排行
数据库百科
核心案例
行业报告
月度解读
大事记
产业图谱
中国数据库
向量数据库
时序数据库
实时数据库
搜索引擎
空间数据库
图数据库
数据仓库
大调查
2021年报告
2022年报告
年度数据库
2020年openGauss
2021年TiDB
2022年PolarDB
2023年OceanBase
首页
资讯
活动
大会
学习
课程中心
推荐优质内容、热门课程
学习路径
预设学习计划、达成学习目标
知识图谱
综合了解技术体系知识点
课程库
快速筛选、搜索相关课程
视频学习
专业视频分享技术知识
电子文档
快速搜索阅览技术文档
文档
问答
服务
智能助手小墨
关于数据库相关的问题,您都可以问我
数据库巡检平台
脚本采集百余项,在线智能分析总结
SQLRUN
在线数据库即时SQL运行平台
数据库实训平台
实操环境、开箱即用、一键连接
数据库管理服务
汇聚顶级数据库专家,具备多数据库运维能力
数据库百科
核心案例
行业报告
月度解读
大事记
产业图谱
我的订单
登录后可立即获得以下权益
免费培训课程
收藏优质文章
疑难问题解答
下载专业文档
签到免费抽奖
提升成长等级
立即登录
登录
注册
登录
注册
首页
资讯
活动
大会
课程
文档
排行
问答
我的订单
首页
专家团队
智能助手
在线工具
SQLRUN
在线数据库即时SQL运行平台
数据库在线实训平台
实操环境、开箱即用、一键连接
AWR分析
上传AWR报告,查看分析结果
SQL格式化
快速格式化绝大多数SQL语句
SQL审核
审核编写规范,提升执行效率
PLSQL解密
解密超4000字符的PL/SQL语句
OraC函数
查询Oracle C 函数的详细描述
智能助手小墨
关于数据库相关的问题,您都可以问我
精选案例
新闻资讯
云市场
登录后可立即获得以下权益
免费培训课程
收藏优质文章
疑难问题解答
下载专业文档
签到免费抽奖
提升成长等级
立即登录
登录
注册
登录
注册
首页
专家团队
智能助手
精选案例
新闻资讯
云市场
微信扫码
复制链接
新浪微博
分享数说
采集到收藏夹
分享到数说
举报
首页
/
从Hash Join的执行计划的细节中能看到点啥
从Hash Join的执行计划的细节中能看到点啥
白鳝的洞穴
2022-12-29
735
HASH JOIN是大数据量表连接中最为常用的方式,与最为常用的NESTED LOOP相比,其应用场景不同。对于两张表的连接,NESTED LOOP适合于类似查电话号码的应用场景,如果领导给你一张清单,让你去查一下几家企业的电话号码,那么你要做的是找到一本电话号码本,根据公司名称的索引,挨个查一遍,很快就可以完成了。这种方式就是著名的NESTED LOOP,通过数个快速的循环,完成两个行源的关联操作(待查清单,电话号码簿)。
如果这个任务改一下,领导给你的清单上有几万家企业,那么我们还这么一条条的去查,那不傻了。这时候,就不适合用NESTED LOOP循环了,HASH JOIN是比较快速的解决方法。很多SQL的执行计划出现错误,有很大一部分就是选择错误使用了NESTED LOOP和HASH JOIN。因此现在一些CBO的优化器中,都有针对NESTED LOOP和HASH JOIN的主动纠偏技术。Oracle 19C的可调节执行计划主要就是在执行NESTED LOOP的过程中一旦发现循环数量超出评估预期,则可以动态改为HASH JOIN。
刚开始就有点扯远了,今天我们的重点不是讨论NL和HASH JOIN的差异,而是带大家看看PG数据库的HASH JOIN执行计划中的一些容易被忽略的点,在查看执行计划的时候,如果能够比较好的抓住这些关注点,对于SQL优化来说很有帮助。
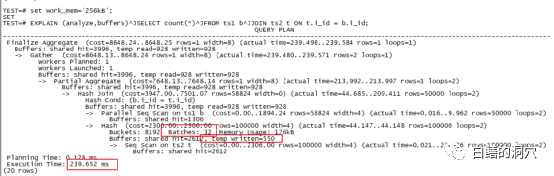
可能有朋友要说了,反正都是HASH JOIN,执行计划都差不多,有啥可看的。那么我们来看看上面的执行计划里的红框里的内容吧,Batches :32,这个是啥意思?如果你以前是Oracle DBA,那么优化排序、one-pass 排序,multi-pass排序的概念应该还有印象吧。当需要做排序或者HASH TABLE的数据量太大,超出了SORT AREA SIZE的限制,那么这次排序/HASH join就无法一次完成,必须切分为多个分区,一个个的完成。在PG的HASH JOIN里,就是把HASH JOIN切分为多个BATCHES。因为某个BATCH完成后需要暂存在临时文件中,因此遇到这种情况我们一般都可以看到temp written这个内容,这部分内容我也用红框标注出来了。
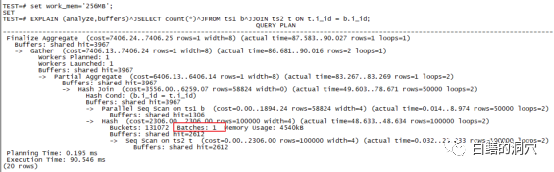
这种排序区不足导致的问题会带来什么样的性能问题呢?我们来看这个例子,BATCHES:1,也就是无需通过分区完成,此时使用了4540KB的WORK_MEM。实际上我给大家演示这个案例的时候,第一个例子用了256KB的work_mem设置,当然无法满足4M多的内存需求了。而第二个例子我使用了一个极大的work_mem(256MB),当然实际上的内存使用以执行计划中的为准。一次性在内存中完成HASH JOIN的好处是什么呢?当然是执行效率,我们可以看出第二个执行只用了90毫秒,而分裂为32个BATCH的执行花了239毫秒。
看到这里可能有朋友要说了,既然效果那么好,那么我们把WORK_MEM参数设的足够大不就行了。实际上设置过大的WORK_MEM也是存在隐患的。如果我们的物理内存不是很大,那么设置过大的WORK_MEM可能导致极端情况下,物理内存过度消耗而导致更严重的问题。
WORK_MEM参数是可会话级动态设置的,如果我们的某些要做大型排序或者HASH JOIN的SQL能够在应用层面做设置,执行大型SQL的时候设置一个较大的值,SQL执行完毕RESET一下参数,这样WORK_MEM的使用效率是最高的。否则我们为了满足大型SQL的需求,就需要设置一个做大值。当然虽然我们设置了WORK_MEM并不一定就会消耗那么多的内存,不过活跃会话数*WORK_MEM这个数字还是需要关注的,确保我们的物理内存有那么多的空闲可用(参考可用内存,而不是FREE内存)是十分必要的。如果我们不确定系统最大的内存使用量,并且物理内存比较紧张,那么设置大一点的SWAP是十分必要的,在极端情况下可以确保系统不会因为OOM而出大问题。
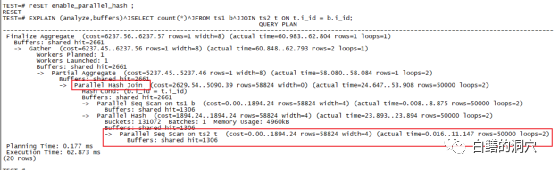
上面的这个执行计划也是我们经常看到的,PG数据库支持并行HASH JOIN,并且默认是打开的。如果我们的系统中的CPU资源是充足的,那么enable_parallel_hash参数确保打开状态就行了。并行HASH JOIN可以通过过parallel seq scan和parallel hash join两种机制来进一步提高HASH JOIN的性能。我们可以看到,通过并发,这个SQL的执行效率进一步的提升了。
不过任何事情都是有利有弊,如果你的服务器的CPU资源十分紧张,那么过多的并行HASH JOIN可能会导致你的CPU资源经常出现不足,引发其他问题。如果存在这种情况,那么关闭并行HASH JOIN,让每个HASH JOIN变得略微慢一点,但是确保CPU资源不过载,也是一种策略。
work
hash
物理内存
文章转载自
白鳝的洞穴
,如果涉嫌侵权,请发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
评论
领墨值
有奖问卷
意见反馈
客服小墨