




在本文中,了解如何将数据从 Neo4j 迁移到星云图。
本文主要介绍如何使用星云图交换(简称Exchange)将数据从Neo4j迁移到星云图,星云图团队支持的数据迁移工具。在介绍如何导入数据之前,我们先来看看星云图内部的数据迁移是如何实现的。
星云图交换中的数据处理
我们的数据迁移工具的名称是星云图交换。它使用Spark作为导入平台,支持庞大的数据集导入并确保性能。数据帧是组织成命名列的分布式数据集合,由 Spark 提供,支持各种数据源。使用数据帧,若要添加新数据源,只需提供要读取的配置文件的代码和数据帧返回的读取器类型。
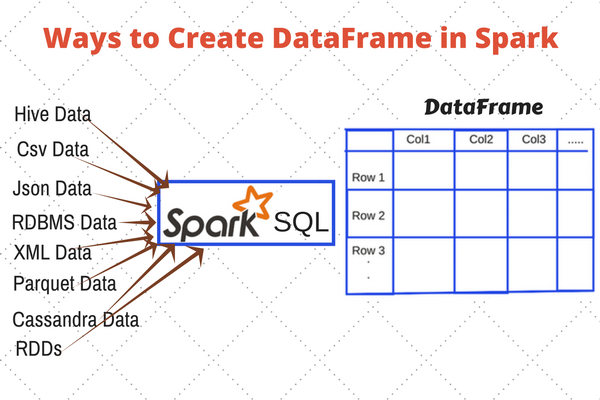
如上所述,数据帧是组织成行和列的分布式数据集合。一个数据帧可以存储在多个分区中。分区存储在不同的计算机上以支持并行操作。此外,Spark还提供了一组API,允许用户轻松操作DataFrames,就像在本地操作一样。此外,大多数数据库都支持将数据导出到数据帧中。即使数据库不提供此类功能,也可以使用数据库驱动程序手动生成数据帧。
将数据转换为数据帧后,星云图交换遍历数据帧中的每一行,根据配置文件中的字段映射关系,通过列名获取对应的值。遍历行后,Exchange将获取的数据一次性写入星云图。目前,Exchange 生成 nGQL 语句,然后由星云客户端异步写入数据。我们将支持导出存储在星云图底层存储中的 sst 文件,以获得更好的性能。接下来,让我们继续实现 Neo4j 数据导入。batchSize
实现从 Neo4j 导入数据
Neo4j提供了一个官方库,可以直接将数据导出为数据帧。但是,它不支持可恢复下载。因此,我们没有直接使用此库。相反,我们使用官方的 Neo4j 驱动程序来读取数据。为了获得更好的性能,Exchange 通过调用不同分区上的 Neo4j 驱动程序来执行不同的 Cypher 语句,并将数据分发到不同的分区。分区数由配置参数 指定。skiplimitpartition
Exchange 通过以下步骤导入 Neo4j 数据:首先,Exchange 中的 Neo4jReader 类将用户配置中的 Cypher 语句和语句替换为并执行它们以获得总数据大小。其次,交易所根据分区号计算每个分区的初始偏移量和大小。如果配置了参数,Exchange 也会读取此目录下的文件。如果下载处于可恢复状态,Exchange 将计算每个分区的初始偏移量和大小,然后在每个分区中的 Cypher 语句之后添加不同的 和,并调用驱动程序执行。最后,Exchange 将返回的数据转换为数据帧。execreturncount(*)check_point_pathskiplimit
下图演示了该过程:
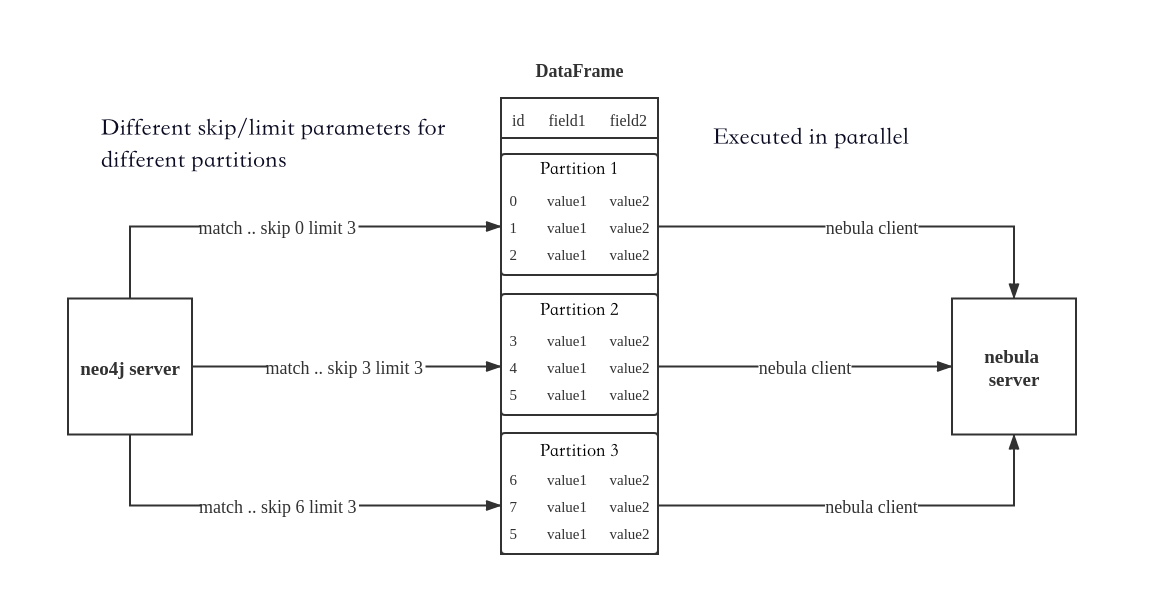
练习数据从 Neo4j 导入星云图
我们使用以下系统环境来演示导入:
硬件:
- CPU 名称: 英特尔® 至强(R) CPU E5-2697 v3 @ 2.60GHz
- 处理器核心数:14
- 内存大小:251G
软件:
- Neo4j版本:3.5.20社区
- Nebula Graph:使用 Docker Compose 部署。我们使用默认配置,在前面的机器上部署星云图。
- 火花:单节点。版本:2.4.6 Hadoop2.7预构建。
由于星云图是一个强类型模式数据库,因此在导入数据之前需要创建空格、标签和边类型。有关详细信息,请参阅创建空间语法。
在这里,我们创建一个名为 test 的空间,复制编号为 1。我们创建两种类型的标签:标签 A 和标签 B。两者都有四个属性。此外,我们创建了一个边缘类型 edgeAB,它也具有四个属性。nGQL 查询如下所示:
1# Create graph space test
2CREATE SPACE test(replica_factor=1);
3# Use graph space test
4USE test;
5# Create tag tagA
6CREATE TAG tagA(idInt int, idString string, tboolean bool, tdouble double);
7# Create tag tagB
8CREATE TAG tagB(idInt int, idString string, tboolean bool, tdouble double);
9# Create edge type edgeAB
10CREATE EDGE edgeAB(idInt int, idString string, tboolean bool, tdouble double);
现在让我们将模拟数据导入 Neo4j。模拟数据包含 100 万个标有标签 A 和标签 B 的顶点,1000 万个标有 edgeAB 的边。注意,从Neo4j导出的数据必须具有属性,数据类型必须与星云图完全相同。
最后,为了加快 Mock 数据导入到 Neo4j 的速度并提高读取性能,我们在 tagA 和 tagB 中为该属性创建了索引。请注意,Exchange 不会将索引和约束导入星云图。因此,请记住创建和重建索引。idInt
然后我们将数据从 Neo4j 导入到星云图。首先,让我们下载并打包项目。您可以在星云-java 仓库的目录中找到该项目。运行以下命令:tools/exchange
- it clone https://github.com/vesoft-inc/nebula-java.git
- cd nebula-java/tools/exchange
- mvn package -DskipTests
然后你会看到该文件。target/exchange-1.0.1.jar
接下来,我们转到配置文件。配置文件的格式为 HOCON(人类优化配置对象表示法)。让我们根据文件进行修改。首先,为星云图配置地址、用户、pswd 和空间。我们在此处使用默认测试环境,因此我们不会在此处修改任何内容。接下来,配置标签。我们仅演示标签 A 的配置,因为标签 B 的配置与标签 A 的配置相同。src/main/resources/server_application.conf
- {
- # ====== connection configuration for neo4j=======
- name: tagA
- # Must be exactly the same as the tag name in Nebula Graph. Must be created before importing.
- server: "bolt://127.0.0.1:7687"
- # address configuration for neo4j7user: neo4j
- # neo4j username
- password: neo4j
- # neo4j password
- encryption: false
- # (Optional): Whether to encrypt the transformation. The default value is false.
- database: graph.db
- # (Optional): neo4j databases name, not supported in the Community version
- # ======import configurations============
- type: {
- source: neo4j
- # PARQUET, ORC, JSON, CSV, HIVE, MYSQL, PULSAR, KAFKA...
- sink: client
- # Write method to Nebula Graph, only client is supported at present. We will support direct export from Nebula Graph in the future.
- }
- nebula.fields: [idInt, idString, tdouble, tboolean]
- fields : [idInt, idString, tdouble, tboolean]
- # Mapping relationship fields. The upper is the nebula property names, the lower is the neo4j property names. All the property names are correspondent with each other.
- # We use the List instead of the Map to configure the mapping relationship to keep the field order, which is needed when exporting nebula storage files.
- vertex: idInt
- # The neo4j field corresponds to the nebula vid field. The type must be int.
- partition: 10
- # Partition number.
- batch: 2000
- # Max data write limit.
- check_point_path: "file:///tmp/test"
- # (Optional): Save the import information directory, used for resumable downloads.
- exec: "match (n:tagA) return n.idInt as idInt, n.idString as idString, n.tdouble as tdouble, n.tboolean as tboolean order by n.idInt"
- }
边的配置与顶点的配置类似。但是,您需要为边配置源 vid 和目标 vid,因为星云图边包含源 vid 和目标 vid。边缘配置如下:
- source: {
- field: a.idInt
- # policy: "hash"
- }
- # configuration for source vertex ID
- target: {
- field: b.idInt
- # policy: "uuid"
- }
- # configuration for destination vertex ID
- ranking: idInt
- # (Optional): The rank field.
- partition: 1
- # Set partition number as 1. We set it to one here. We will talk about the reason later.
- exec: "match (a:tagA)-[r:edgeAB]->(b:tagB) return a.idInt, b.idInt, r.idInt as idInt, r.idString as idString, r.tdouble as tdouble, r.tboolean as tboolean order by id(r)"
您可以将哈希策略或 UUID 策略用于折点、边源折点和边目标折点。哈希/uuid 函数将字符串类型字段映射到整数类型字段。
由于前面的示例使用整数 VID,因此不需要策略设置。请参阅此处以了解哈希和uuid之间的区别。
在Cypher中,我们使用关键字来确保同一查询的顺序相同。虽然返回的数据顺序看起来是一样的,为了避免数据导入中的数据丢失,我们强烈建议在 Cypher 中使用,尽管导入速度在一定程度上被牺牲了。要提高导入速度,最好对索引属性进行排序。如果没有任何索引,请检查默认顺序并选择合适的顺序以提高性能。如果在默认返回的数据中找不到任何排序规则,可以按顶点/边 ID 对数据进行排序,并设置尽可能小的值,以减轻 Neo4j 的排序压力。这就是我们在此示例中将数字设置为 1 的原因。ORDER BYORDER BYORDER BYpartitionpartition
此外,星云图在创建顶点和边时使用ID作为唯一的主键。如果在插入新数据之前主键存在,则主键下的旧数据将被覆盖。因此,使用重复的 Neo4j 属性值作为星云图 ID 将导致数据丢失,因为具有相同 ID 的顶点被视为一个顶点,并且只保存最后一次写入。由于导入星云图的数据是并行的,我们不保证最终数据是 Neo4j 中的最新数据。
您需要注意的另一件事是可恢复下载。在断点和恢复之间,数据库不得更改状态,例如不允许插入或删除数据。不得修改该号码,否则可能会发生数据丢失。partition
最后,由于 Exchange 在不同的分区上执行不同的 Cypher 查询,因此用户不得提供包含 和 的查询。skiplimitskiplimit
接下来,运行交换以导入数据。执行以下命令:
1;$SPARK_HOME/bin/spark-submit --class com.vesoft.nebula.tools.importer.Exchange --master "local[10]" target/exchange-1.0.1.jar -c /path/to/conf/neo4j_application.conf
在上述配置下,导入 100 万个顶点需要 13 秒,导入 1000 万条边需要 213 秒。因此,总导入需要 226 秒。
附录:Neo4j 3.5社区与星云图1.0.1的比较
Neo4j和星云图在系统架构、数据模型和访问方式上有所不同。因此,我们在下表中列出了一些常见的差异供您参考:
| 项目 | Neo4j 3.5 社区 | 星云图 1.0.1 | 交流小贴士 | |
| 系统架构 | 分散式 | 仅限企业版 | 星云图 1.0.1 | / |
| 分片/分区 | 不 | 是的 | / | |
| 开源许可证 | 阿普尔 | 阿帕奇 2.0 | / | |
| 写在 | 爪哇岛 | C++ | / | |
| 高可用性 | 不 | 是的 | / | |
| 数据建模 | 属性图 | 是的 | 是的 | |
| 图式 | 架构可选或无架构 | 强架构 | 1. 必须先创建架构。 2. Neo4j的模式必须与星云图的模式一致。 | |
| 顶点/边类型 | 标签不是必须的。标签不确定属性架构。 | 标签/边类型必须至少有一个标签。标记必须与架构相对应。 | / | |
| 顶点 ID/唯一主键 | 主键不是顶点的必备条件。因此,可能会有重复的记录。主键的唯一性由内置的 id() 或约束来保证。 | 顶点 ID(或 VID)必须是唯一的。您可以使用其他应用程序生成 VID。 | 不允许没有主键的重复记录。仅保存最后的写入重复记录。 | |
| 物业指数 | 是的 | 是的 | 无法导入索引。您需要重新生成它们。 | |
| 约束 | 是的 | 不 | 不能导入约束。 | |
| 交易 | 是的 | 不 | / | |
| 示例查询 | 列出所有标签/标签 | MATCH (n) 返回不同的标签(n);调用 db.labels(); | 显示标签 | |
| 插入具有指定类型的顶点 | 创建 (:P erson {年龄: 16}) | 插入顶点 (prop_name_list) 值 :(prop_value_list)<tag_name><vid> | ||
| 更新顶点的属性 | 设置 n.name = V | 更新顶点集<vid><update_columns> | ||
| 查询指定顶点的属性 | 匹配 (n)其中 ID(n) = vidRETURN 属性(n) | 获取道具<tag_name> <vid> | ||
| 查询特定顶点的指定边类型 | 匹配 (n)-[r:edge_type]->() 其中 ID(n) = vid | 从过去开始<vid><edge_type> | ||
| 查找两个顶点之间的路径 | 匹配 p =(a)-[]->(b)其中 ID(a) = a_vid 且 ID(b) = b_vidRETURN p | 查找从到结束的所有路径 *<a_vid><b_vid> | ||
原文链接:https://dzone.com/articles/how-to-migrate-data-from-neo4j-to-nebula-graph
原文标题:How to Migrate Data From Neo4j to Nebula Graph
原文作者:by Jamie Liu
