




近日,爱分析联合 Kyligence 共同发布了中国首份指标中台市场研究报告。Kyligence 联合创始人兼 CTO 李扬在发布会上分享了对指标中台及其背后数据库的技术的思考,同时欢迎大家扫描下方二维码获取报告。

成立多年来,Kyligence 助力金融、零售、制造、互联网等行业的领先企业落地了指标中台,积累了丰富的指标中台建设和实践经验,我们也在把这项技术推广到更多的客户当中去。从技术角度来说,指标中台背后的技术其实经历了三个阶段,从最早的关系型数据库到多维数据库,再到我们今天提到的指标型数据库,接下来就给大家展开聊一聊我们对于这背后技术变迁的一些思考。
#01

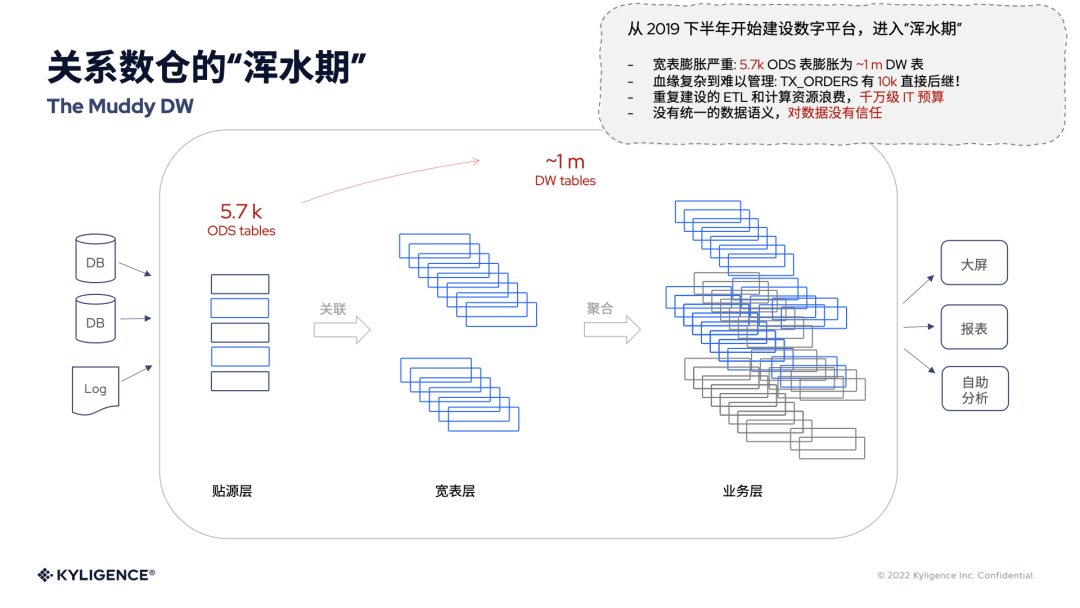
在这个客户的实践中,表的规模在这个过程中出现了指数级的增长,自从2019年开始建设数字平台之后,就经历了一段浑水期,因为有大量的表被不同的人以不同的目的创造出来,而这些表的血缘复杂到难以管理,效率管理也是高度滞后的,这也是为什么从5000多张表膨胀到100万张表这个庞大的级别。以血缘为例,一个典型的交易表 TX_ORDERS 的直接后继就有1万张表之多,这是非常可怕的爆炸式增长。
从这个实际案例中大家可以看出,这其中存在不少重复的数据管道的建设、计算资源的浪费,甚至涉及千万级的 IT 预算。正是因为这种混沌的数据状态,也使得公司上下对数据的信任度不高,接下来展开看看是什么造成了这种现象。
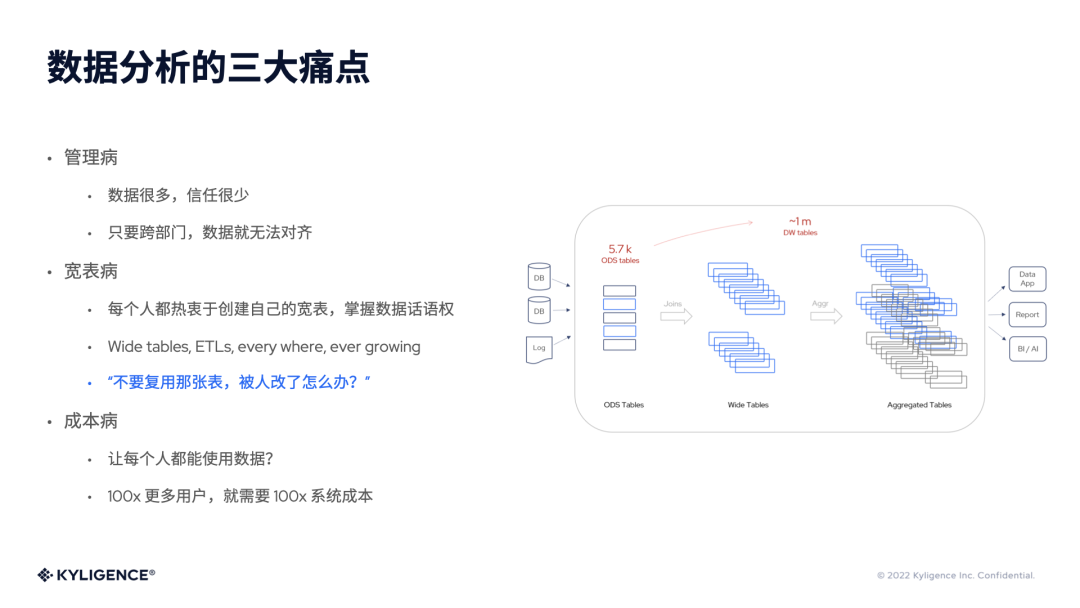
我们将其归纳成数据分析的三大痛点,第一点我们称之为“管理病”,公司上下数据很多,但是信任却很少。一旦跨了部门,数据口径就难以对齐,这个常见问题又源自于什么呢?那就是我们提到的“宽表病”,也就是因为公司希望用数据来解释每一个部门、小组的工作成绩,用数据来驱动业务。每个人、每个部门都希望掌握数据话语权,因此大家热衷于创建自己的表,使用自己的数据管道,而不是复用已有的表和数据。
而这就会导致成本问题,我们称之为“成本病”。如果每个人、每个部门都如此重复建设数据管道、创建自己的宽表,那大数据平台就会出现大量重复的建设。如果今天有50位数据分析师,而我们希望把它推广到5000位,也就是增长100倍,那么公司可能就要增加100倍的系统成本,因为会有更多的人来创建表,这就是很多企业早期自由增长式数据平台的样子。
#02
我们举个例子来看看多维数据库如何解决前面聊到的“宽表病”和“成本病”这两个问题。如下图所示,左侧是它的一个数据模型,有订单表、客户表、销售渠道这三个表;在公司有四个部门,分别是美国的销售团队、中国的销售团队和中国的市场营销团队和全球的财务团队,他们都要分析一些销售的营收结果,都和这三张表有关。
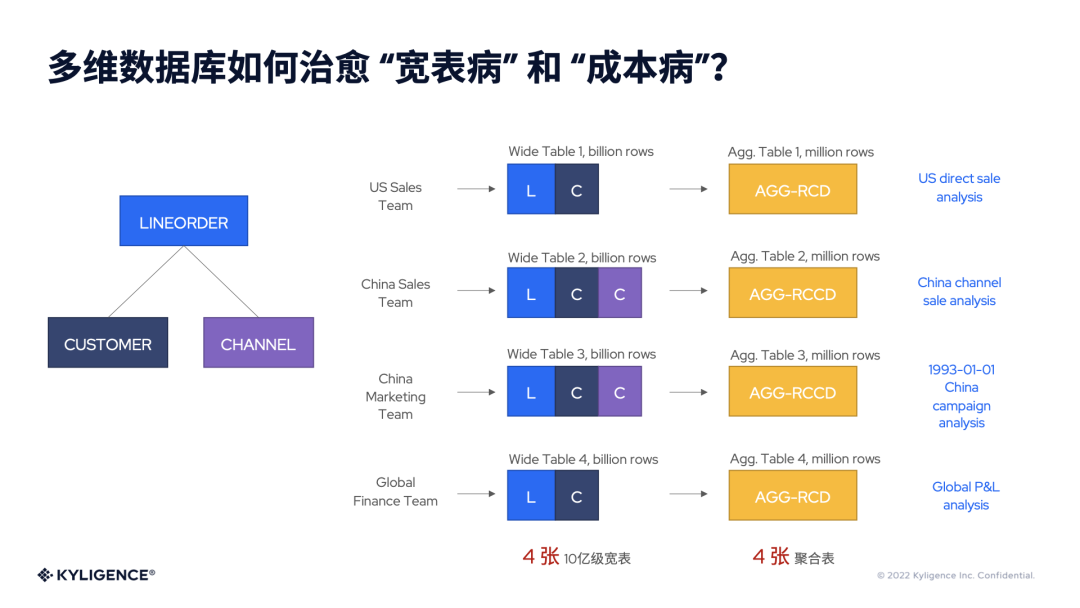
按照传统的关系型数仓的解决方法,每个团队它就会建立自己的表,所以我们看到四条链路都把前面的三张表做一些关联,而这又都是10亿级别的宽表,因为数据量比较大的关系,我们又会产生4张10亿级别的宽表,而10亿级别的表是难以做即席分析的。
业务人员往往又会根据这些表再创建一些聚合表,用于不同的分析场景,如美国的直销模式、中国的渠道销售模式、某个营销活动、财务的损益分析等。至此,按照传统模式,每四个团队都各自创建了四条链路,其中涉及到四张10亿级的宽表和四张聚合表,才能够完成他们的任务。
那么在同样场景下,使用多维数据库会发生什么?在多维数据库看来,营收是一个指标,而前面这四个团队所分析的场景是基于几个同样的维度的。比如营收额这个指标,和客户、地区、渠道、时间这四个维度有关,只要在多维数据库中创建这几个维度和度量,系统就会自动地发现它是属于同一个多维立方体,从而自动地把这些分析的需求创建在一个多维立方体里。
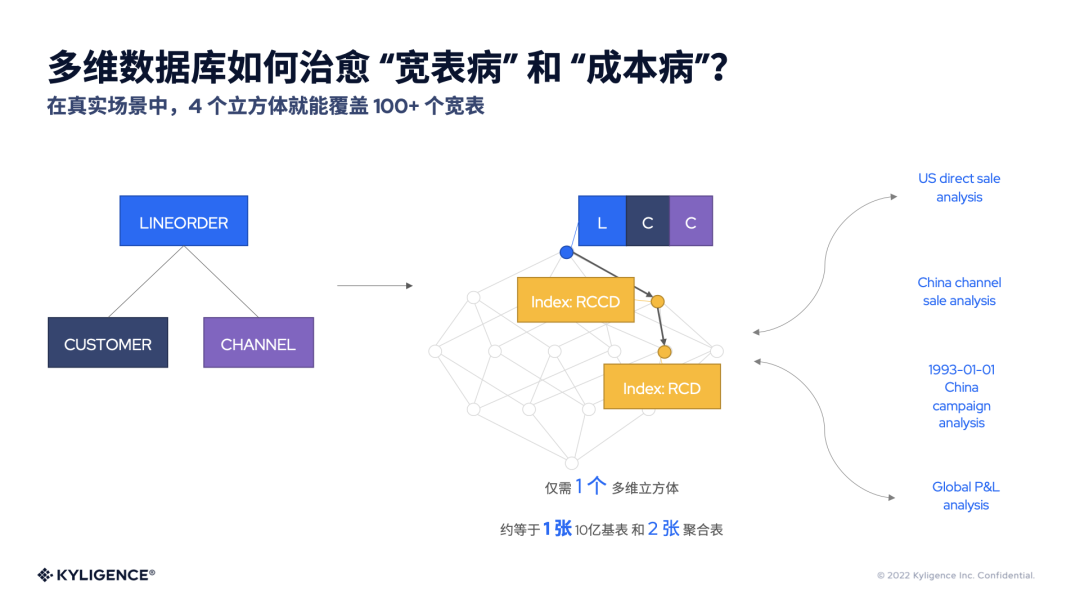
从计算资源和存储资源方面看,它大概约等于是一张10亿级别的宽表和两张聚合表。如上图所示,因为从维度和度量的角度来看,这四个部门分析的需求是重合的。而在多维数据库里系统会自动把它们归为重复的,完成一种类似于收纳箱一样的规整和整理的效果。从结果上,它既能满足四个分析场景,同时,存储和计算的成本又大大下降。
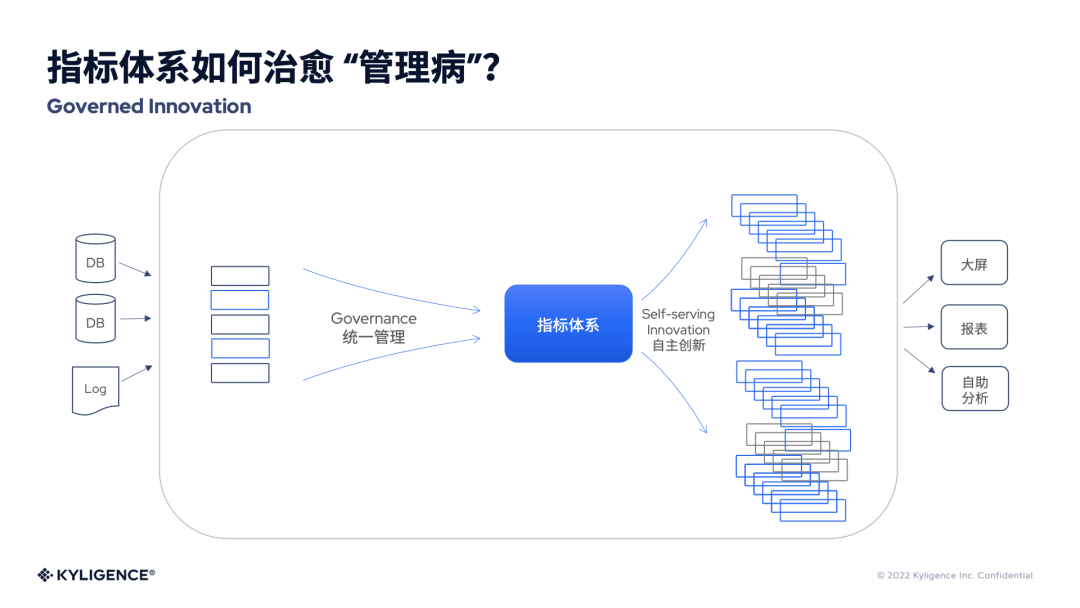
解决“管理病”就需要从更高的角度来看,我们先从指标体系谈起。除了上面说到的多维数据库在重复的指标和重复的维度可以做自动管理以外,业务本身是千变万化的,还是需要从一些体系和方法论方面的管理。一个比较理想的状态是,通过统一的管理可以形成一个标准的指标体系,同时在这个体系之上,又允许一定程度的自主创新,每个部门又可以在标准指标之上有自己的数据理解和展开。我们把这个统一管理和自主创新的结合叫作 Governed Innovation,指标体系在其中就扮演一个关键角色,而指标数据库就包含标准的指标体系和多维数据库的能力。
#03
在标准指标的右侧就是各部门自助创建的衍生指标,大家可以在标准的指标基础上,来增加自己对数据的理解,掌握对数据的控制权。当然,这些衍生指标是在标准的管理范围内来解释数据和展现成果。这里可以理解为,前半段有95%的预计算都发生在标准指标定义的过程中,而自主创新、比较灵活的衍生指标,大概占5% ,这一部分是需要在线的计算算力。这种充分预计算+少量在线计算的组合相较传统的计算方法效能就会高上非常多。
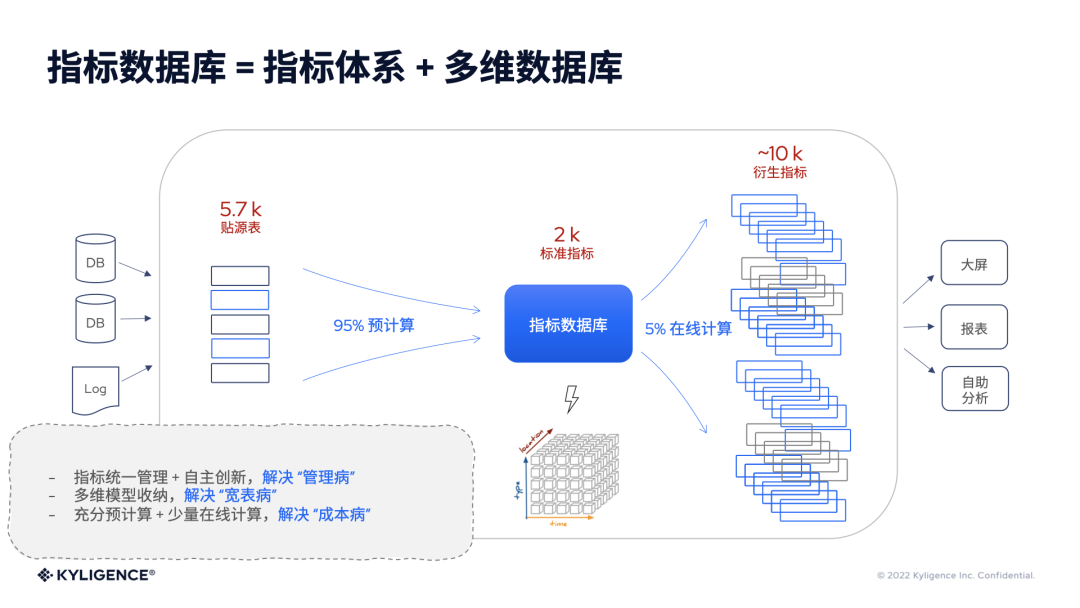
总结一下,在这样的设计里,具有统一的指标管理和一定程度的自主创新,来帮助企业实现 Governed Innovation,解决了“管理病”的问题;多维模型和多维数据库能够自动收纳重复的指标和维度,解决“宽表病”的问题;再加上充分的预计算和少量的在线计算组合,前期预计算的结果得到了充分的复用,同时计算结果也可以被自动地优化和收纳,从而达到了整体成本最优化,又解决了“成本病”的问题。
#04
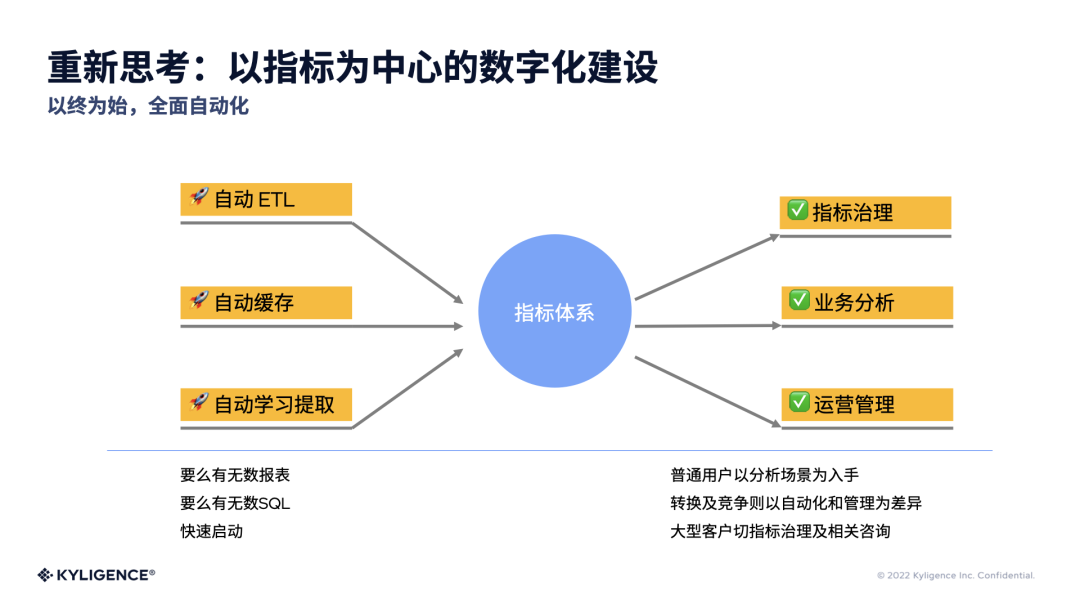
既然大家最后关注的还是指标,我们是不是可以把指标放到第一位?不从数据源、数据管道分析这个思路来看,而是以终为始,把业务放到第一位,先把指标体系定义好,然后再由一个“聪明的”计算机系统从指标体系反推企业到底需要怎样的 ETL、存储缓存,甚至自动学习的方法来改进这个指标体系。在这个过程中,在传统数据建设中,很多需要人来完成的部分其实都可以通过自动倒推完成的。
回想起 Gartner 此前的一篇报告指出,在未来的三到五年里边,可能有45%的数据管理和操作活动,会被计算机自动完成。而在这一整条数据分析链路里面,以终为始的思路来看,以指标体系来倒推前期的自动 ETL,自动的数据的存取和预处理是很可能被一个好的指标数据库来完成的。
以上就是我对数据库技术以及其如何支撑指标中台的一些思考。同时,作为一个技术供应商,Kyligence 为客户提供企业级指标中台产品及解决方案,非常欢迎大家来了解和免费试用。
如果大家对《中国指标中台市场研究报告》感兴趣,欢迎扫描下面二维码下载。
Kyligence 已服务中国、美国、欧洲及亚太的多个银行、证券、保险、制造、零售等行业客户,包括建设银行、浦发银行、招商银行、平安银行、宁波银行、太平洋保险、中国银联、上汽、Costa、UBS、MetLife 等全球知名企业,并和微软、亚马逊、华为、Tableau 等技术领导者达成全球合作伙伴关系。目前公司已经在上海、北京、深圳、厦门、武汉及美国的硅谷、纽约、西雅图等开设分公司或办事机构。
点击「阅读原文」了解更多
