




背景:我司之前遗留了一点codis的问题,所以在一段时间内把codis下线了,最近在准备重新上线codis。在上线准备过程中,遇到了一个sentinel的问题。
问题描叙:
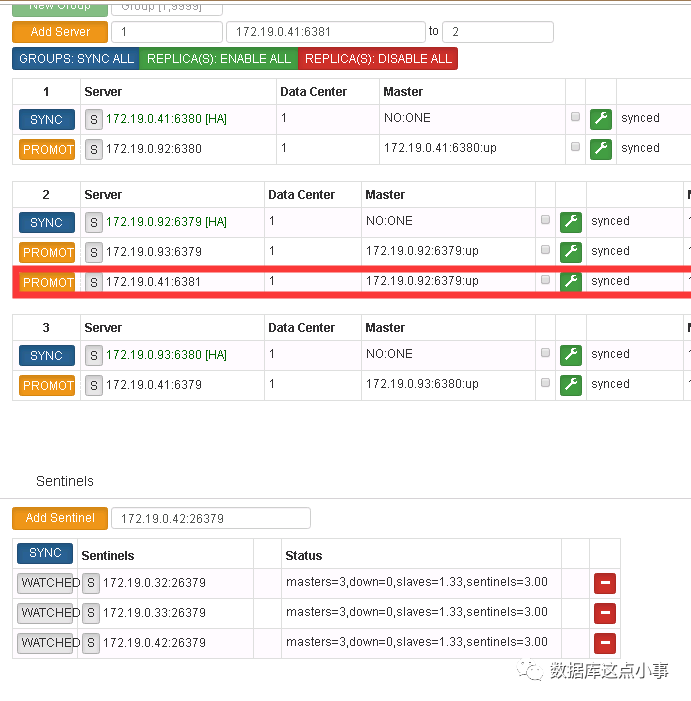
通过一系列的操作,讲各组的主从规划后之后,41:6381这个server是可以直接下线了,我们在dashboard直接下掉这个server
然后发现sentinel 还是检测到了这个已经下掉的slave并且给出了告警。这个时候 其实集群是OK的,只是可能在group2 master宕了的时候,slave切主可能会出现问题。
问题处理:
当然,既然出现了问题我们就解决
首先,查看一下sentinel配置文件内容
sentinel failover-timeout codis-changtu-3 300000sentinel config-epoch codis-changtu-3 0sentinel leader-epoch codis-changtu-3 0sentinel known-slave codis-changtu-3 172.19.0.41 6379sentinel known-sentinel codis-changtu-3 172.19.0.33 26379 388c90258277673bcd74cceab810c6a89606293dsentinel known-sentinel codis-changtu-3 172.19.0.42 26379 2a3e93c9861d04587ee2273d9e8764909ef29a0asentinel monitor codis-changtu-2 172.19.0.92 6379 2sentinel failover-timeout codis-changtu-2 300000sentinel config-epoch codis-changtu-2 0sentinel leader-epoch codis-changtu-2 0sentinel known-slave codis-changtu-2 172.19.0.41 6381sentinel known-slave codis-changtu-2 172.19.0.93 6379sentinel known-sentinel codis-changtu-2 172.19.0.33 26379 388c90258277673bcd74cceab810c6a89606293dsentinel known-sentinel codis-changtu-2 172.19.0.42 26379 2a3e93c9861d04587ee2273d9e8764909ef29a0asentinel monitor codis-changtu-1 172.19.0.41 6380 2sentinel failover-timeout codis-changtu-1 300000sentinel config-epoch codis-changtu-1 0sentinel leader-epoch codis-changtu-1 0sentinel known-slave codis-changtu-1 172.19.0.92 6380sentinel known-sentinel codis-changtu-1 172.19.0.33 26379 388c90258277673bcd74cceab810c6a89606293dsentinel known-sentinel codis-changtu-1 172.19.0.42 26379 2a3e93c9861d04587ee2273d9e8764909ef29a0asentinel current-epoch 2
自动生成的配置文件部分41 6381这个slave还是存在
思路一:把这行配置注释掉(或者删掉),重启sentinel
结果:在sentinel重启后,sync完,问题并没有解决和原来一样,再次检查sentinel配置文件发现这行配置信息又重新写入了配置文件中
思路二:这个配置文件是不是从其他地方获取来的。
结果:检查了zk中的信息,有重新配置了sentinel,再dashboard删除重新添加了sentinel节点,然而执行完sync之后发现还是老问题
处理三:这个时候,已经是有点懵逼了,到底是什么原因呢。小伙伴提了一点,你下线的6381服务有没有关啊,咦,我还真没把6381端口的server shutdown,那会不会是这个原因呢。
结果:当我把6381端口服务shutdown之后再sync sentinel发现果然问题解决了,sentinel告警也消失了。
思考:那么问题到底是出在了什么地方?
解释问题:既然我们在把6381停掉之后问题解决了,那这个服务有什么特殊性呢?
检查了一下,6381的配置文件,很惊奇的发现
slaveof 172.19.0.92 6379
在配置文件的最后一行,表明了6381还是 92:6379的slave这就能解释清楚了。
当我们直接在dashboard中将41:6381server 下线之后,在配置文件中,并没有能主动更新掉主从的关系,只是在codis集群中移出了这个server
而sentinel正在检测的其实是服务器,所以当sentinel执行同步的时候,它能检测到41:6381仍然为92:6379的slave,因此将这个信息更新到了配置文件中,这样codis集群记录到的信息和sentinel的信息就有了冲突,所以sentinel在dashboard表现除了告警。
至此,此问题打上句号。
