





本文作者 | 韩医徽

这是系列文章的第二篇,在第一篇文章“另辟蹊径:在云端使用 SQL 语言实现数据转化,测试和文档维护” 中介绍了做数据准备的 ELT 模式,以及如何利用 DBT 来帮助 Data Analysts 通过 SQL 做数据转化,测试和文档维护。在这篇文章中,将以上一篇为基础,使用 Amazon Web Services CDK 构建一个 Data OPS 方案。

作为一名解决方案架构师,按我的理解,从技术角度去看,数字化转型的本质就是利用大数据的技术来提升企业的运营效率,从而使企业的各个部门,如客户成功、营销和财务部门,都能做出数据驱动的决策。在这个过程中,数据团队是关键推动者。数据团队通常由 Data Infra Engineer 和 Data Analysts 等多个角色组成。
架构概述
架构图及流程说明
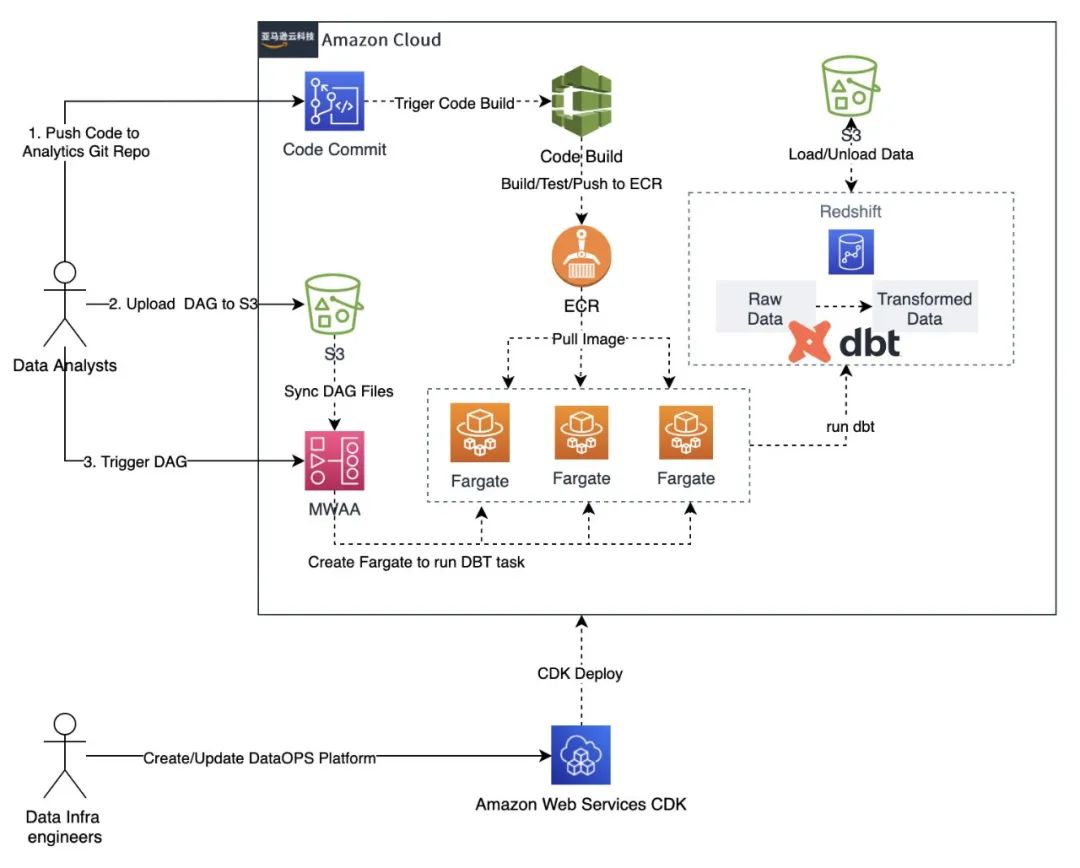
▼Data Infra Engineer
Redshift 集群 CodeCommit, CodeBuild,用于构建 Data Analysts 开发的 DBT 工程的持续集成流程 ECR,用于存放管理 Data Analysts 开发的 DBT 工程的 Docker Image MWAA,用于供数据开发人员调度 DBT 任务的 Airflow 集群 ECS Cluster, 用于运行 DBT Task
▼Data Analysts
在 Data Infra Engineer 使用 CDK 创建好 DataOPS 平台之后,Data Analysts 大致操作流程如下:
使用 Amazon Web Services CDK
构建 Data OPS 方案
笔者也实现了上述架构,源代码在Github公开,供大家参考,其中:
● elt-dbt-redshift-demo-for-data-engineer 为 Data Infra Engineer 提供了参考实现;

● elt-dbt-redshift-demo-for-data-analysts 为 Data Analysts 提供了参考实现;

↓↓↓接下来详细演示如何在云上构建并使用 DataOPS 平台:
▼CDK 开发环境搭建
开发 Amazon Web Services CDK 需要先安装 Amazon Web Services CDK CLI,利用 Amazon Web Services CDK CLI 可以生成对应的 CDK 的 Project。
Amazon Web Services CDK CLI 的安装依赖于 Node.js,所以在您的开发环境需要先安装 node.js。node.js 的安装可扫码参看官方教程:

安装好 node.js 之后,可以直接使用 如下命令安装 Amazon Web Services CDK CLI:
npm install -g aws-cdk #安装cdk clicdk --version #查看版本

▼Data Infra Engineer 使用 CDK 构建 Data OPS 平台
npm install -g yarnnpm install -g npxgit clone https://github.com/readybuilderone/elt-dbt-redshift-demo-for-data-engineer.gitcd elt-dbt-redshift-demo-for-data-engineernpx projennpx cdk bootstrap aws://<ACCOUNT-NUMBER>/<REGION> --profile <YOUR-PROFILE>npx cdk deploy --profile <YOUR-PROFILE>存放 Airflow Dag 的 S3 Bucket 的名称 ECS Cluster 的名称 ECS Task Definition 名称 Redshift 的所在的 Subnet 的 ID
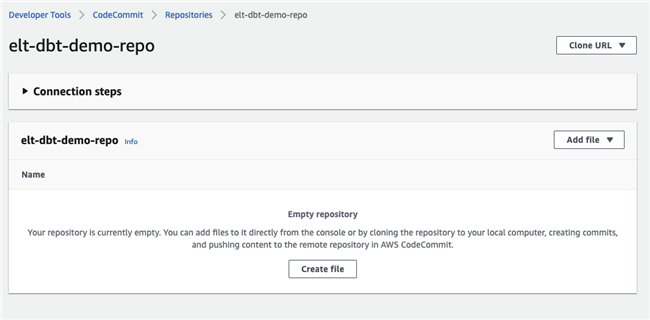
Code Commit:CDK 创建了一个空的 CodeCommit,供 Data Analysts 使用。
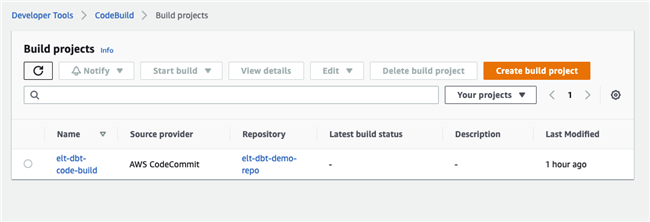
Code Build:CDK 创建了 CodeBuild Project,会在 Data Analysts 提交代码到 CodeCommit 后,自动触发,打包成 container image。
ECR Repo:CDK 创建了空的 ECR Repo,用来存放 CodeBuild 生成的 container image。
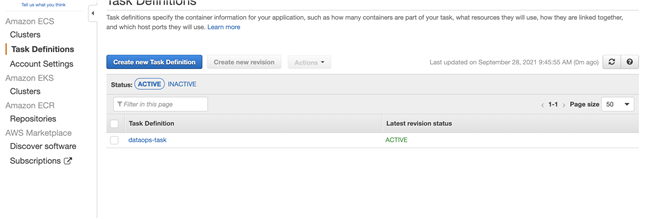
ECS Cluster:CDK 创建了 ECS Cluster,和对应的 Task 用来运行 dbt 的 container 任务。

MWAA:CDK 创建了 MWAA,其中 DAG 为空。
Redshift:CDK 创建了Redshift集群,但是public schema之下,并没有任何的table。
↓↓↓DataOPS 平台创建成功,接下来演示 Data Analysts 的部分。
▼Data Analysts 利用 Data OPS 平台进行项目开发
推送代码到 CodeCommit

git clone https://github.com/readybuilderone/elt-dbt-redshift-demo-for-data-analysts.gitcd elt-dbt-redshift-demo-for-data-analystsgit remote -vgit remote add codecommit <YOUR-CODECOMMIT-SSH-ADDRESS>git push codecommit

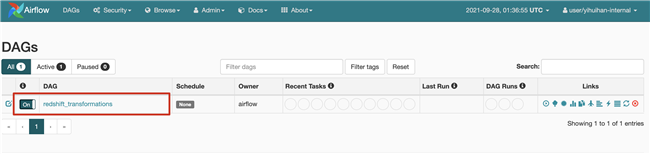
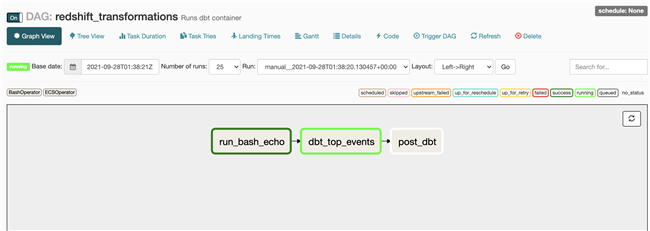
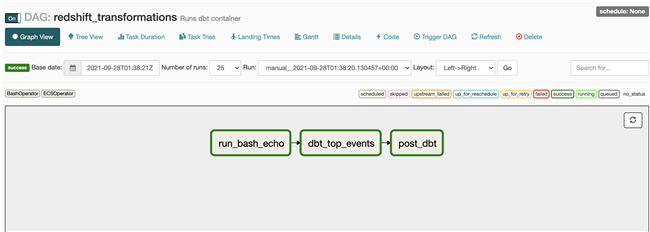
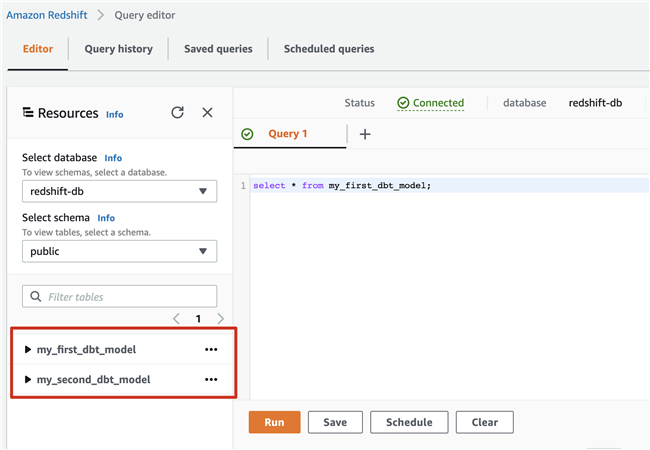
观察 DataOPS 过程
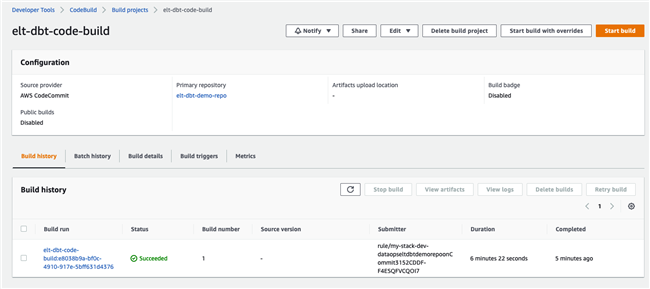
Data Analysts 构建 Airflow DAG,触发 DBT 任务,使用 Fargate 运行 DBT 任务
elt-dbt.py
import os
from airflow import DAG
from airflow.contrib.operators.ecs_operator import ECSOperator
from airflow.operators.bash_operator import BashOperator
from airflow.utils.dates import days_ago
from datetime import timedelta
default_args = {
"owner": "airflow",
"depends_on_past": False,
"start_date": days_ago(2),
"retries": 0,
"retry_delay": timedelta(minutes=5),
}
dag = DAG(
"redshift_transformations",
default_args=default_args,
description="Runs dbt container",
schedule_interval=None,
is_paused_upon_creation=False,
)
bash_task = BashOperator(task_id="run_bash_echo", bash_command="echo 1", dag=dag)
post_task = BashOperator(task_id="post_dbt", bash_command="echo 0", dag=dag)
dbt_top_events = ECSOperator(
task_id="dbt_top_events",
dag=dag,
aws_conn_id="aws_ecs",
cluster="dataops-ecs-cluster",
task_definition="dataops-task",
launch_type="FARGATE",
overrides={
},
network_configuration={
"awsvpcConfiguration": {
"subnets": ["<YOUR-SUBNET-ID>", "<YOUR-SUBNET-ID>"],
},
},
awslogs_stream_prefix="ecs/dbt-cdk-container",
)
bash_task >> dbt_top_events >> post_task
aws s3 cp ./elt-dbt.py S3://<YOUR-BUCKET>/dags/ --profile <YOUR-PROFILE>

总结
在本篇文章中,提供了 DataOPS 的一个参考实现,Data Infra Engineer 可以使用 CDK 方便地创建维护 Infra,Data Analysts 基于这个平台,可以使用自己熟悉的语言和调度工具,进行开发。提交到 Git 之后,可以自动触发持续集成的后续任务,可以通过 Airflow 使用 Fargate 运行对应的任务,而不需要关心 Infra 层面的问题,希望这个方案可以帮助到大家。
●
作者介绍

韩医徽
亚马逊云科技解决方案架构师,负责亚马逊云科技合作伙伴生态系统的云计算方案架构咨询和设计,同时致力于亚马逊云科技云服务在国内的应用和推广。

推荐阅读

- END -

长按识别左侧二维码
关注我们>>
宁夏西云数据科技有限公司(简称“西云数据”)是亚马逊云科技中国(宁夏)区域云服务的运营方和服务提供方,作为西云数据的战略技术合作伙伴,亚马逊云科技向西云数据提供技术、指导和专业知识。西云数据成立于 2015 年,是一家持有互联网数据中心服务和互联网资源协作服务牌照的云服务提供商。2017 年 12 月 12 日, 西云数据正式推出亚马逊云科技中国(宁夏)区域云服务,现已开通 3 个可用区。西云数据市场销售总部设立于北京,在全国多地设有分支机构以服务全国各地的企业客户。
西云数据致力于将世界先进的 Amazon Web Services 云计算技术带给中国客户,为客户提供优质、安全、稳定、可靠的云服务,全力支持中国企业和机构的创新发展。
15 年多以来,亚马逊云科技(Amazon Web Services)一直是世界上以服务丰富、应用广泛而著称的云平台。亚马逊云科技一直不断扩展其服务组合以支持几乎云上任意工作负载,目前提供了超过 200 项全功能的服务,涵盖计算、存储、数据库、联网、分析、机器人、机器学习与人工智能、物联网、移动、安全、混合云、虚拟现实与增强现实、媒体、以及应用开发、部署与管理等方面,遍及 25 个地理区域的 80 个可用区(AZ),并已公布计划在澳大利亚、印度、印度尼西亚、西班牙、瑞士和阿拉伯联合酋长国新建 6 个区域、18 个可用区。全球数百万客户,包括发展迅速的初创公司、大型企业和领先的政府机构都信赖亚马逊云科技,通过亚马逊云科技的服务强化其基础设施,提高敏捷性,降低成本。欲了解亚马逊云科技的更多信息,请访问:http://aws.amazon.com。




