




LF Edge eKuiper(由 EMQ 发起,现已捐献给 LF Edge 基金会)是 Golang 实现的轻量级物联网边缘分析、流式处理开源软件,可以运行在各类资源受限的边缘设备上。eKuiper 设计的一个主要目标就是将在云端运行的实时流式计算框架 (如 Apache Spark、Apache Storm、Apache Flink) 迁移到边缘端。eKuiper 参考了上述云端流式处理项目的架构与实现,结合边缘流式数据处理的特点,采用了编写基于源 (Source)、SQL (业务逻辑处理)、目标 (Sink) 的规则引擎来实现边缘端的流式数据处理。
社区站网址:https://ekuiper.org/zh
GitHub 仓库:https://github.com/lf-edge/ekuiper
本月 eKuiper 团队继续专注于 1.8.0 版本新功能的开发。我们重构了外部连接(source/sink) 的格式机制,更加清晰地分离了连接、格式和 Schema,同时支持了格式的自定义;受益于新的格式机制,我们大幅完善了文件源(file source)的能力,支持定时监控文件系统及各种格式的文件,并且采用流的方式消费文件系统数据;最后,我们增加了完整数据包括规则和配置的导入导出功能,支持节点的迁移。另外,我们也修复了一些问题,并发布到 1.7.x 版本中。
v1.8.0-alpha.3(https://github.com/lf-edge/ekuiper/releases/tag/1.8.0-alpha.2):包含 1.8.0 已开发完成的新功能
v1.7.4(https://github.com/lf-edge/ekuiper/releases/tag/1.7.4):包含 bug fixes
v1.7.5(https://github.com/lf-edge/ekuiper/releases/tag/1.7.5):包含 bug fixes
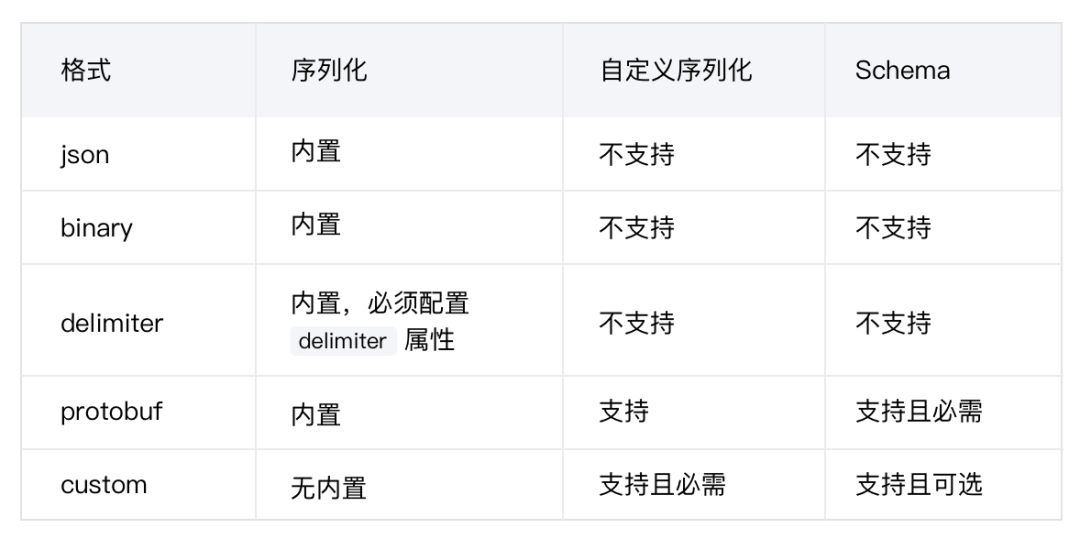
eKuiper 通过 source/sink 与外部系统进行连接、读入或写出数据。以 source 为例,每种类型的 source 读取数据时都需要经过连接(connect)和序列化(serialization)两个步骤。例如,MQTT source,连接意味着遵循 MQTT 协议连接 broker,而序列化则是将读取到的数据 payload 解析成 eKuiper 内部的 map 格式。
例如,创建 MQTT 类型的数据流时可定义各种不同的 payload 格式。默认的 JSON 格式:
CREATE STREAM demo1() WITH (FORMAT="json", TYPE="mqtt", DATASOURCE="demo")
MQTT 类型的数据流使用自定义格式,此时 MQTT 的 payload 中的数据应当使用自定义的格式:
CREATE STREAM demo1() WITH (FORMAT="custom", SCHEMAID="myFormat.myMessage", TYPE="mqtt", DATASOURCE="demo")
额外性能消耗。当前的 Schema 没有与数据原本的格式 Schema 关联,因此在数据解码之后,需要再额外进行一次 validation/转换;而且该过程基于反射动态完成,性能较差。例如,使用 Protobuf 等强Schema 时,经 Protobuf 解码之后的数据应当已经符合格式,不应再进行转换。 Schema 定义繁琐。同样无法利用数据本身格式的 Schema,而是需要额外配置。
GET /streams/{streamName}/schema
文件源
interval参数以定时拉取更新。同时增加了文件夹的支持,多种文件格式的支持和更多的配置项。
json:标准的 JSON 数组格式文件。如果文件格式是行分隔的 JSON 字符串,需要用 lines 格式定义。 csv:支持逗号分隔的 csv 文件,以及自定义分隔符。 lines:以行分隔的文件。每行的解码方法可以通过流定义中的格式参数来定义。例如,对于一个行分开的 JSON 字符串,文件类型应设置为 lines,格式应设置为 JSON。
CREATE STREAM cscFileDemo () WITH (FORMAT="DELIMITED", DATASOURCE="abc.csv", TYPE="file", DELIMITER=",", CONF_KEY="csv"
数据导入导出
GET data/export
POST data/import
POST data/import?stop=1GET data/import/status即将到来
下个月我们将继续进行 1.8.0 版本其他功能的开发,并重构文档,同时推进 Flow Editor 整合到 eKuiper manager 中。敬请期待。

