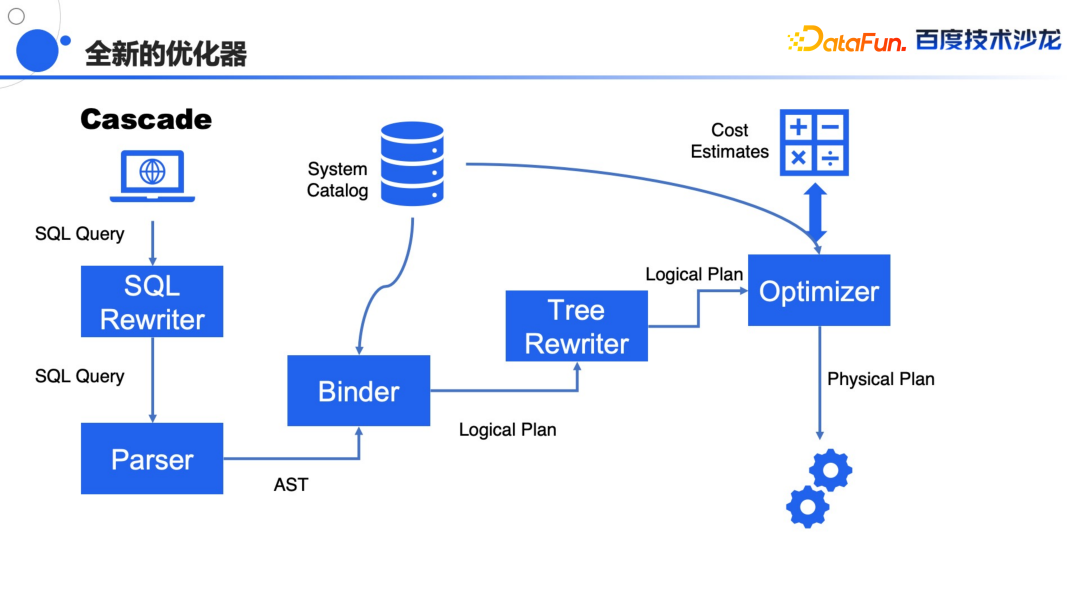
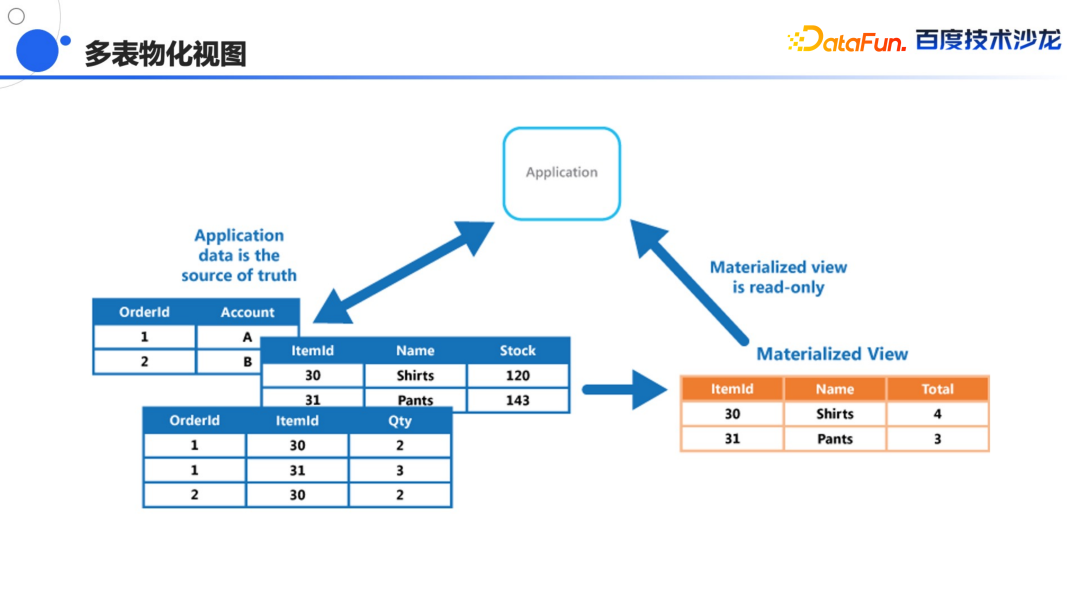
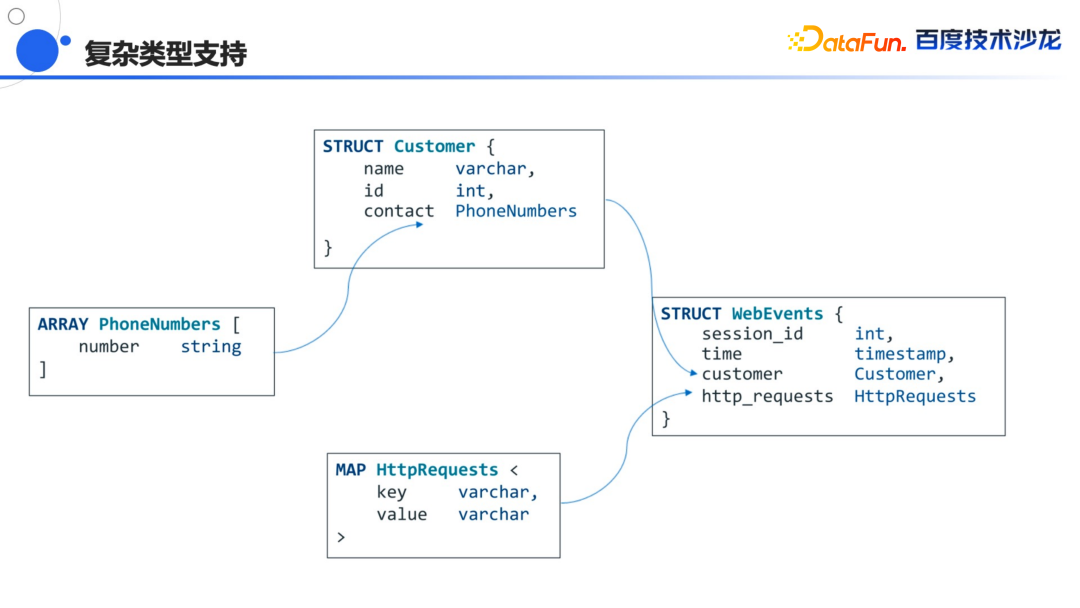

能够充分利用云平台的优势,能够按需去取用海量的资源,可以更加可控的进行资源管理。 即将上线基于对象存储的冷热分离的架构,降低数据成本,也能够结合缓存策略对冷数据进行快速查询。 提供更丰富的云上的管控和监测工具,能够快速的扩容缩容,变配啊,程序启停,监控报警功能,同时提供一些企业级的生态组件,帮助用户去自助的取数分析。


|分享嘉宾|

杨政国
百度 资深研发工程师
百度资深研发工程师, 百度 palo团队技术负责人。2014 年加入百度,长期从事大数据和机器学习方向研发,是Apache Doris 社区的PMC成员之一,Doris 社区的核心贡献者之一。
🧐 分享、点赞、在看,给个3连击呗!👇
文章转载自畅谈Fintech,如果涉嫌侵权,请发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
