




将历史数据导入数据库是进行数据查询、计算和分析的基础。我们搜集了用户在数据导入实操中常见的各类问题,以 CSV 格式的文件为例,为大家整理了金融逐笔数据导入的完整操作步骤。
准备工作示例
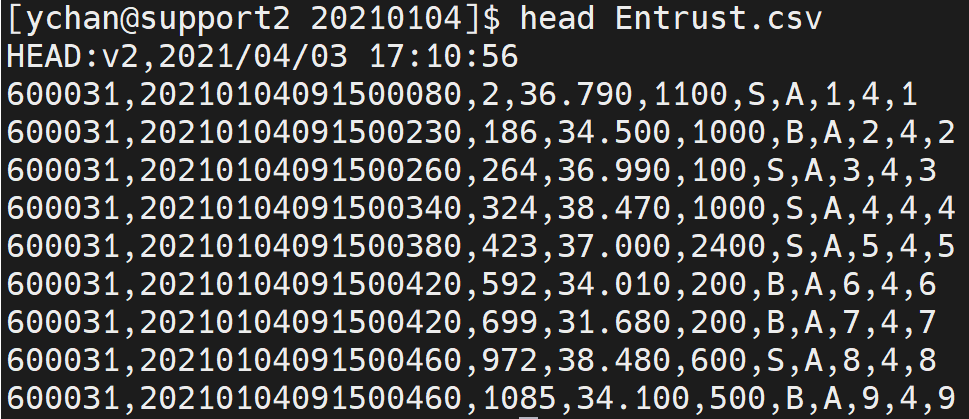
第一行是文件说明,后续各种读取都需要跳过这一行; 从第二行开始是数据,没有列名,在建表时需要根据数据的说明文档定义字段名称和字段类型。
数据导入与清洗转换
db = database("dfs://sh_entrust")def transType(mutable memTable){return memTable.replaceColumn!(`col0,string(memTable.col0)).replaceColumn!(`col1,datetimeParse(string(memTable.col1),"yyyyMMddHHmmssSSS")).replaceColumn!(`col5,string(memTable.col5)).replaceColumn!(`col6,string(memTable.col6))}filePath = "/home/ychan/data/loadForPoc/SH/Order/20210104/Entrust.csv"loadTextEx(dbHandle = db, tableName = `entrust, partitionColumns = `col1`col0, filename = filePath, skipRows = 1,transform = transType)
核心代码中,使用了 loadTextEx 函数,其中 transform 参数引用了 transType 函数定义,其作用是数据清洗和类型转换。
def transType(mutable memTable){return memTable.replaceColumn!(`col0,string(memTable.col0)).replaceColumn!(`col1,datetimeParse(string(memTable.col1),"yyyyMMddHHmmssSSS")).replaceColumn!(`col5,string(memTable.col5)).replaceColumn!(`col6,string(memTable.col6))}
(2)在 CSV 文件的基础上增加列
def addCol(mutable memTable,datePara){update memTable set date = dateParareturn memTable}
(3)过滤无效数据
def fliterData(mutable memTable){return select * from memTable where price > 0}
(4)转换字符编码
def addCol(mutable memTable){return mutable.replaceColumn!(`custname,toUTF8(mutable.custname,`gbk))}
(5)导入部分列
def partCol(mutable memTable){return select [需要的部分列名] from memTable}
常见问题
问
只提交了一个文件的导入,长时间执行不完,硬盘也没有写入,这是什么原因?
答
因为单个 CSV 文件太大,缓存不够用。先把 OLAPCacheEngineSize 和 TSDBCacheEngineSize 两个参数的值修改为大于 CSV 文件的大小,再重启系统即可。
问
执行过程中,报 out of memory 错误,怎么处理?
答
1)如果使用的是社区版本 license,请联系负责支持的销售人员,获取试用版本 license。2)查看 maxMemSize 参数的配置是否远小于系统内存,建议配置为系统内存的80%。3)检查 workerNum 和 localExecutors 配置,合理配置值的计算方法为:可用内存除以单个文件大小向下取整得到 workerNum 的值,localExecutors 的值为 workerNum 减 1。
问
nsf 系统导入时,报 Bad file descriptor 错误,怎么解决?
答
nfs 文件需要用 v3 版本,并设置 local_lock 参数为 all 的方式进行挂载。
问
数据如何去重?
答
建表时指定 keepDuplicates 参数的值可以去重,提供以下选项:
ALL:保留所有数据
LAST:仅保留最新数据
FIRST:仅保留第一条数据
Explore More




