




我们在上面一篇文章中介绍了排序算法的一些基本概念和知识点。大家应该已经非常清楚排序算法可以解决什么问题,可以用在哪些推荐场景了。上一章也对排序算法做了一个简单的说明性介绍,从本章开始我们会花3章的篇幅来介绍具体的排序算法的实现原理。本章我们先介绍最简单、最没有机器学习含量的规则策略排序方法。

11.1 多种召回随机打散
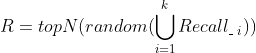
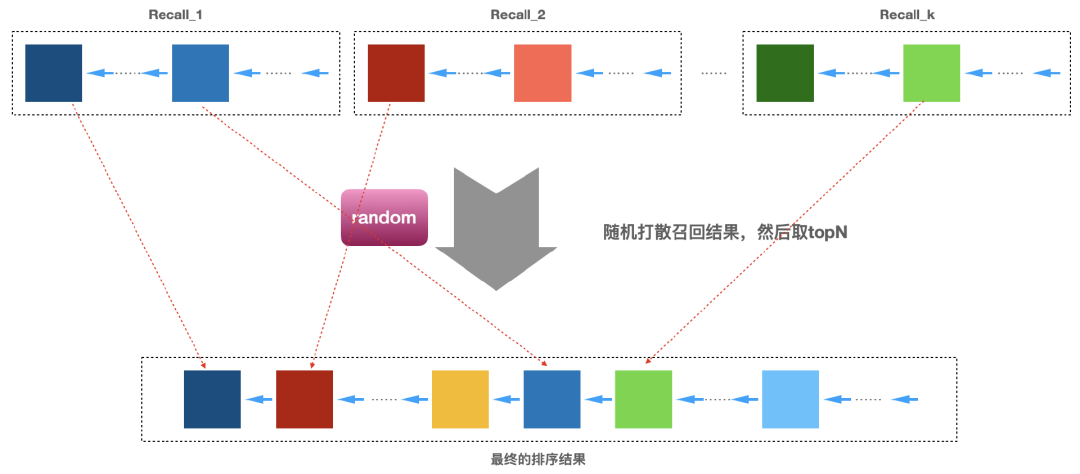
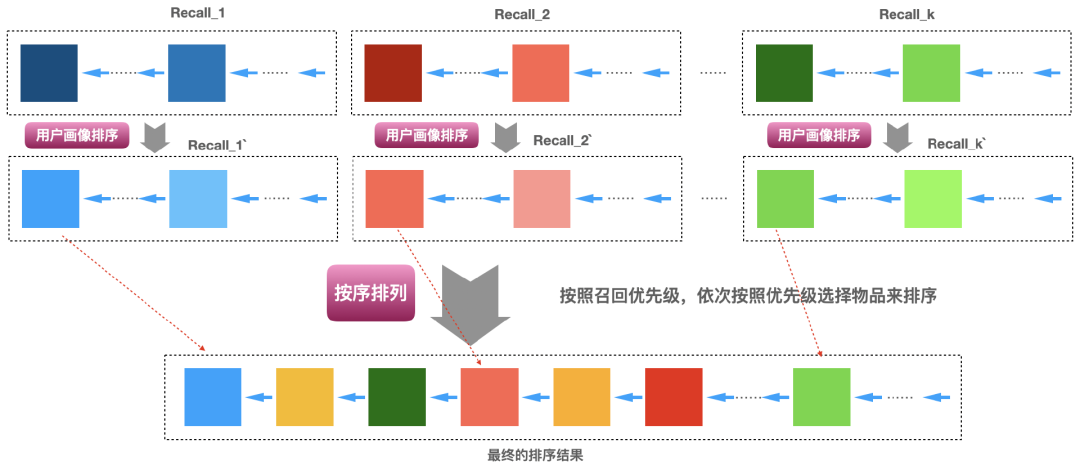
11.2 按照某种秩序排列
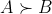 意思是A的优先级大于B):
意思是A的优先级大于B):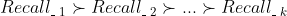
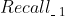 、
、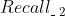 、... 、
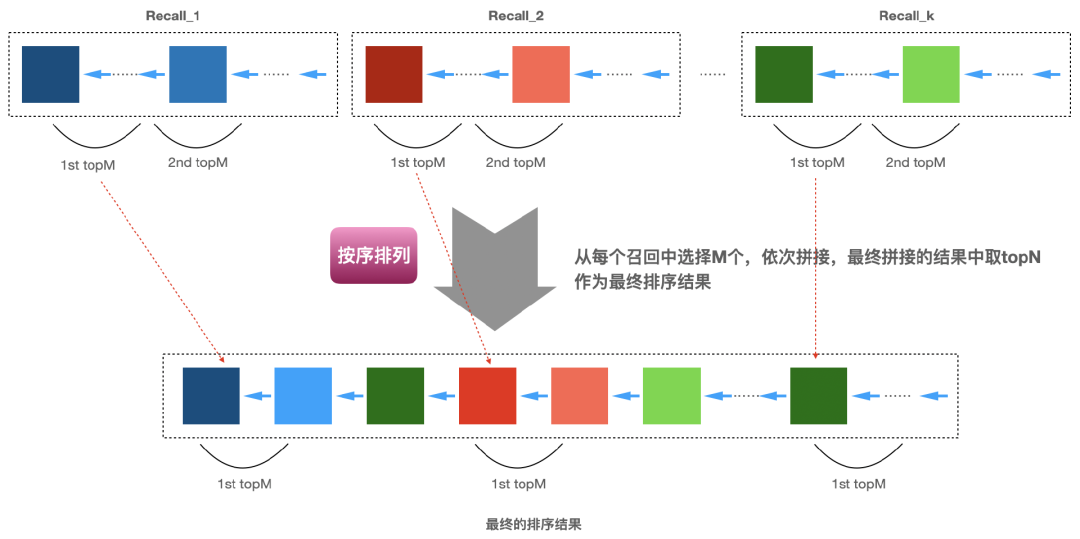
、... 、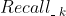 中选择1个来排列。第一轮选择好了之后,又开始按照 、 、... 、的顺序选择,直到选择的数量凑足N个就完成了,下面图3即说明了这个实现的过程。具体各个召回算法怎么排定优先级,可以有很多方式,比如基于业务的经验,基于运营需要,基于召回算法的效果(比如矩阵分解召回的效果好于item-based召回、item-based召回的效果好于热门召回)等。
中选择1个来排列。第一轮选择好了之后,又开始按照 、 、... 、的顺序选择,直到选择的数量凑足N个就完成了,下面图3即说明了这个实现的过程。具体各个召回算法怎么排定优先级,可以有很多方式,比如基于业务的经验,基于运营需要,基于召回算法的效果(比如矩阵分解召回的效果好于item-based召回、item-based召回的效果好于热门召回)等。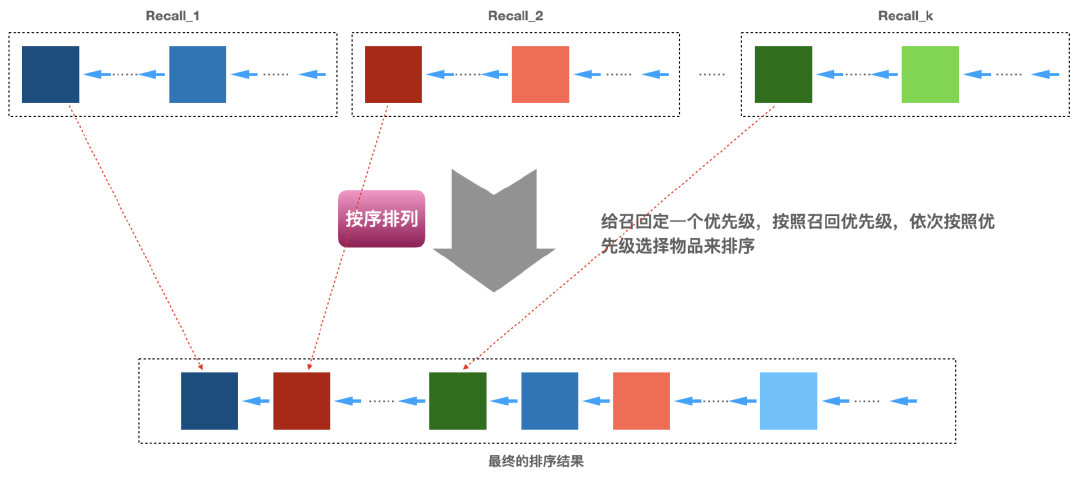
11.3 召回得分归一化排序
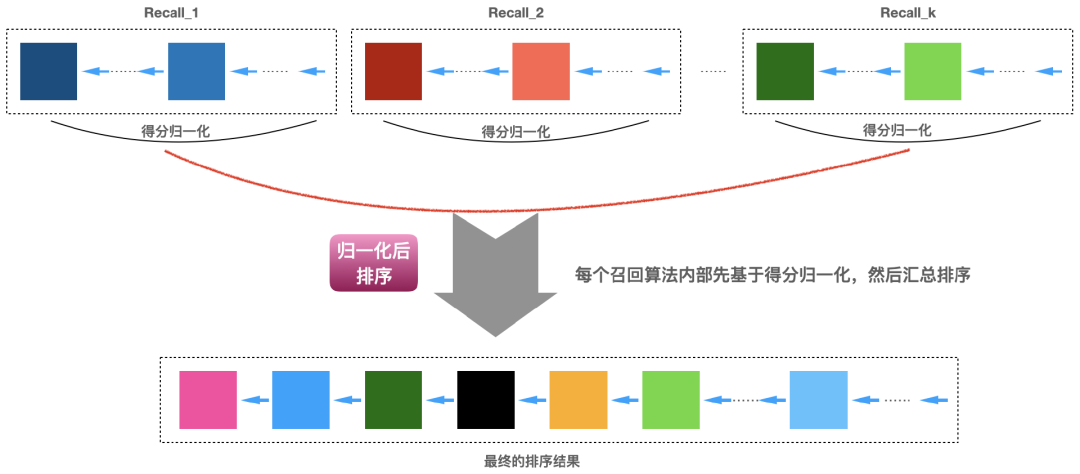
min-max归一化
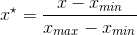
分位数归一化
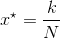
正态分布归一化
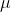 和标准差
和标准差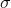 ,再采用下式来进行归一化。
,再采用下式来进行归一化。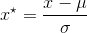
11.4 匹配用户画像排序
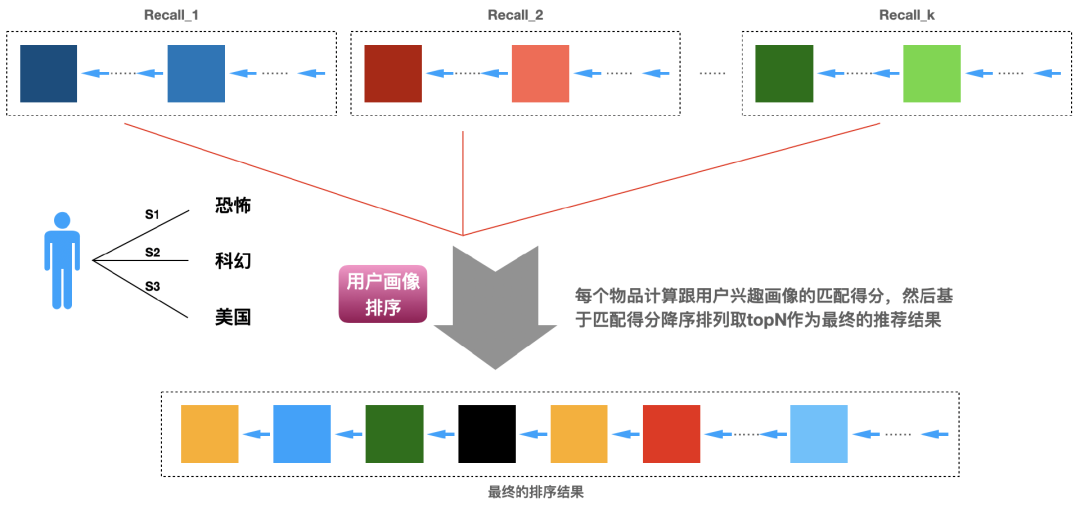
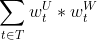 ,这里
,这里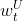 是用户U的兴趣标签t的权重,
是用户U的兴趣标签t的权重,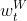 是物品W的标签t的权重(如果物品的标签没有权重,那么可以是1)。
是物品W的标签t的权重(如果物品的标签没有权重,那么可以是1)。11.5 利用代理算法排序
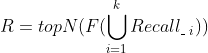
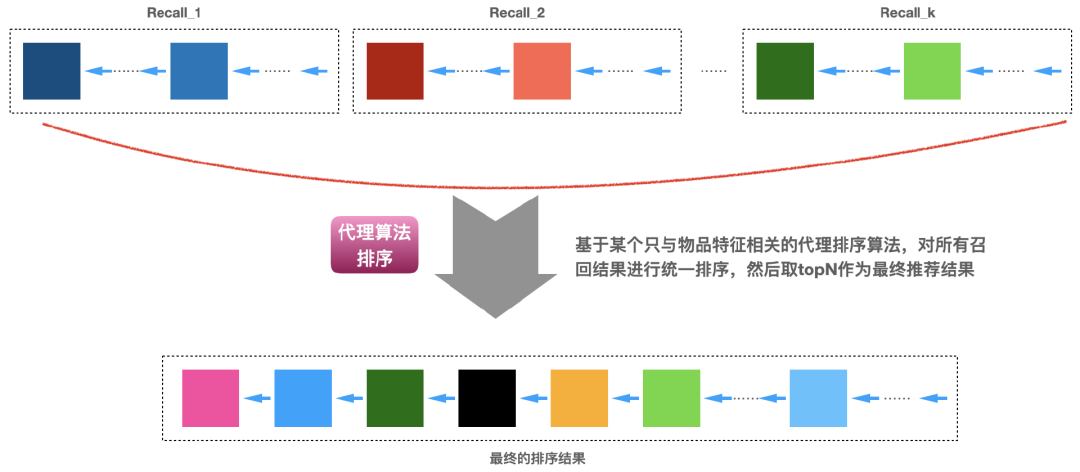
11.6 几种策略的融合排序
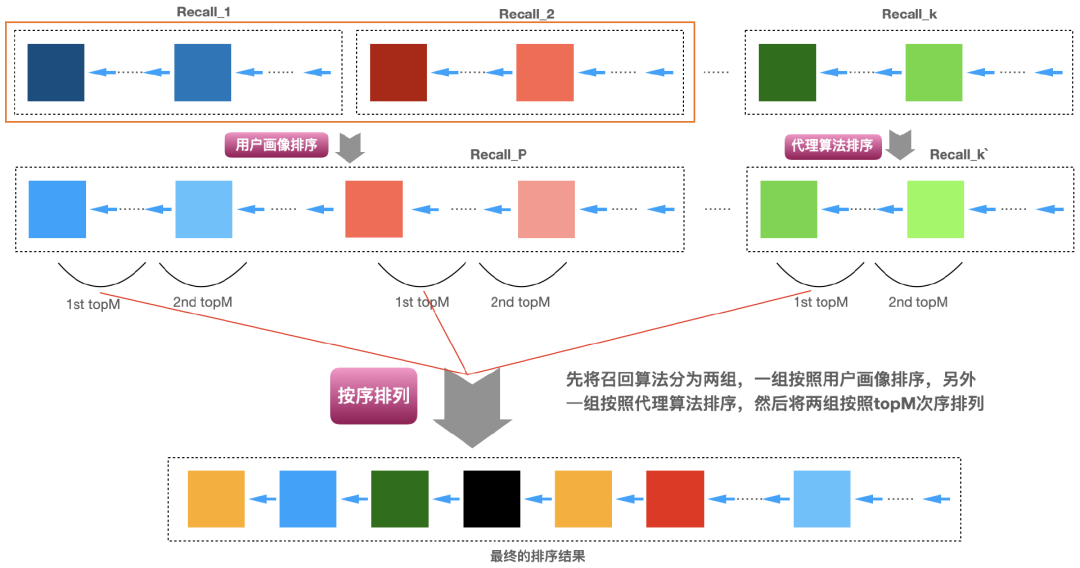
总结

文章转载自数据与智能,如果涉嫌侵权,请发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
