





本期我们有幸采访了Kvrocks开源PMC林添毅老师,一起探讨适用于大数据量场景的存储服务——Kvrocks,Kvrocks 是基于 RocksDB 之上兼容 Redis 协议的 NoSQL 存储服务。

林添毅
Apache Kvrocks(Incubating) 的PMC
国际电商SaaS公司AfterShip担任技术经理
在大数据处理的诸多环节当中,存储是尤其关键的一环。只有实现了稳固的数据存储,才能为后续的大数据分析、数据可视化等环节提供稳定的地支持。
海量数据时代的到来,面临着许多挑战和亟待解决的问题。
• 巨大的数据量带来存储成本压力;
• 多样化数据类型需要不同的存储支撑;
• 数据产生速度加快,海量数据如何快速有效的分析;
• 商业价值高,非结构化数据价值密度低,海量数据要深挖数据价值,数据为价值资产需要长期保存。
其中,未存储、未保存的数据即被丢弃的数据。而在数据化时代的今天,数据中所蕴藏的价值有无限可能,丢弃数据就是丢弃价值和机会。

问题 1:老师,您好!请简单介绍一下您的技术背景、目前所负责的领域
问题 2:Apache Kvrocks当前的分工情况?
Kvrocks一直都是以开源社区的运作方式,每个人都是独立的贡献者且没有雇佣关系,所以不像商业公司那样有明确的分工和职责。在Kvrocks进入了 Apache 孵化器之前,Core Team 成员大约是每年年初讨论一下的整体方向并放到社区里面(后面也有提到),后续也会有类似规划的讨论且过程也会公开。作为开源组织,社区只能鼓励大家成为更活跃的志愿者,没有权利要求贡献者在时间点去解决什么问题,所以实际上并没有明确的任务分工。在协作方面,需要解决的问题都会统一在社区里面公开讨论,并由愿意解决的人来认领任务。
另外,从 Apache 孵化项目分工来看,当前主要有三种角色:
项目导师:作为 Apache 开源组织和孵化项目之间的纽带,除了传递 Apache Way 的社区运营理念之外,也会帮忙解决项目在进入孵化器过程中遇到的各种问题。除此之外,导师也会作为 Committer 的角色重度参与到项目开发,比如 Kvrocks 的导师 tison 个人也花了大量时间参与项目开发,除了帮助更好的建立社区之外,也通过个人影响力来帮助项目吸引更多关注。
Committer:Committer 和 Contributor 的差异是他们具有代码合并权限。这些人也是从社区中比较活跃的 Contributor选举而来,而Committer身份也仅仅是作为之前贡献的一种认可,从协作流程(责任)和 Contributor 本身不没有太大的差异。
Contributor:个人认为不管是使用者、提建议、Issue 还是PR的发起人都算是Contributor,只是使用不同的方式帮助社区变得更好。
问题 3:Apache Kvrocks 是如何进行数据复制?如何实现分布式集群?
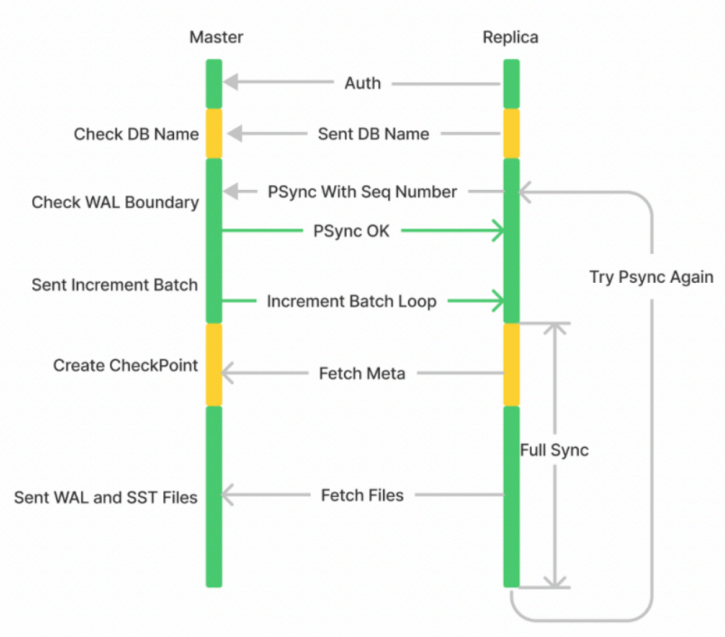
关于集群方面,Kvrocks选择是兼容Redis Cluster协议,用户可以直接使用已有的Redis Cluster SDK接入 Kvrocks Cluster。在设计上跟Redis Cluster的差异在于Kvrocks将集群节点发现(拓扑控制)交由外部的组件来做,主要考虑点是Redis Cluster这种无中心的设计,代码写对不太容易,稳定下来需要有大量的用户实践和反馈。如果依赖于外部组件,比如 Zookeeper/ETCD 等可以简单实现拓扑管理的功能,可以在相对短的时间内提供一个可用版本,Kvrocks只需要兼容协议即可,集群介绍文章可参考: https://mp.weixin.qq.com/s/Ev81UGz08aPu50s218ej_w。
问题 4:使用Redis有哪些好处?Redis适用于哪些场景?
问题 5:如何理解国内开源生态链?在开源实战中,印象最深的事情是什么?
实话说,个人在开源领域也只算是新手,虽然给不少项目提供一些PR,但对于国内的开源生态链算不上熟悉。不过大家有目共睹的是国内优秀的开源项目越来越多,比如最近从Apache毕业成为顶级项目的 Doris/InLong/ShenYu 等。中间印象比较深刻的事情是在今年俄罗斯和乌克兰战争期间,看到了一位来自乌克兰的贡献者 [torwig](https://github.com/torwig) 给我们贡献了不少的代码,惊讶之余有点感动。另外,也有很多贡献者(包含我自己)都是个人工作之外的时间来给项目做贡献,从沟通过程中可以看到对于开源本身的纯粹和热情。
问题 6:您认为 Apache Kvrocks 最突出的优点是什么?
问题 7:对于分布式集群来说,弹性伸缩的能力是必不可少的,Apache Kvrocks 是如何实现弹性伸缩的?
管控节点或DBA可以通过 **CLUSTERX MIGRATE 命令** 进行slot迁移,即可完成一个特定slot数据的迁移。参考: https://mp.weixin.qq.com/s/Ev81UGz08aPu50s218ej_w。
问题 8:您认为好的数据库工具应具备哪些条件?
因为数据库类型和细分领域差异比较大,我自己本身不太会回答这个问题。
如果作为一个数据库的使用者的角度来看,应该希望可以具备一下条件:
稳定性好,作为数据库存储应该没有人希望它三天两头有问题;
简单易用,不管是开发还是 DBA,一定希望可以尽量做到开箱即用,没有人喜欢花了九牛二虎之后才能用上,而且还感觉很兴奋;
性能好,每个数据库设计都不太一样,性能是相对场景而言。应该没有一个数据库都够完全覆盖所有场景且能够全做到性能表现都很好;
扩展性好,早期数据库的在线扩容和分库分表应该是很多数据库的噩梦,现在很多数据库也逐步开始解决在线扩容的问题。
问题 9:未来的下一步计划是什么?
Kvrocks每年整体的计划和方向都会在社区里面体现,2022 年的计划见: https://github.com/apache/incubator-kvrocks/projects/2,主要大的几个方向:
社区版本的集群管控服务,预期 2022 年 7 月份发布第一个版本,项目地址: https://github.com/KvrocksLabs/kvrocks_controller;
丰富数据结构,比如高频使用的 JSON 数据结构,预期后续往多模演进;
性能以及优化易用性,面向公有云的性能优化以及运维体系还有比较大的提高空间;
安全性增强方面计划支持 TLS 特性。
不过,作为纯粹的开源组织并不会承诺任何功能和时间,如果觉得有价值十分欢迎直接参与进来。
问题 10:有什么关于开源方向的意见和建议吗?
个人对于开源的理解: 开源本质还是人,如果脱离的人也就没有社区,也就算不上真正的开源。想要吸引到更多优秀的人参与,除了项目定位清晰之外,充分开放讨论和上下文也十分重要,所有重要变更以及决定都应该在社区里面公开,让当前以及后继的开发者都可以轻松参与进来。另外,作为项目早期的参与者要以开放的心态来认可和接纳更加优秀的人,让更加有能力的人来主导项目发展。每个人都只是参与者,重要的不是谁来主导项目而是能不能帮助社区变得更好了。
推荐阅读
金融行业分布式数据库是否具备核心系统替换条件


