





用随机梯度下降来优化人生
—— 李沐

在《因果推断之Uplift Model | 入门篇》中,我们介绍了uplift模型可以用于预测营销对于用户响应的增益,并简要阐述了它的的学科背景、原理和三种建模方式——差分响应、类别转换和直接建模。本文将利用python现有的Pylift库,实现基于类别转换的Uplift Modeling,搭建包含环境配置、数据生成、特征选择、模型训练、模型评估在内的完整pipeline。
由于记录营销前后客户响应程度的开源数据很少,因此我们利用Pylift自带的函数来生成数据,与真实样本数据的训练效果会存在差距。
欢迎探讨指正!>.<
01
明其道
/ 基于类别转换的Uplift模型原理
上回说到,uplift模型的目标是预测营销对客户响应的增益,而难点在于对同一个体营销和不营销的结果不能同时观测。对此,类别转换的解决思路是将营销结果(outcome:0/1)转换为如下矩阵:
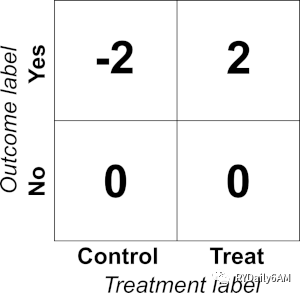
转换的关系式如下(Y*为转换后的变量,Y为营销结果,W为是否干预,p为营销组占比):
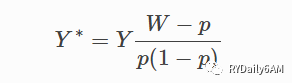
之所以做这种转换,是因为根据推导可知对Y*的预测结果即为对uplift的预测结果,uplift问题被转化为对Y*的回归问题。推导过程如下:
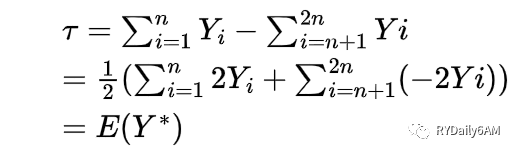
这样一来,预测Uplift的难题就转化为了简单的两个步骤:(1)将Y转换为Y*(2)对新响应变量Y*进行回归预测。一般使用Python的pylift库,将营销结果进行转换,再对转换后的变量进行回归预测。
02
利其器
/ Python开发环境搭建
知道原理后,下面我们可以开始动手实现了。配置python开发环境是进行python项目开发的第一步,主要分成以下三步:
✔解释器配置:虽然解释器可在python官网下载,但大多数的库环境配置工具与编辑器会自带python解释器,而python依赖开源库进行开发的特点也会导致后续的使用中出现依赖项冲突的问题。因此建议先安装anaconda,并选择下载python解释器,在配置完环境变量后便设置了初始开发环境。
✔代码编辑工具:主要分为「编辑器执行式」与「命令行交互式」。前者例如visual studio code、pycharm,其主要优点在于提供了集成度较高的书写环境,代码提示、调试等功能较为全面,但每一次执行都是在主函数中从头至尾运行得到的结果,适用于大型项目的开发。后者例如jupyterlab,优点是可以按照代码块的方式分段运行程序并得到相应的反馈。建议根据实际情况选择编辑工具。
✔库环境配置:可利用anaconda创建虚拟环境,并利用pip指令进行所需的包下载与版本管理。pip默认的下载源通常有网速不稳定的问题,可以在C盘用户文件夹下创建pip文件夹,并在其中创建pip.ini文件,编辑以下字段并保存:
[global]index-url = https://pypi.tuna.tsinghua.edu.cn/simple[install]trusted-host = pypi.tuna.tsinghua.edu.cn
以上示例是将pip下载源换为清华源,也可将其换为简书、阿里等国内源。
本次建模先在anaconda中配置环境,下载pylift库及其依赖项,然后就开始在jupyterlab中进行下面的开发啦。
03
善其事
/ 模型搭建
STEP1 数据生成(如有可用的样本数据则不需要这一步):由于记录营销干预前后客户响应程度的开源数据很少,这次利用pylift自带的数据生成函数dpg,生成特征范围在[0, 1]且符合正态分布的数据,包含特征(features, 符号为X),干预量(treatment, 符号为W),结果(outcome, 符号为Y)。
import numpy as npimport matplotlib.pyplot as pltimport pandas as pdimport pyliftimport xgboost as xgbfrom sklearn.ensemble import RandomForestRegressorfrom pylift import TransformedOutcomefrom pylift.generate_data import dgp#生成训练数据集dfdf = dgp(N=10000, n_features=3, discrete_outcome=True) #设置特征数量为3个,outcome是是离散型,数据量、treatment分布等其他参数都按照默认值设置df
向下滑动查看:样本数据示例
由于dpg产生的特征数据是随机生成的,各特征值与其对应的结果间几乎是杂乱无章的排列。为了后面的模型结果更好理解,我们将随机生成的数据人为地调整成更接近现实中「营销人群四象限」的人群分布状况,这里将第0维度的特征设置成与treatment强相关的数据分布。如使用真实营销数据建模则不需要以下步骤。
df['Outcome'] = df.apply(lambda x: 0.0 if x['Treatment'] and x[0] < 0.5 else x['Outcome'], axis=1)df['Outcome'] = df.apply(lambda x: 0.0 if (not x['Treatment']) and x[0] > 0.5 else x['Outcome'], axis=1)
STEP2 类别转换:这里我们利用pylift中的TransformedOutcome函数对outcome变量进行转换,再对转换后的变量进行回归预测。
##test_size控制测试集比例;##sklearn_model控制所使用的模型(默认使用xgboost中的树模型,也可以使用sklearn库的模型);##scoring_method,控制评价机制,参数值可选qini,aqini,cgains(默认);df_transform_RF = TransformedOutcome(df, col_treatment='Treatment', col_outcome='Outcome', stratify=df['Treatment'],test_size=0.2,col_transformed_outcome='TransformedOutcome', sklearn_model=RandomForestRegressor)
df_transform_RF.NIV(feats_to_use=None, n_bins=10, n_iter=3)
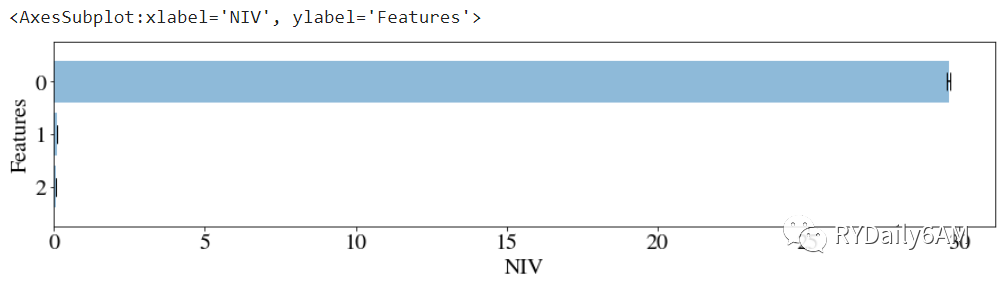
STEP4 模型拟合:pylift较好地复用了sklearn库的超参数搜索接口,因此可以利用超参数搜索函数选定不同的参数进行模型训练,并利用搜索得到的最优超参数组合进行模型创建。超参数搜索主要可分为GridSearch与RandomizedSearch方法。
✔GridSearch:通过interval划分,选取网格点上的参数进行实验,最终选取最优结果;
✔RandomizedSearch:通过等概率采样或给定分布的采样选取参数组合。GridSearch只能选取网格点上的参数,参数空间上排列规律相同,有时候不利于找到局部最优的参数组合,RandomizedSearch一定程度上克服了这一问题。
❌一个bug:在选用默认的XGBRegressor作为模型时,模型参数不能设置初始值,在参数搜索后出现模型参数为None的情况。没找到解决方法,所以尝试使用RandomForest训练。
df_transform_RF.randomized_search(param_distributions={'max_depth': range(1,80), 'min_samples_split': range(1,500)}, n_iter=10)
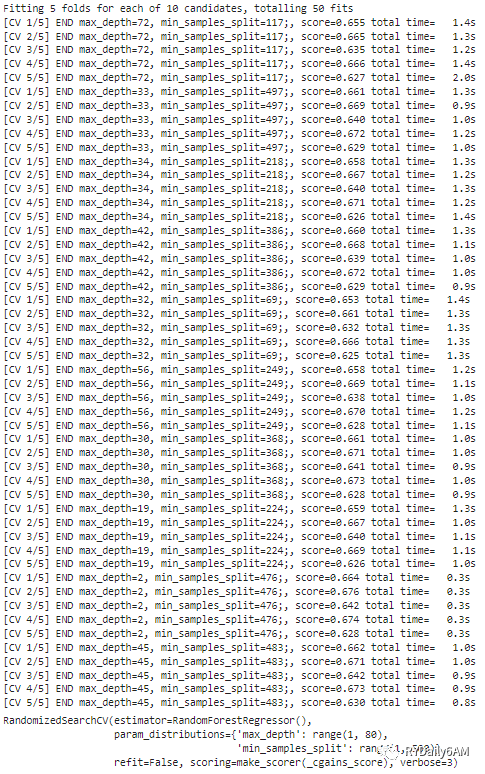
向下滑动查看:超参数搜索结果示例
df_transform_RF.rand_search_.best_params_df_transform_RF.fit(**df_transform_RF.rand_search_.best_params_)

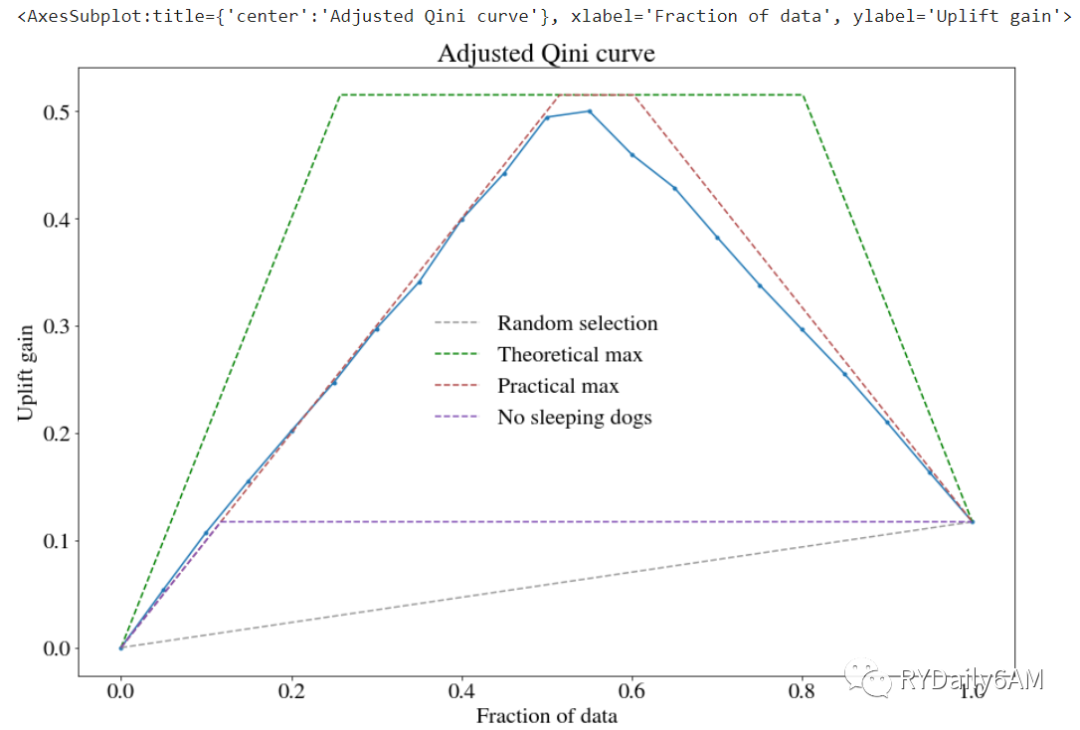
STEP5 模型评估:pylift提供qini, aqini, Cumulative Gain, Cumulative Uplift等多种曲线以评估uplift模型的效果,评估指标的含义可参见上一篇。主要用到以下函数:
✔shuffle_fit函数:可以将训练集与验证集打乱多次得到曲线簇,并通过plot函数的show_shuffle_fits参数控制shuffle曲线的显示,show_noise_fits可以控制误差拟合曲线的显示;
✔plot函数:通过plot_type参数控制图像类型,可选qini, aqini, cgains, cuplift参数;
df_transform_RF.shuffle_fit(iterations=5, plot_type='cgains')df_transform_RF.noise_fit(iterations=5)df_transform_RF.plot(plot_type='cgains', show_noise_fits=True,show_shuffle_fits=True, shuffle_avg_line_kwargs={'color':[1,0,0]})
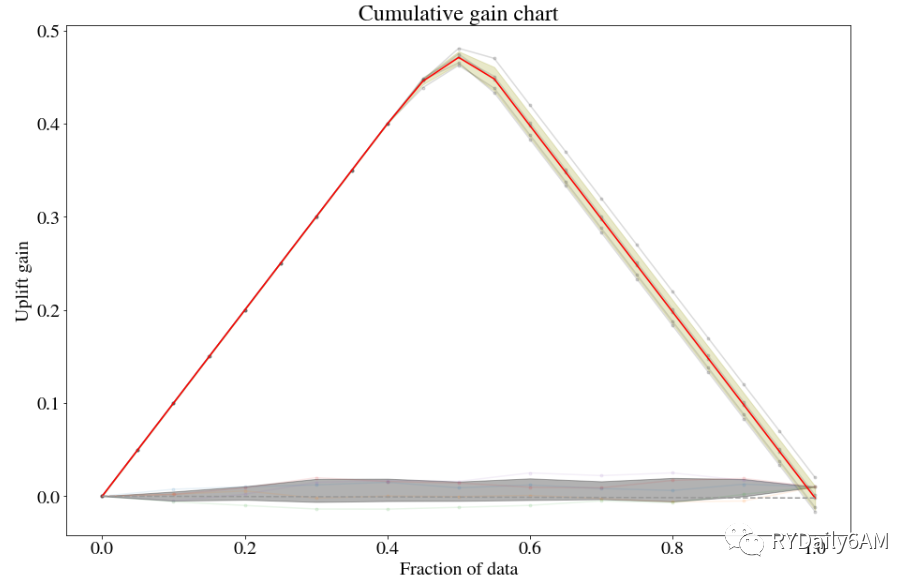
累积增益曲线
df_transform_RF.plot(plot_type='aqini', show_theoretical_max=True+, show_practical_max=True, show_no_dogs=True)
最
后
Pylift库的使用感受
在当前Uplift Model还没有很成熟和普及的情况下,Pylift库为我们提供了一个包含数据生成、特征选择、模型训练、评估的完整流程,且由于其支持Sklearn的大部分模型,所以比较好上手。
但是,Pylift库的缺陷也很明显。一是,其底层是基于类别转换(Class Transform)实现uplift预测,不支持其他方法,拓展性差。二是,其函数接口比较封闭,不能自定义参数。三是,官方文档描述不清晰,想要深究原理需要自己扒源代码。
本文中也提到了很多待解决的问题,希望找有经验有兴趣的朋友聊聊~
💡下期预告:《因果推断之Uplift Model | CausalML实战篇》,我们将聊聊基于树模型的Uplift的直接建模法,相比于Pylift更丰富和主流,敬请期待~
Reference
1. Causal Inference and Uplift Modeling: A review of the literature
2. Pylift’s Document
3. niv: Adjusted Net Information Value
