




摘要:本文整理自阿里云 Flink 存储引擎团队负责人,Apache Flink 引擎架构师 & PMC 梅源在 FFA 核心技术专场的分享。主要介绍在 2022 年度,Flink 容错 2.0 这个项目在社区和阿里云产品的进展,内容包括:
Flink 容错恢复 2.0 项目简介及思考
2022 年度 Flink 容错 2.0 项目进展
Tips:点击「阅读原文」查看原文视频&演讲 ppt
Flink 容错恢复 2.0 项目简介及思考
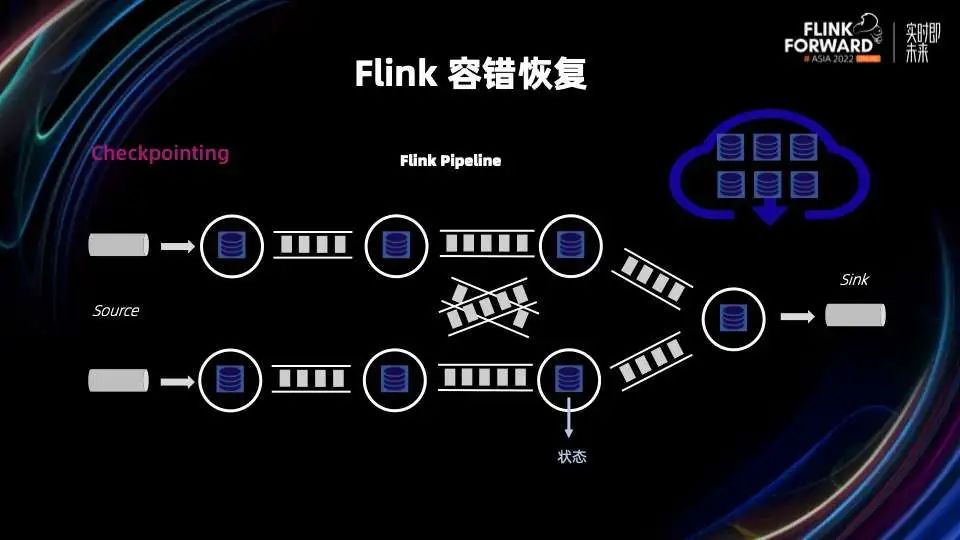
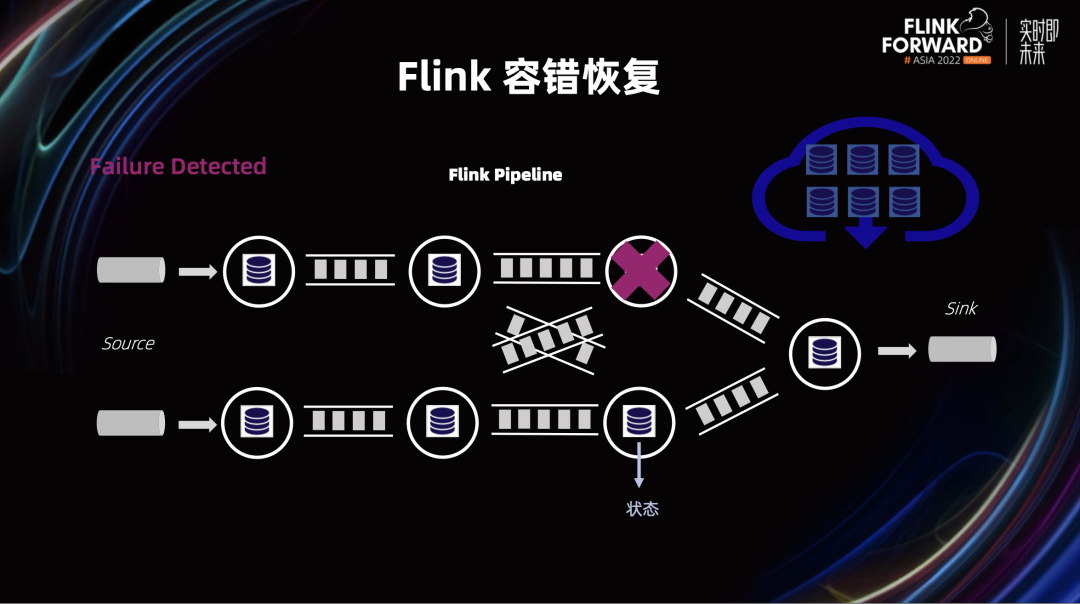
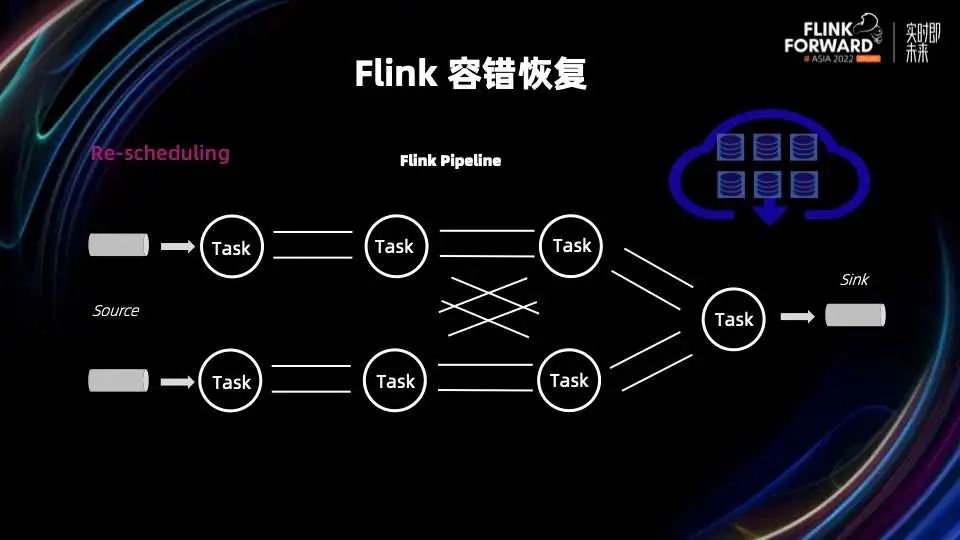
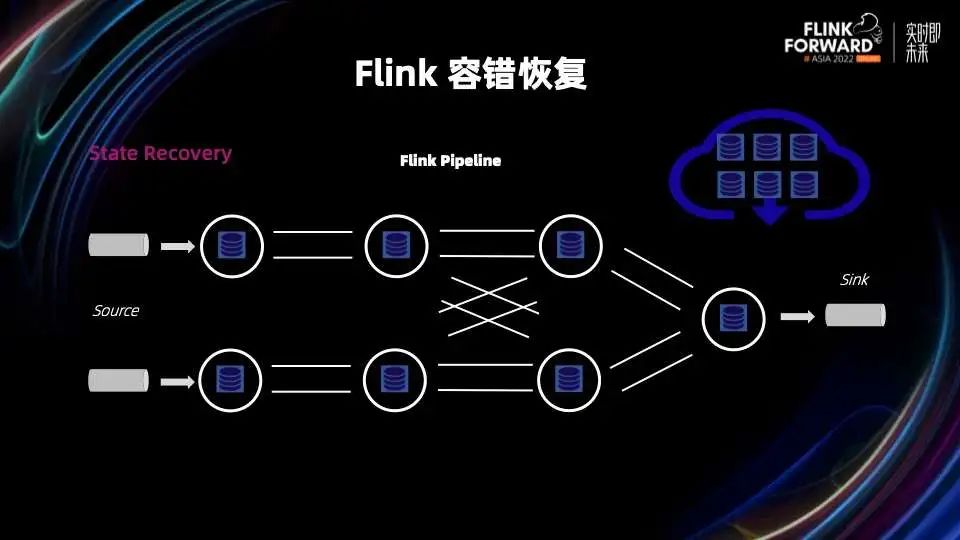


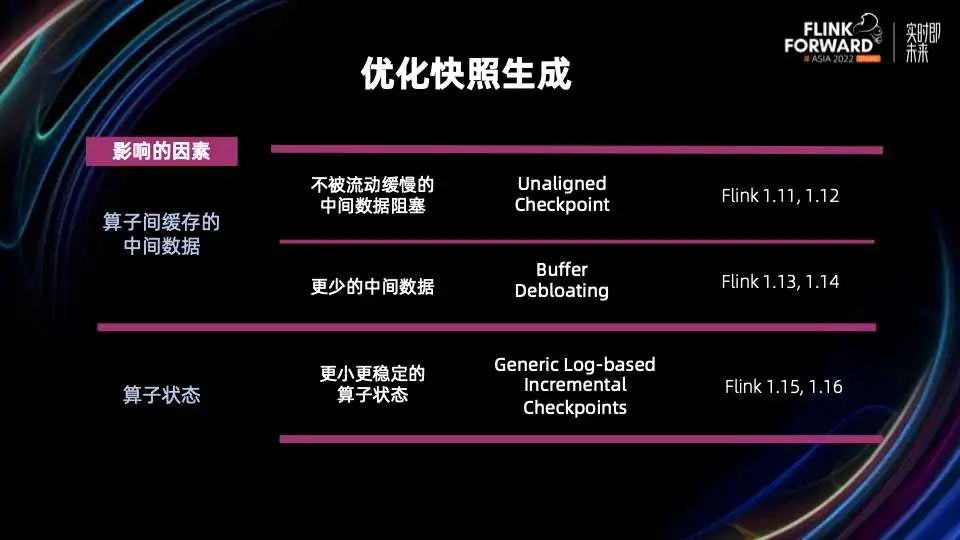
Flink 1.16 修复了和 Unaligned Checkpoint 相关的几个关键 bug,特别是 Unaligned 和 Aligned Checkpoint 之间转换这个部分,使得 Unaligned Checkpoint 可以真正做到生产可用; Flink 1.16 发布的一个重要 feature 是通用增量 Checkpoints,通过增量快照和 State Store 快照过程的分离,可以保证稳定快速的 Checkpointing 过程。这个后续我们会有相关 Blog Post 详细的分析通用增量 Checkpoints 在各种 Benchmark 下的各项指标以及适用场景。
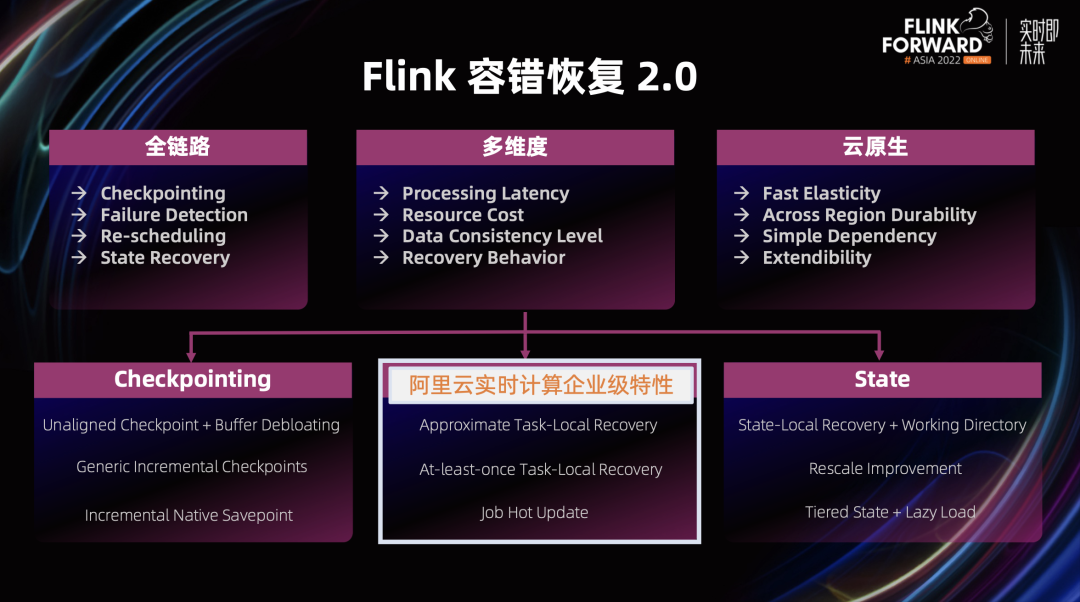
2022 年度 Flink 容错 2.0 项目进展
2.1 优化快照生成
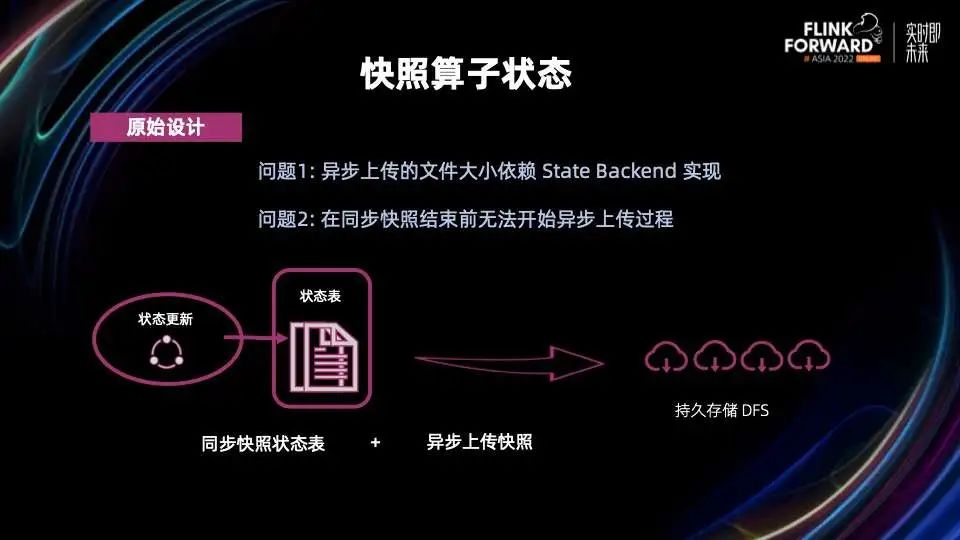
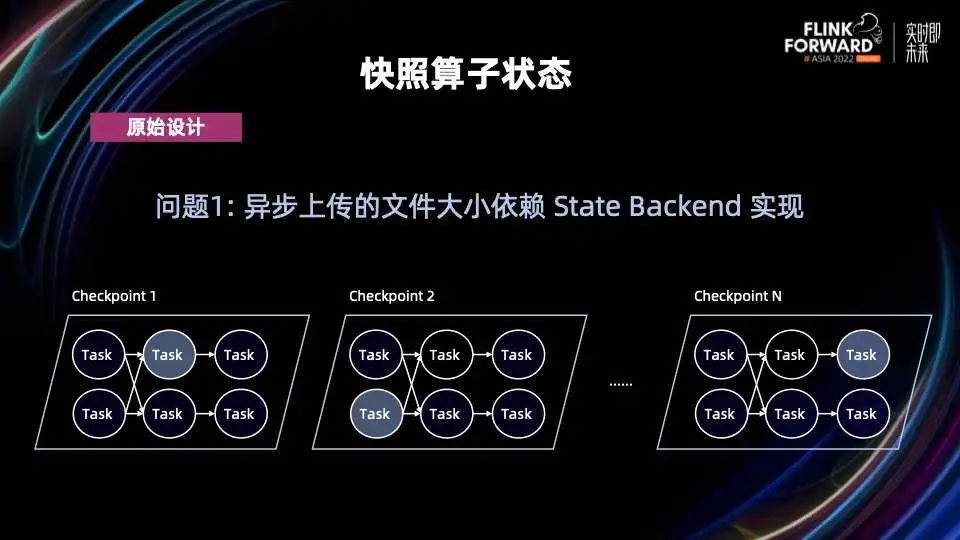
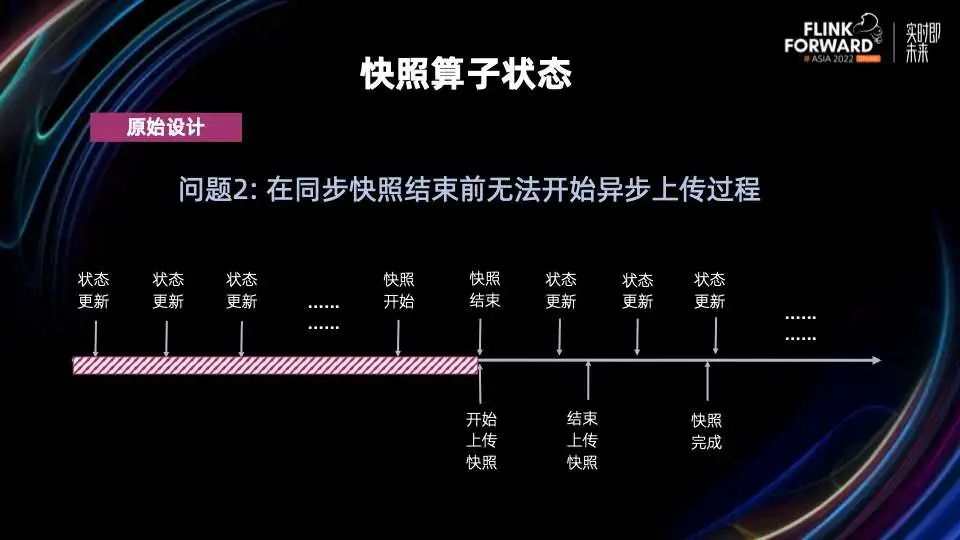
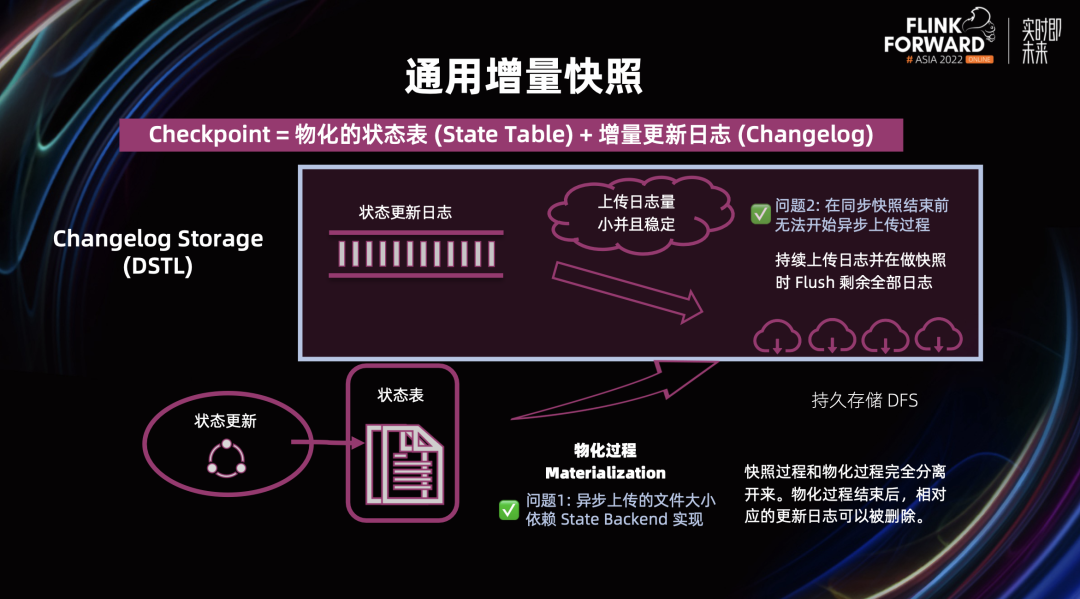

需要短期持久化增量日志,物化后即可删除 需要支持高频写,是一个纯 append 写操作,仅在恢复时需要读取 需要 99.9% 的写请求在1秒内完成 需要和现有的 Checkpoint 机制提供同一级别的一致性保证

可以让 Checkpoint 做的更稳定,平滑 CPU 曲线,平稳网络流量使用(因为快照上传的时间被拉长了,并且单次上传量更小更可控) 可以更快速的完成 Checkpoint(因为减少了做快照 Flush 的那个部分需要上传的数据) 也因此,我们也可以获得更小的端到端的数据延迟,减小 Transactional Sink 的延迟 因为可以把 Checkpoint 做快,所以每次 Checkpoint 恢复时需要回滚的数据量也会变少。这对于对数据回滚量有要求的应用是非常关键的
Checkpoint 放大的影响主要有两点。第一,远端的存储空间变大。但远端存储空间很便宜,10G 一个月大约 1 块钱。第二,会有额外的网络流量。但一般做 Checkpoint 使用的流量也是内网流量,费用几乎可以忽略不计。 对于状态双写,双写会对极限性能有一些影响,但在我们的实验中发现在网络不是瓶颈的情况下,极限性能的损失在 2-3% 左右(Flink 1.17 中优化了双写部分 FLINK-30345 [2] ,也会 backport 到 Flink 1.16),因此性能损失几乎可以忽略不计。
2.2 优化作业恢复和扩缩容

■ 本地状态重建
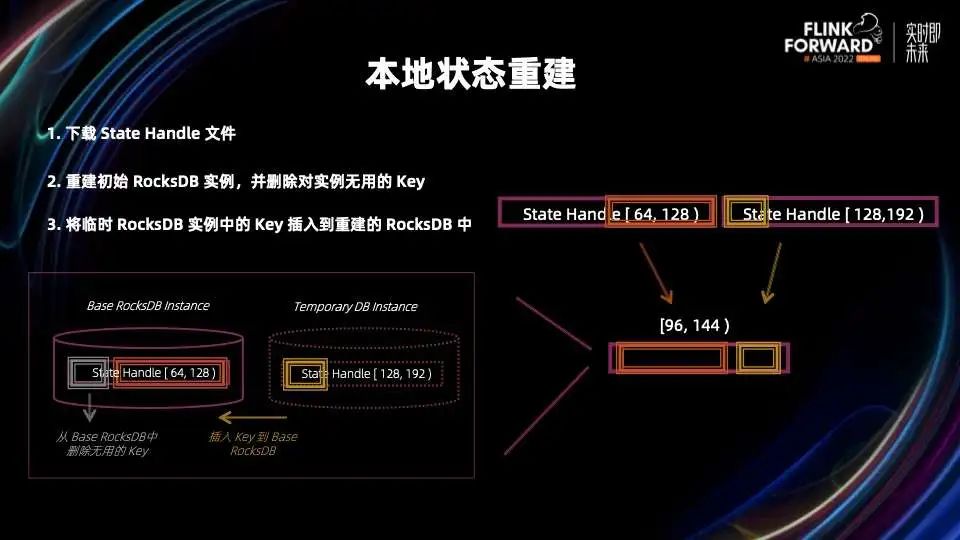
第一步,需要下载相关的状态文件。 第二步,重建初始的 RocksDB 实例,并删除对实例无用的 Key,即删除上图中灰色的部分,留下橙色部分。 第三步,将临时 RocksDB 实例中的 Key 插入到第二步重建的 RocksDB 中,也就是黄色的部分插入到橙色的 DB 中。
■ 分层状态存储架构
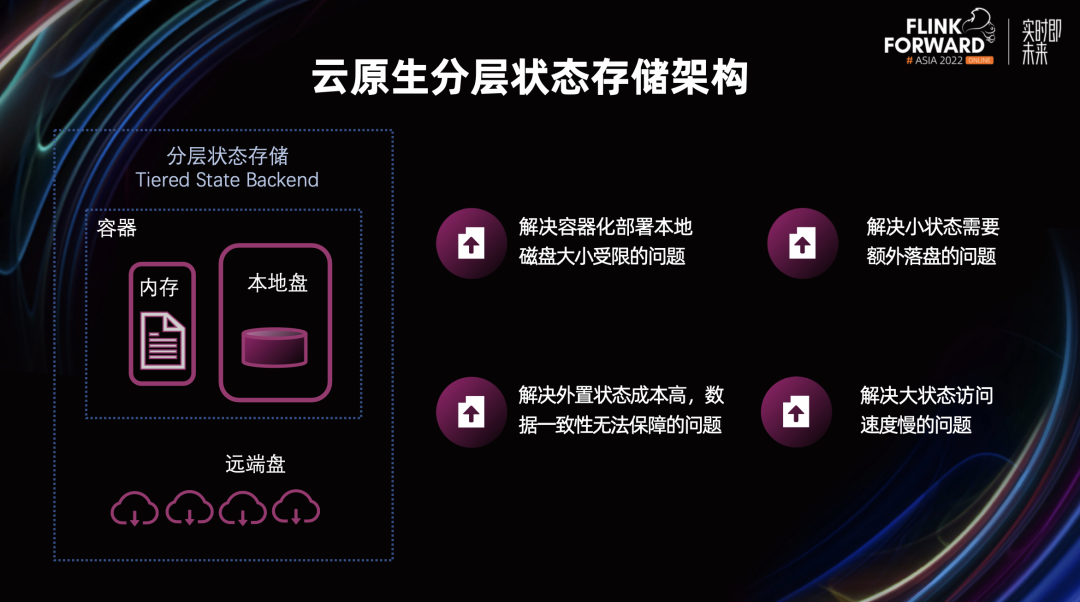
解决容器化部署本地磁盘大小受限的问题
解决外置状态成本高,数据一致性难以保障的问题 解决小状态需要额外落盘的问题 解决大状态访问速度慢的问题
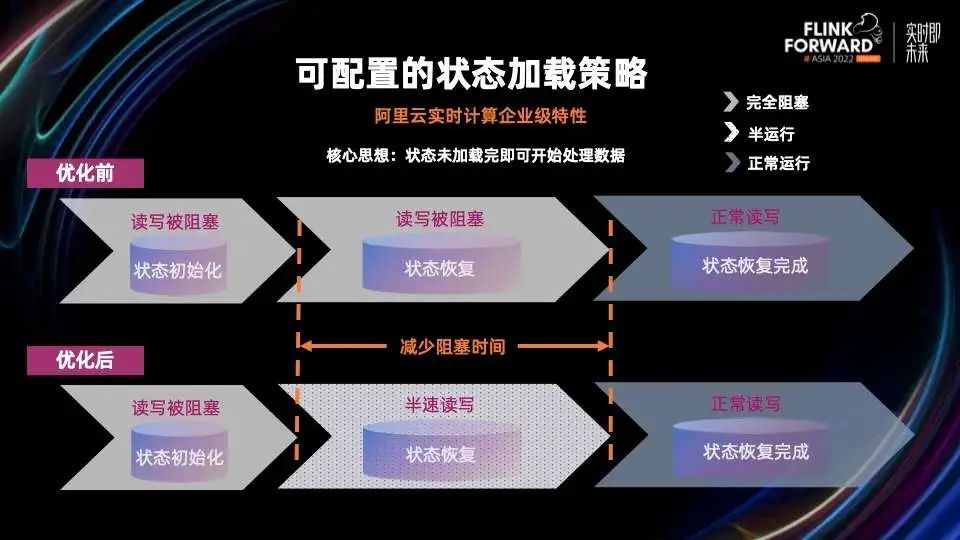
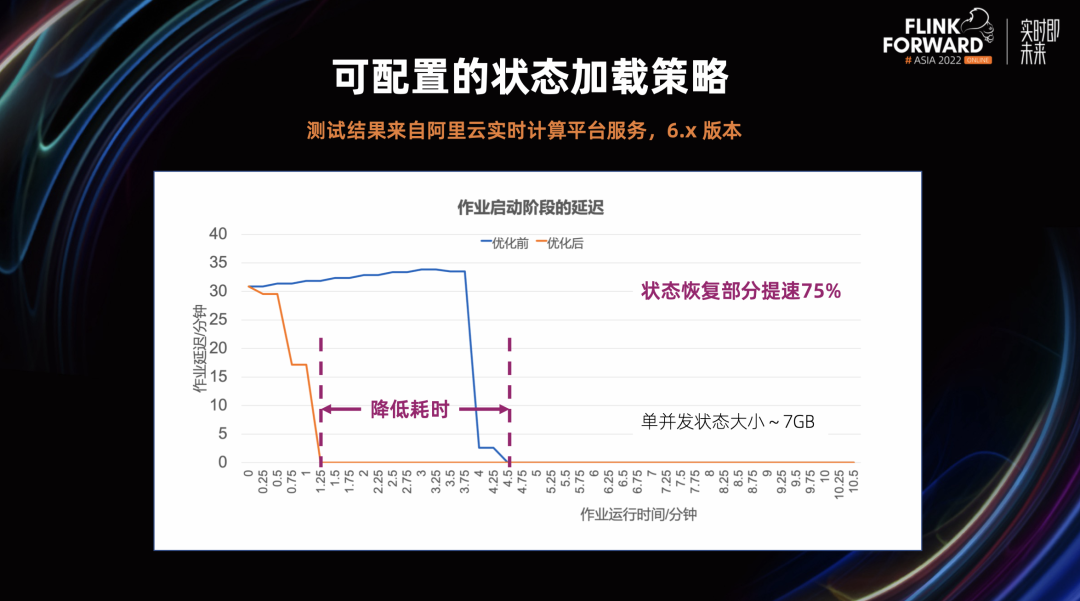
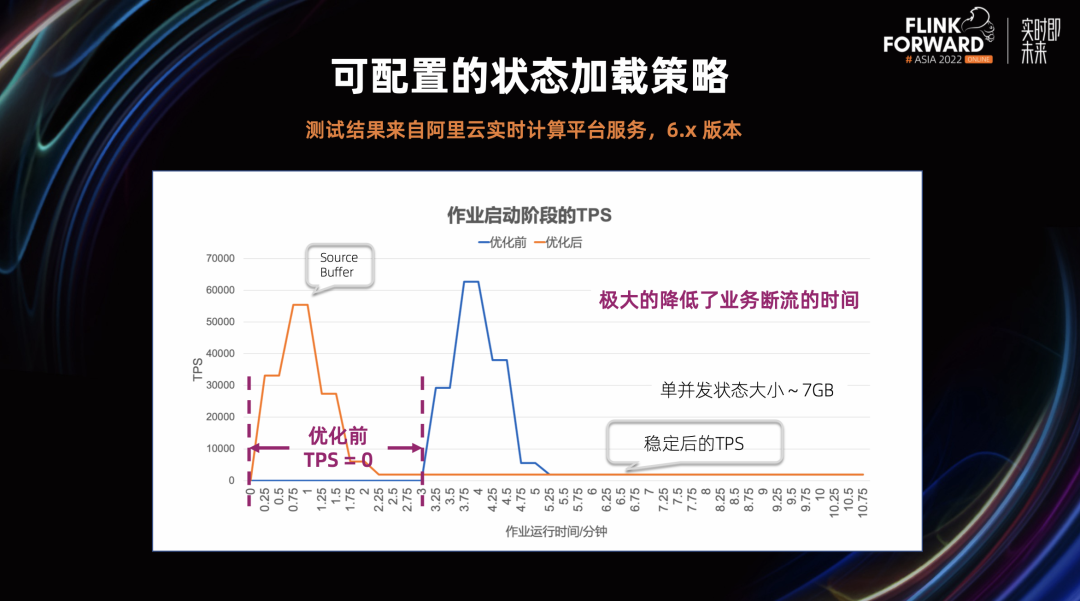

2.3 优化快照管理
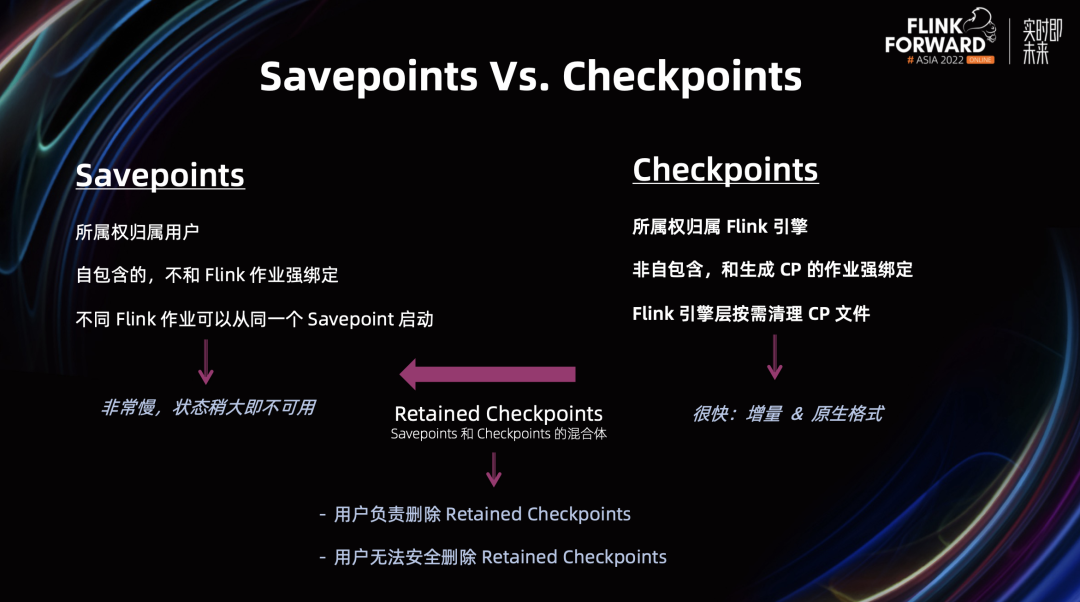
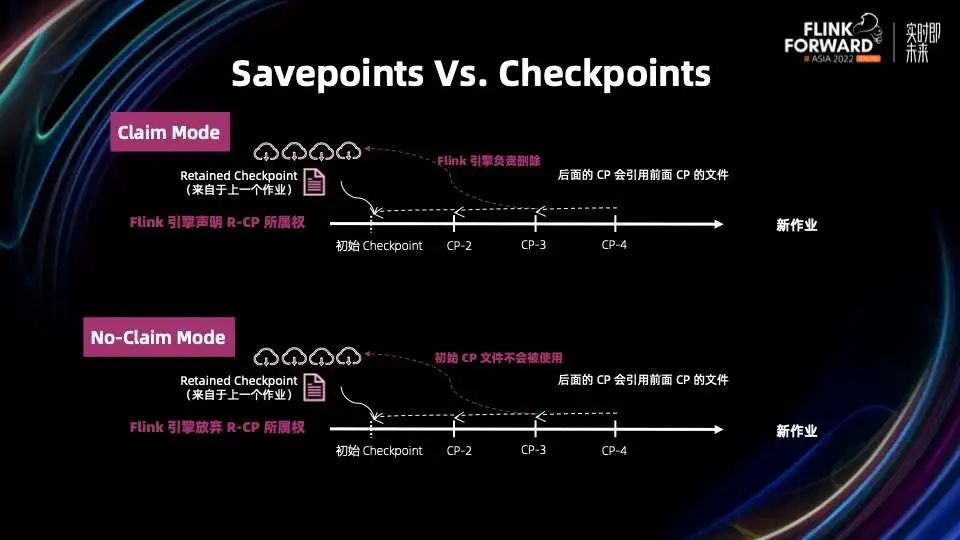


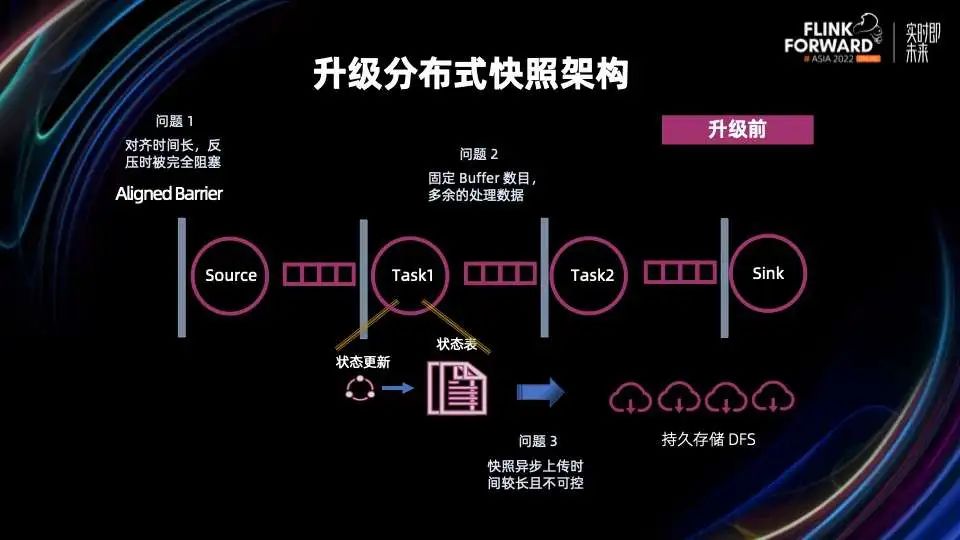
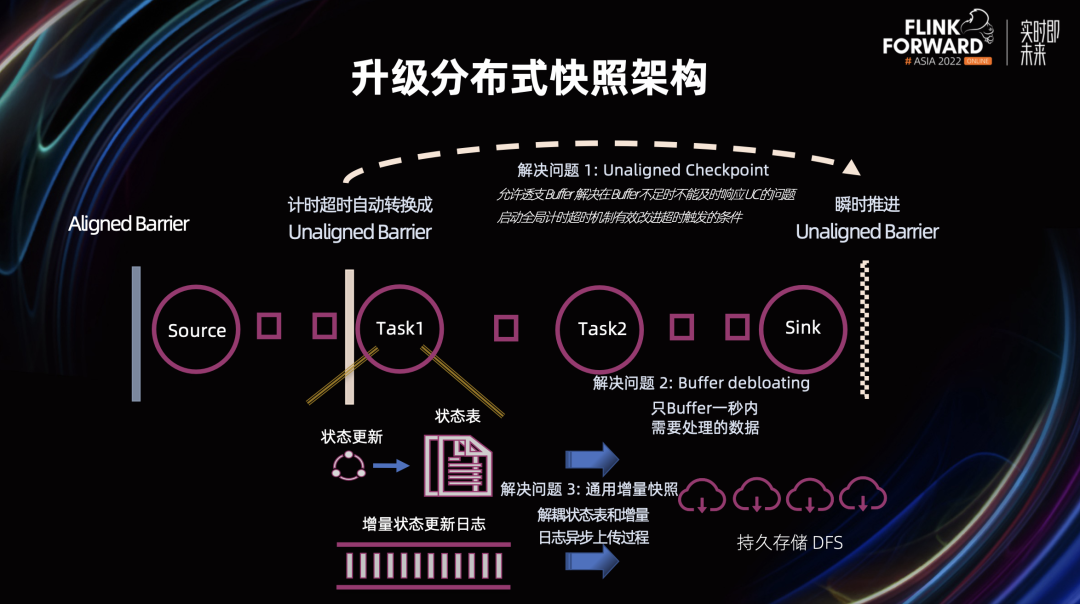
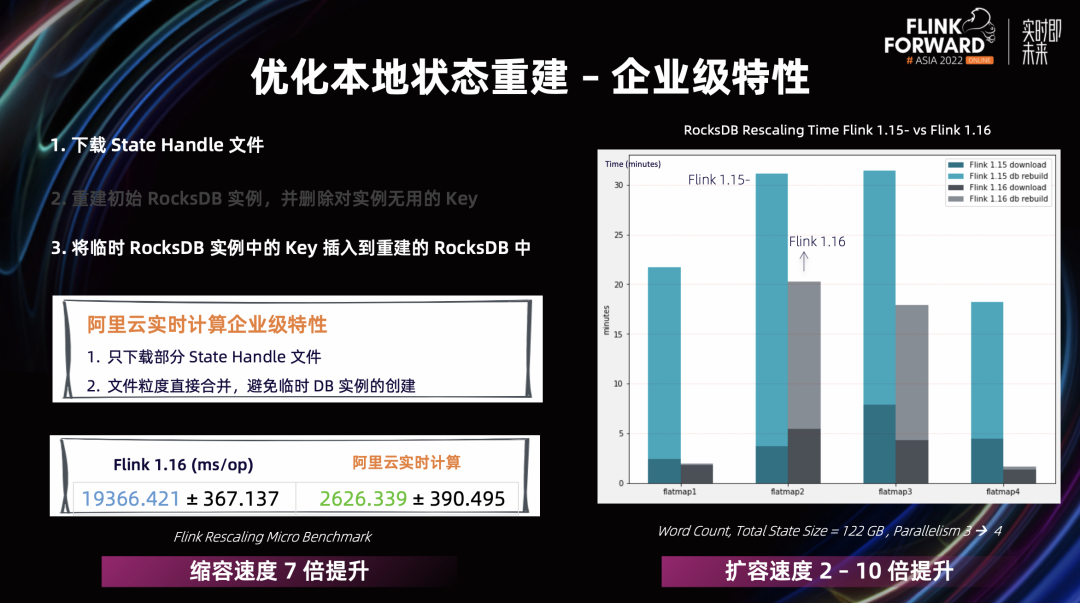
在分布式快照架构方面,Unaligned Checkpoint 引入全局计时器,可以通过超时机制自动从 Aligned Checkpoint 切换成 Unaligned Checkpoint,这个对于 Unaligned Checkpoint 生产可用是非常重要的一步 通用增量 Checkpoint 生产可用,这对于 Checkpoint 稳定性和完成速度有很大的提升,同时可以平滑 CPU 和网络带宽的使用 这里值得一提的是,不仅仅是阿里巴巴在 Checkpoint 这个部分贡献了大量的代码,很多其他的公司也积极的投入到社区当中,比如 Shopee 和美团。他们在社区中贡献代码同时,也积极推动这些功能在公司内部的落地和延展,取得了不错的效果 在状态存储方面,我们进行了分层状态存储的初步探索,扩缩容速度有 2 – 10 倍的提升 阿里云实时计算平台推出了扩缩容无断流的组合功能:延迟状态加载和作业热更新,分别从状态加载和作业调度这两个方面来实现扩缩容无断流 引入增量 Native Savepoint,全面提升 Savepoint 的可用性和性能
往期精选






 点击「阅读原文」,查看原文视频&演讲 PPT
点击「阅读原文」,查看原文视频&演讲 PPT文章转载自Flink 中文社区,如果涉嫌侵权,请发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
