




本文总结ORACLE ASM的不再使用的空间的回收策略以及对性能的负面影响以及其应对策略。这些问题隐藏的非常深,通常很难被DBA察觉。
本文ASM下磁盘主要是指SSD,也可以包含传统的存储厂商。为了分析清楚问题本质,先从SSD的空间使用特点开始。
SSD 闪存空间使用特点
稍微熟悉SSD的人都了解,SSD读写的是闪存,实际全部闪存容量会比真正可用的闪存容量要大,这多出来的空间叫OP空间(Over Provision)。机械盘没有这个特点,这是由闪存(NAND)读写特点决定。
SSD闪存的写跟LSM TREE数据库类似,只支持新增(append),不支持原地修改(in-place update)。要修改数据时,就异地新增新的数据来模拟更新(out-of-place upate)。这样同一笔数据多次修改时,就有多个版本。除了最新的版本外,其他版本数据都是垃圾数据,占用的空间需要释放出来。
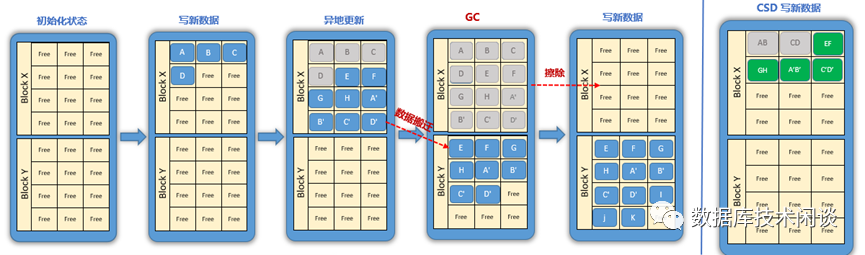
闪存读写是以页为单位(4KiB),闪存释放指块擦除,是以块为单位(几百个页)。块擦除通常靠SSD的垃圾回收(GC)主动进行。当剩余的闪存容量比例很低时,GC会很频繁。GC期间的数据搬迁会跟业务读写争抢闪存带宽资源,所以对业务读写性能有影响。
所以,如果SSD的剩余空间很高时,GC活动会很少,那么业务读写性能受影响的概率也就很小。所以 物理容量相同时,OP比例大的盘性能会更好。比如说4TB盘中的 3.2T容量就比3.84T容量时性能好很多。当然代价就是可存储容量变少。所有SSD的特点都如此,包括可计算存储CSD。CSD不一样的地方是内部有透明压缩,闪存剩余空间相对更大更足,GC少很多,后端闪存带宽使用率更节省,所以总体性能更好。
SSD闪存转换层(FTL)
上面数据更新后换了物理位置,所以SSD还提供一个模块闪存转换层(FTL)用于将数据逻辑地址(LBA)映射到闪存物理地址(PBA)。不管数据如何更新,逻辑地址都保持不变,这样实现了对内核、文件系统、应用等的兼容。
在SSD内部,当一个物理地址没有对应的逻辑地址映射且该地址上有数据时,表示是垃圾数据,其空间后面会被回收。反之,一个物理地址如果有逻辑地址映射,则其对应的就是有效数据。即使空间被回收,也要提前将数据搬迁到新的块上。
SSD的设计者期望上层应用如果确定数据没有用就通知SSD该逻辑地址作废(对应物理地址自然也作废),严格来说就是通知SSD将逻辑地址和物理地址解除映射(unmap)。
这个通知机制有多个名称,本质都是一样的。在文件系统的选项里,叫discard。
如:
mount -o discard data/nvme0n1 /dev/nvme0n1
有时候也叫 TRIM, 命令 ftrim 就是用于让文件系统向底层的SSD发TRIM 命令。
不过文件系统和数据库对空间管理有自己的想法。它们都维护有空间的元数据,自己管理这片逻辑地址。内部空间释放后自己会复用也不会通知到下层(文件系统的下层是SSD,数据库的下层可能是文件系统或SSD)。这其中最关键的一点就是这段无效数据空间什么时候会被复用。
ORACLE 空间管理介绍
ORACLE里有2个空间管理方案,一是表空间(tablespace),二是ASM。
表空间是逻辑概念,实际包含一个或多个物理文件。表空间上主要放表和索引数据。表空间文件空间支持预分配,也支持动态分配(自动扩展大小autoextend)。表空间文件不会主动收缩。所以如果表空间内部大表删除后,表空间剩余空间会留待后期其他表用,但空间不会告知文件系统或者磁盘进行回收。
ASM是文件系统,实际以实例形式运行,支持集群部署,提供集群文件系统服务。ASM主要是替代LVM和文件系统的,可以直接管理多个磁盘裸设备,并提供镜像和条带化的IO负载均衡和性能优化技术。一个ASM实例管理的存储容量可以非常大,到EB级别。一个ASM实例也可以提供给多个ORACLE实例使用。ASM可以对底层磁盘进行分组使用,支持4Kn SSD访问。基于4Kn SSD部署ASM后再部署ORACLE实例,REDO的块大小自动为4KB。
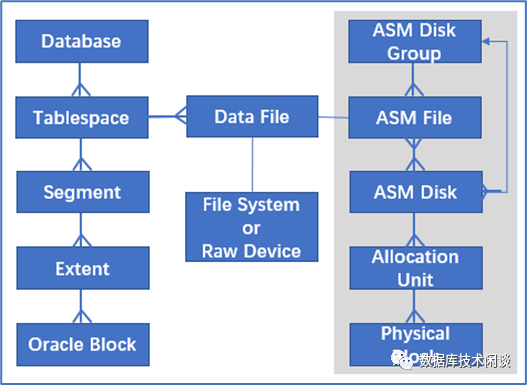
表空间和ASM可以同时用,ASM主要为ORACLE提供存储空间地址管理服务,并不会接受ORACLE的I/O请求以及ASM向SSD发读写I/O等。真正的I/O 请求还是由ORACLE实例自己完成。ASM跟文件系统一样,有自己的元数据,空间释放了后会留在内部等复用,也不会主动告知底层SSD释放对应空间。
ORACLE ASRU 方案
ORACLE ASM 不主动通知磁盘释放空间,最早观察到这个应该是存储产品。存储产品也有自己的元数据,对比存储的已使用空间跟ASM的已使用空间,很容易就发现数据相差很多。于是存储厂商跟ORACLE联合搞了一个解决方案叫 ASRU 工具。
在2010年3PAR存储和ORACLE出了一个解决方案文档
(https://www.oracle.com/us/solutions/oracle-asru-3par.pdf)。

测试了一下,其原理是将指定的ASM磁盘组里所有未使用的空间全部写入0x0数据,然后3PAR存储厂商会针对全0x0的数据进行优化(释放其空间),从而达到节省存储内部实际磁盘消耗的目的。后来好像有其他存储厂商也支持针对0x0数据进行优化,于是都推荐这个方案。
这个方案当时看可能还会觉得很有技巧。但是当SSD成为主流替代高端存储之后,ASM下磁盘是本机的SSD。就不能再使用这个方案了。或者说更严重点,这个方案用在SSD上坏透了。
SSD针对0x0数据并不会有优化,会当做有效数据用。这个方案用在SSD上等于是将SSD盘全盘未使用空间(标称容量内)都初始化写一遍。一般的SSD标盘没有提供好的方式查看SSD内部逻辑地址和物理地址容量信息,所以即使用了,用户也看不到这个坏的效果。
但是,在可计算存储上,实际特点会有一点不一样。可计算存储(CSD)会对数据进行压缩,如果数据都是0x0,则实际闪存物理消耗非常小(实际观察用ASRU大量写入0x0数据时写CSD放大在0.01)。尽管透明压缩让ASRU看起来有点价值,实际上这个方案还是很糟糕,因为它用尽了CSD提供的LBA地址。这个导致后面的写都是异地更新(FTL要不断的为LBA换PBA)。
现在还有些软件定义存储的产品,也提供数据压缩功能。ASRU在上面问题特征跟 CSD 类似。
好在ORACLE后来推出了另外一个解决方案。
精简配置(THIN PROVISION)介绍
不过ORACLE从12c版本后ASM支持一种精简配置功能。
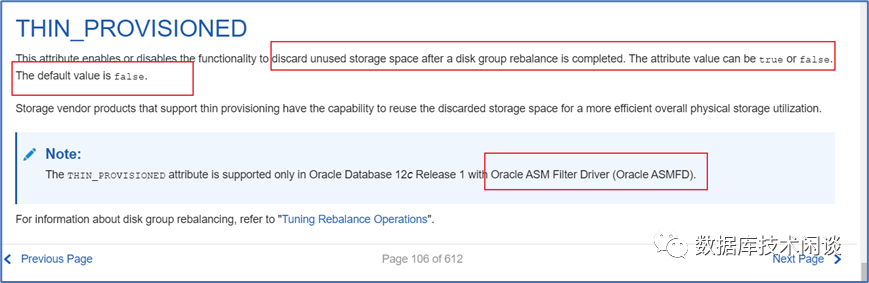
这是ASM磁盘组的一个属性后,开启这个属性后,在磁盘组做REBALANCE的时候,ASM 会将不使用的空间地址通知到底层磁盘SSD 。这个需要跟ORACLE ASM Filter Driver(ASMFD)结合使用。在早期用户使用ASM还多用的是 ASMLIB 或者 udev 服务去映射磁盘裸设备地址。使用 ASMFD之前需要卸载 ASMLIB 。
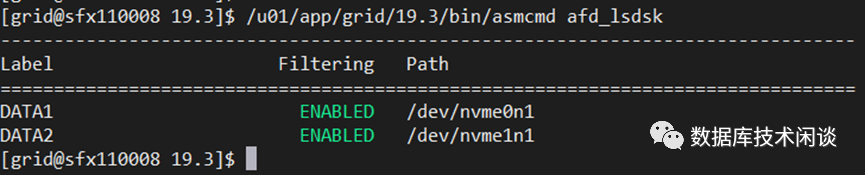
ASMFD的安装参考ORACLE官方文档即可,下面是精简的步骤
/u01/app/grid/19.3/bin/crsctl stop has -f/u01/app/grid/19.3/bin/asmcmd afd_configure/u01/app/grid/19.3/bin/crsctl start has/u01/app/grid/19.3/bin/asmcmd afd_dsset '/dev/nvme*'/u01/app/grid/19.3/bin/asmcmd afd_label DATA1 dev/nvme0n1/u01/app/grid/19.3/bin/asmcmd afd_label DATA2 dev/nvme1n1/u01/app/grid/19.3/bin/asmcmd afd_scan/u01/app/grid/19.3/bin/asmcmd afd_lsdsk
然后安装 ASM 实例,创建磁盘组,设置磁盘组的 THIN_PROVISIONED 属性。
alter diskgroup datadg1 set attribute 'thin_provisioned'='TRUE';
此后,如果有在ASM里大量删除文件。比如说删除了一个大的表空间、或者删除大量的归档文件。可以手动触发REBALANCE 操作释放空间。
alter diskgroup datadg1 rebalance with balance compact wait;
 得益于CSD可以查看实际的物理容量,通过对比可以看到ASM磁盘组开启精简模式后,再删除大量归档后做REBALANCE操作后释放了SSD物理容量(由于压缩比在2.73,CSD实际释放的逻辑空间约在400G以上)。
得益于CSD可以查看实际的物理容量,通过对比可以看到ASM磁盘组开启精简模式后,再删除大量归档后做REBALANCE操作后释放了SSD物理容量(由于压缩比在2.73,CSD实际释放的逻辑空间约在400G以上)。
其他空间技术简介
还有一个空间回收技术就是文件打洞,使用Linux的调用 fallocate,参数 FALLOC_FL_PUNCH_HOLE和FALLOC_FL_KEEP_SIZE。
示例:
//在4k偏移的位置上打一个12k大小的洞if(fallocate(fd,FALLOC_FL_PUNCH_HOLE|FALLOC_FL_KEEP_SIZE,4096, 4096*3)<0)
fallocate 也是一个linux命令。
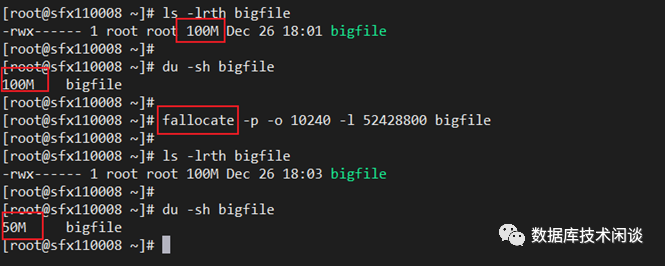
文件打洞后,文件大小不变,实际占用的物理容量却变少了。打洞会通知底层SSD释放对应的逻辑地址。
有关打洞的详细的研究可以参考这篇文章:深度剖析Linux CP 原理(附源码) (qq.com)
对于打洞的地址的读取默认都会返回0x0。尽管如此,全部写入0x0跟打洞还是有本质的区别。ASRU 那个方案不是打洞。
在MySQL 的透明页压缩方案里也用到打洞的方案。观察一个文件是不是用了打洞优化空间方案就比较它的文件大小和实际存储空间大小。
打洞的风险也是有的,那就是一旦后期真的需要这么多空间,有可能会分配不出来(因为物理空间让给其他应用了)。所以数据库的空间管理方案里通常默认不会使用打洞这个方案。一些虚拟机或者云数据库可能会用这个解决方案。
OceanBase的BLOCKFILE也是一种空间预分配机制,默认不使用稀疏文件格式, OceanBase 是LSM Tree,会经常性的做版本合并,内部会有大量新版本数据生成和老版本数据删除,释放的空间默认也不会通知存储释放,除非开启打洞参数_enable_block_file_punch_hole 。
最后总结一下。
ORACLE 表空间可以预分配,也可以动态分配空间,空间只增不减,除非主动发起文件收缩命令。ASM 也会自己管理空间,ASM内部不用的空间默认不会通知SSD,除非开启ASM磁盘组的精简配置属性(thin_provisioned)并结合 ASM AFD一起使用。
更多阅读
