




导读:DataTester是由火山引擎推出的A/B测试平台,覆盖推荐、广告、搜索、UI、产品功能等业务应用场景,提供从A/B实验设计、实验创建、指标计算、统计分析到最终评估上线等贯穿整个A/B实验生命周期的服务。DataTester经过了字节跳动业务的多年打磨,在字节内部已累计完成150万次A/B实验,在外部也应用到了多个行业领域。
本文将分享DataTester在查询性能提升过程中的5个优化思路。
01
现状及问题
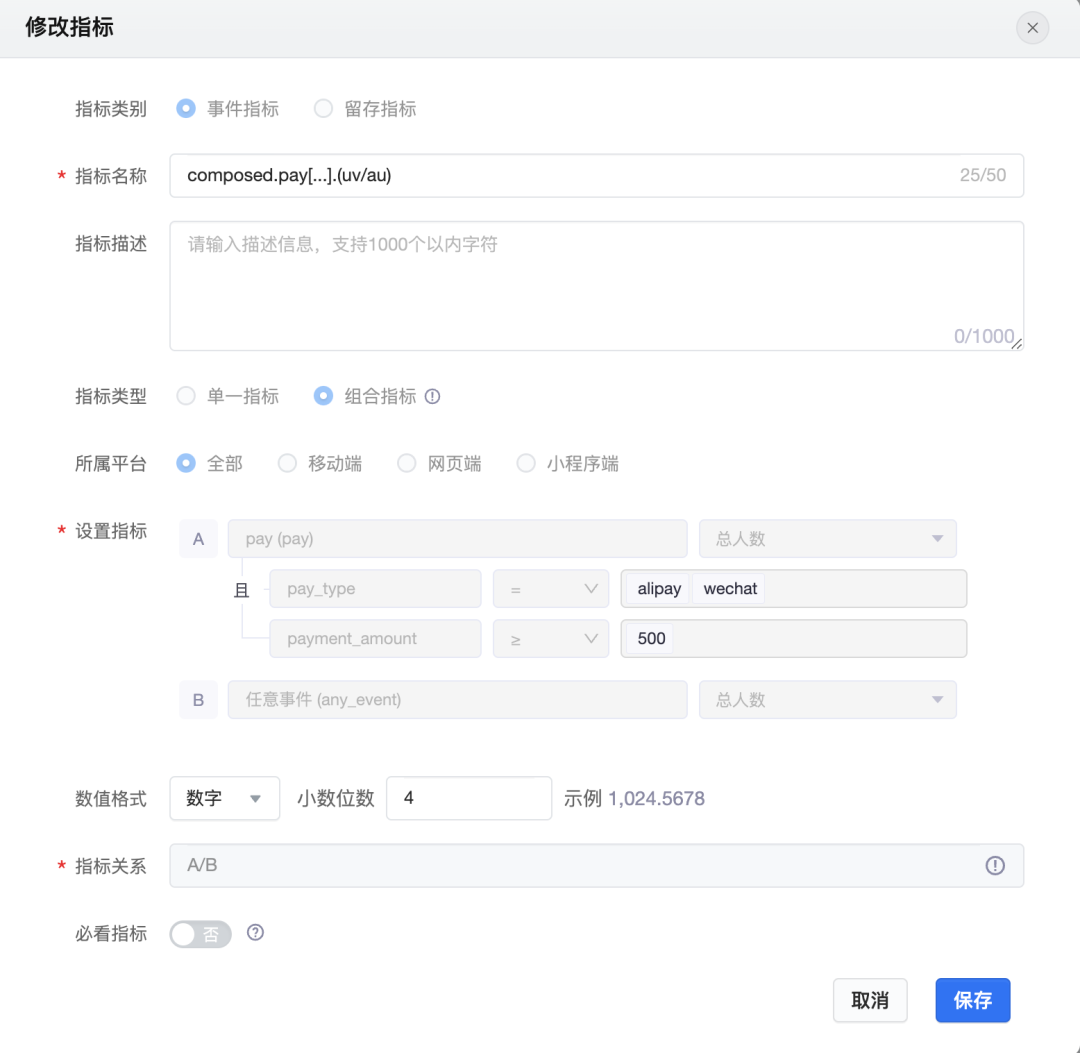
② 实现复杂:实验指标有多种算子,在查询引擎侧中都有一套定制SQL,通过DSL将算子转换成SQL。这是DataTester中最复杂的功能模块之一。
02
优化思路
从一条SQL说起。
需要查询详细的SQL代码,也可以点击展开查看详情。
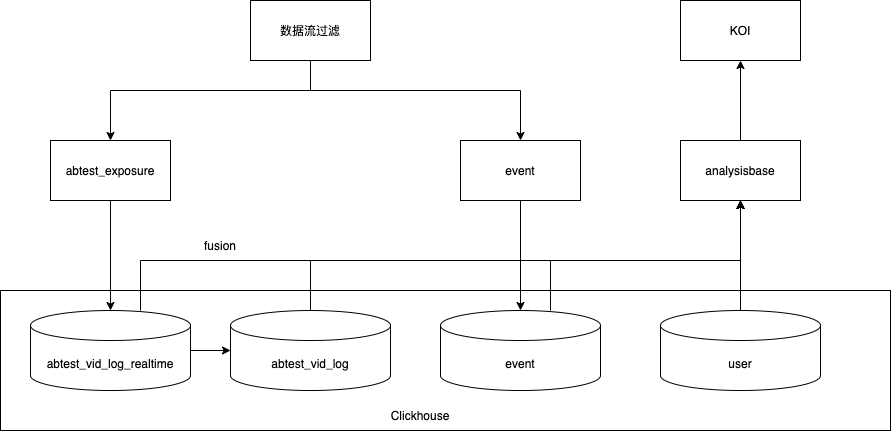
DataTester底层OLAP引擎采用的是clickhouse,根据clickhouse引擎的特点,主要有两个优化方向:



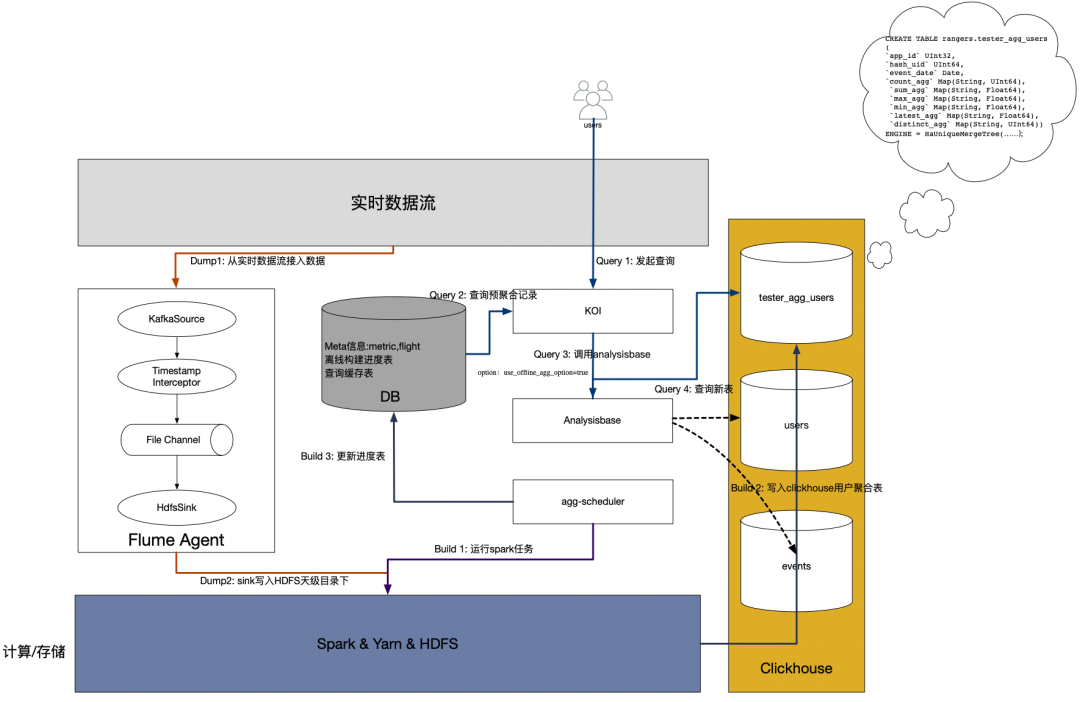
Dump
Parse
Build
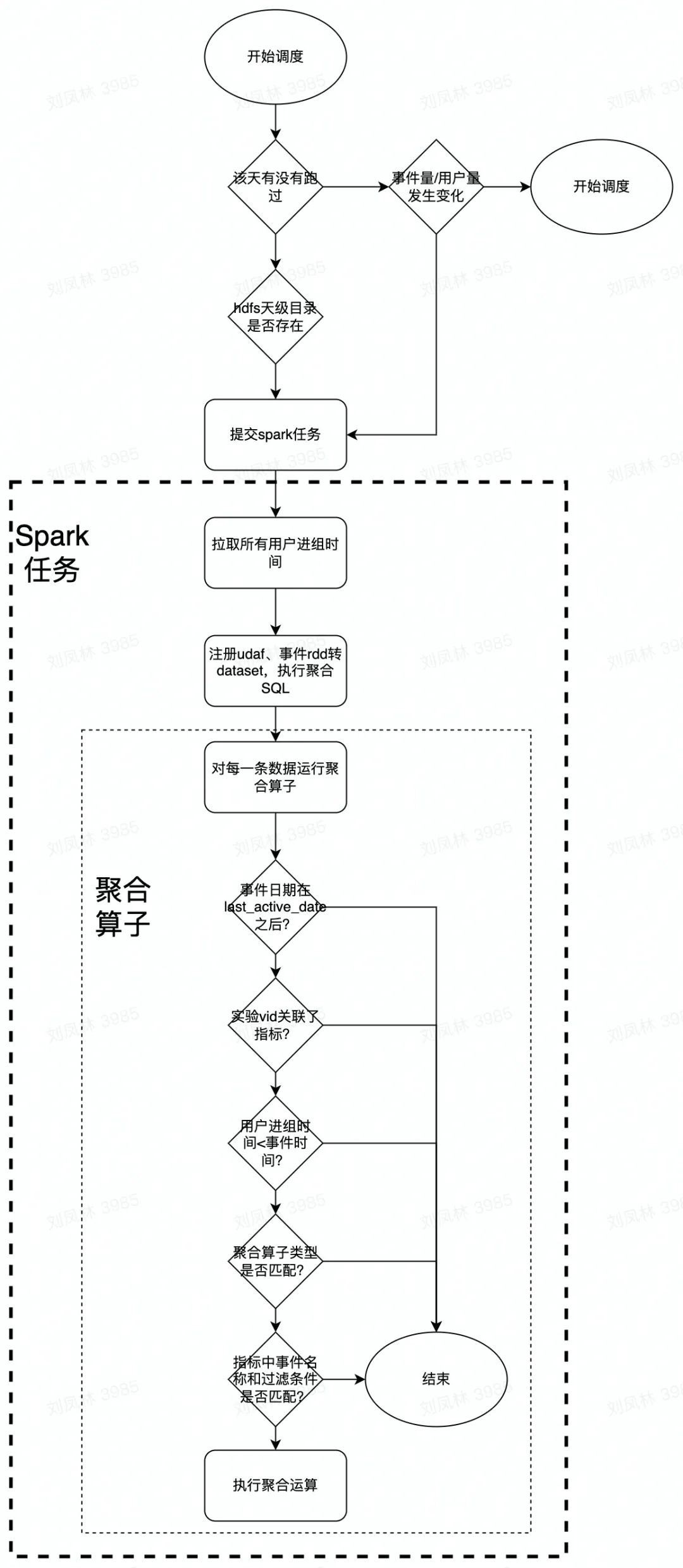
Query
以如下参数为基准,对spark.dynamicAllocation.maxExecutors进行控制:
executor-memory:2g
executor-cores:2

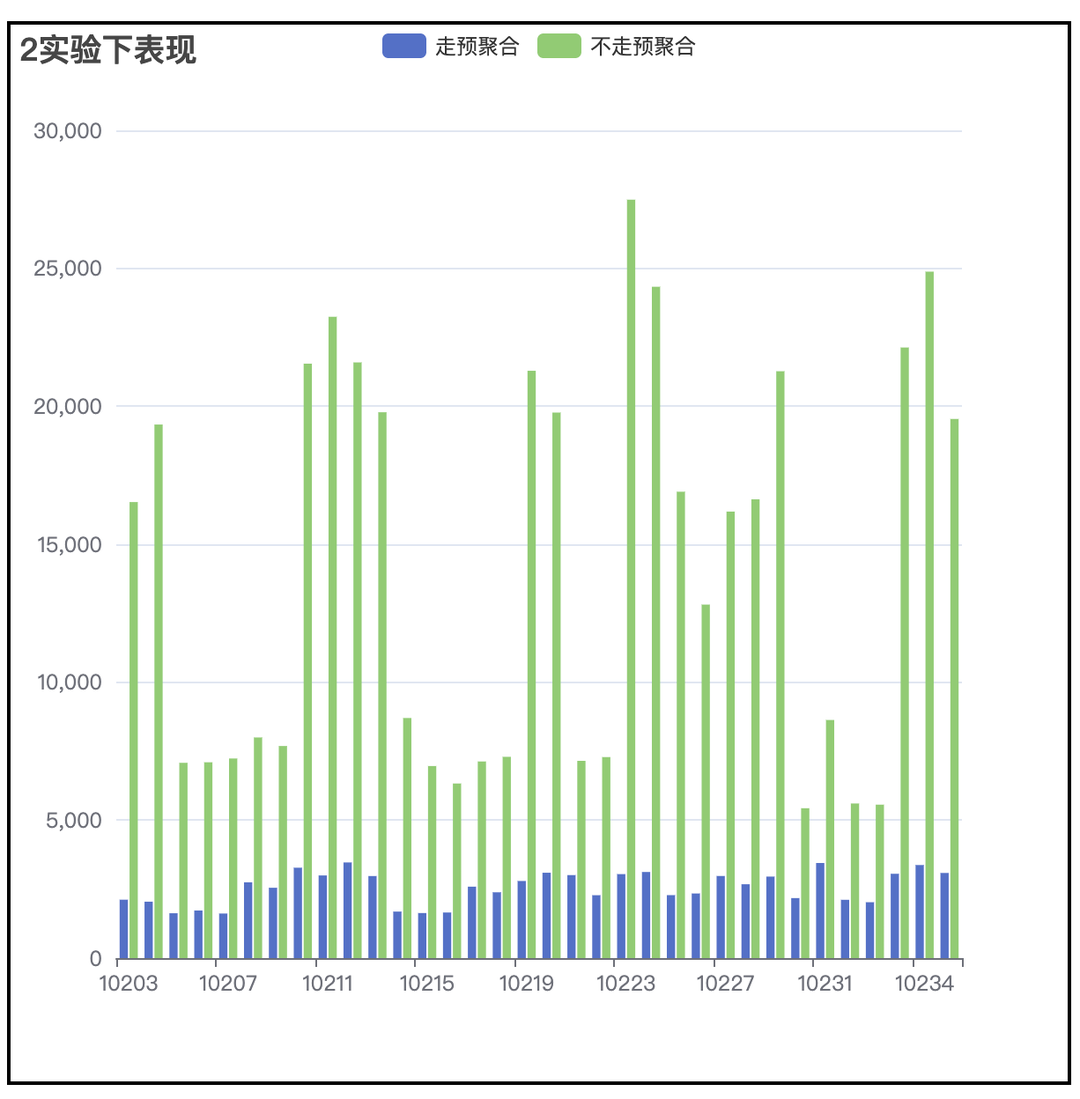
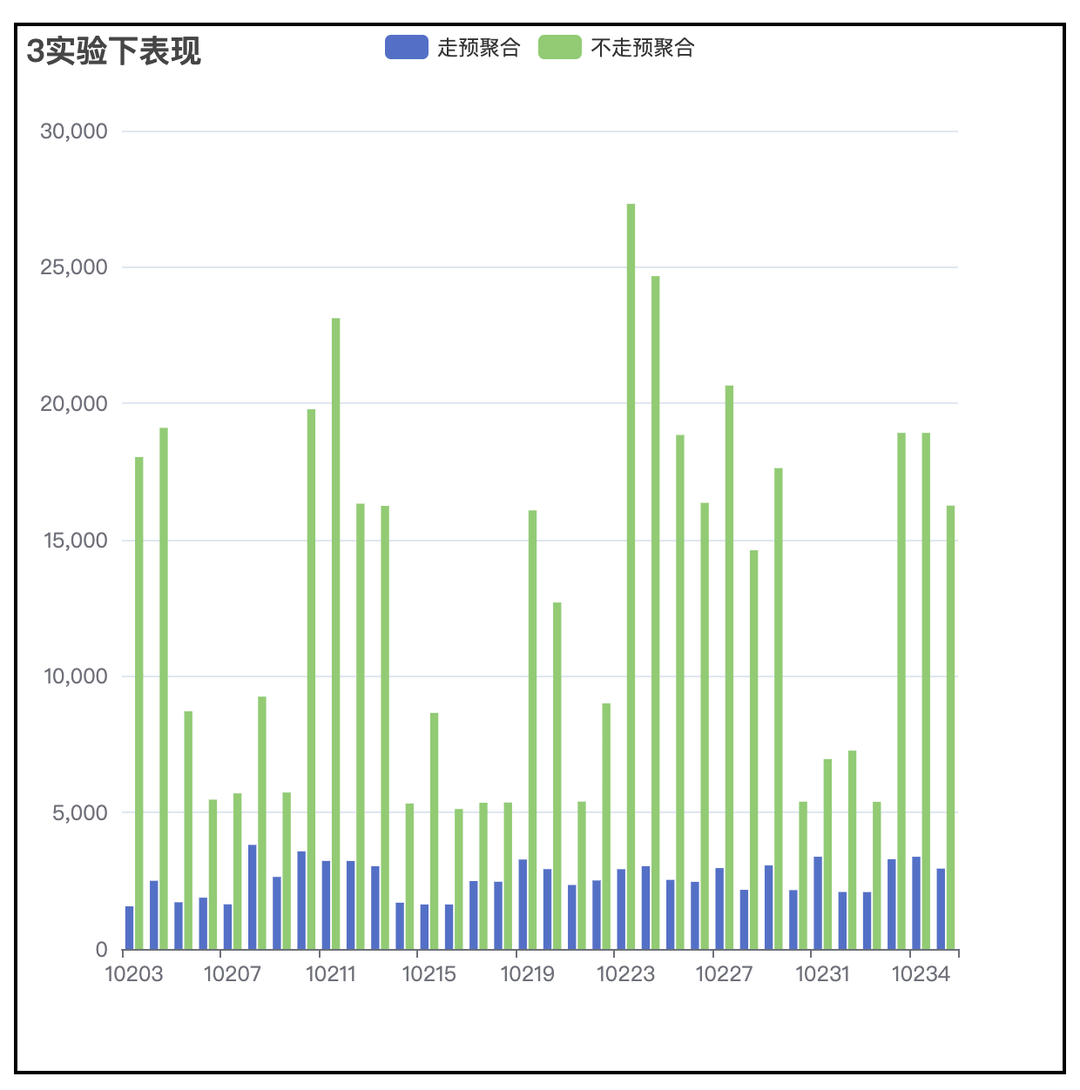
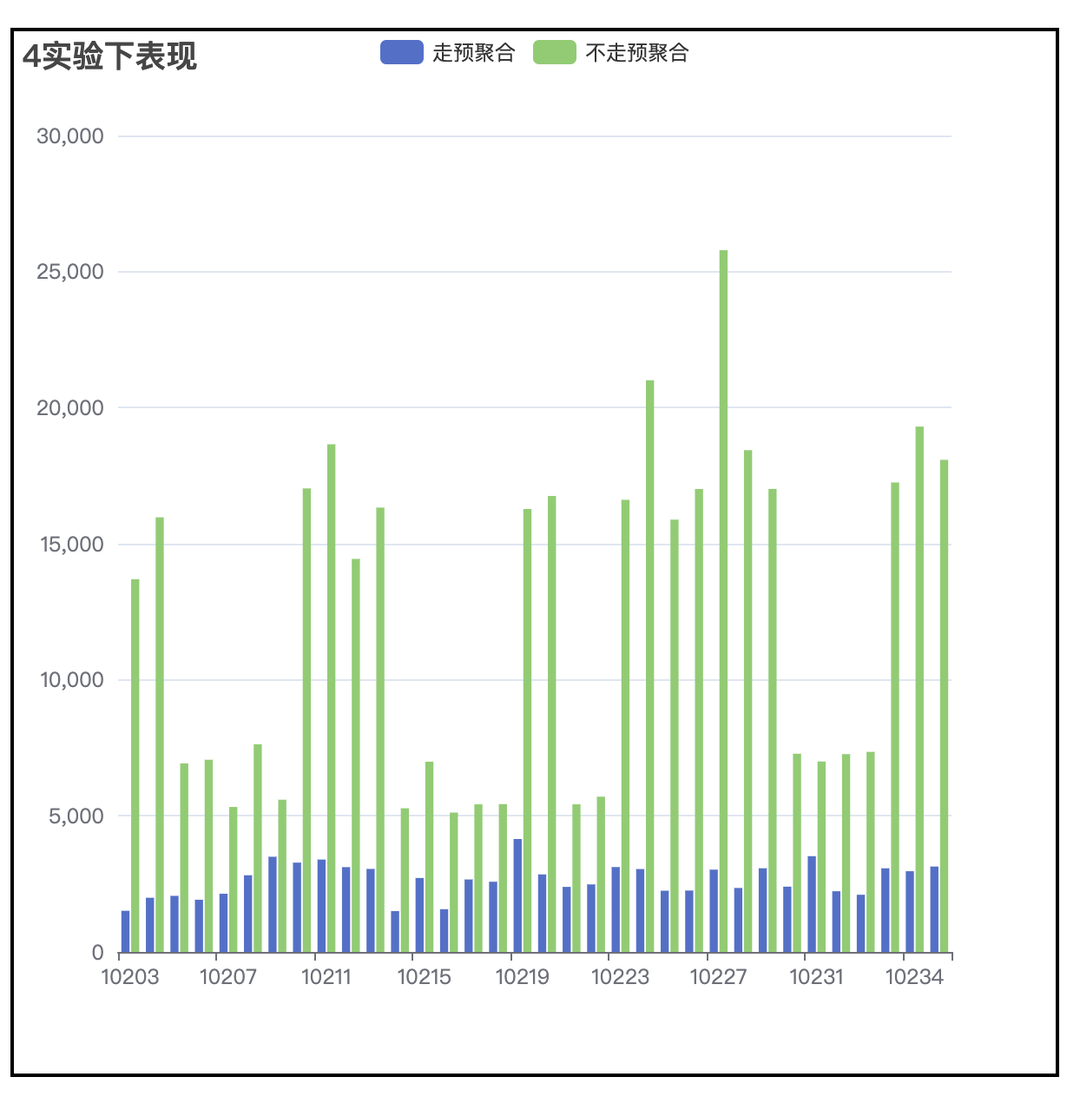
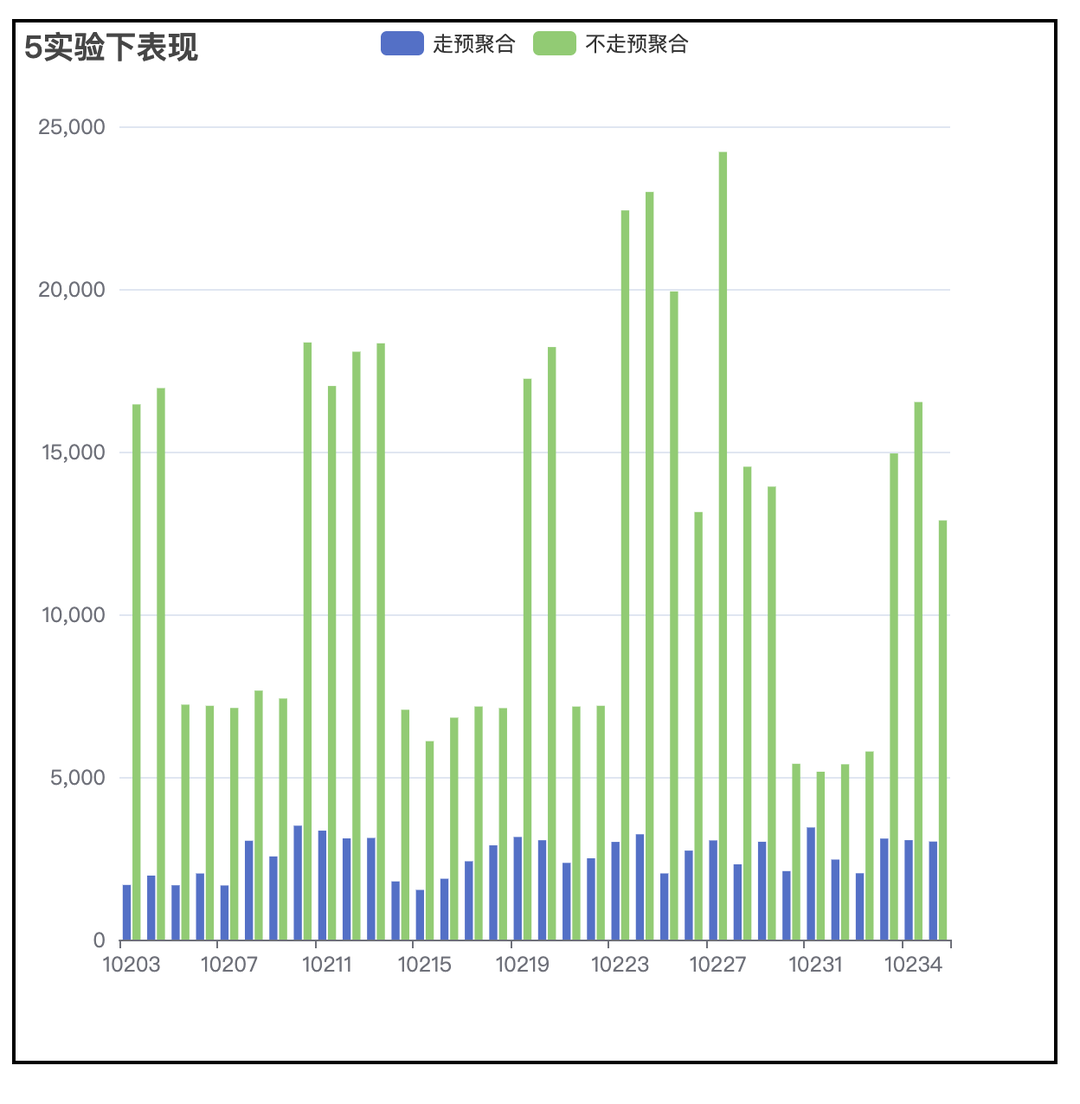

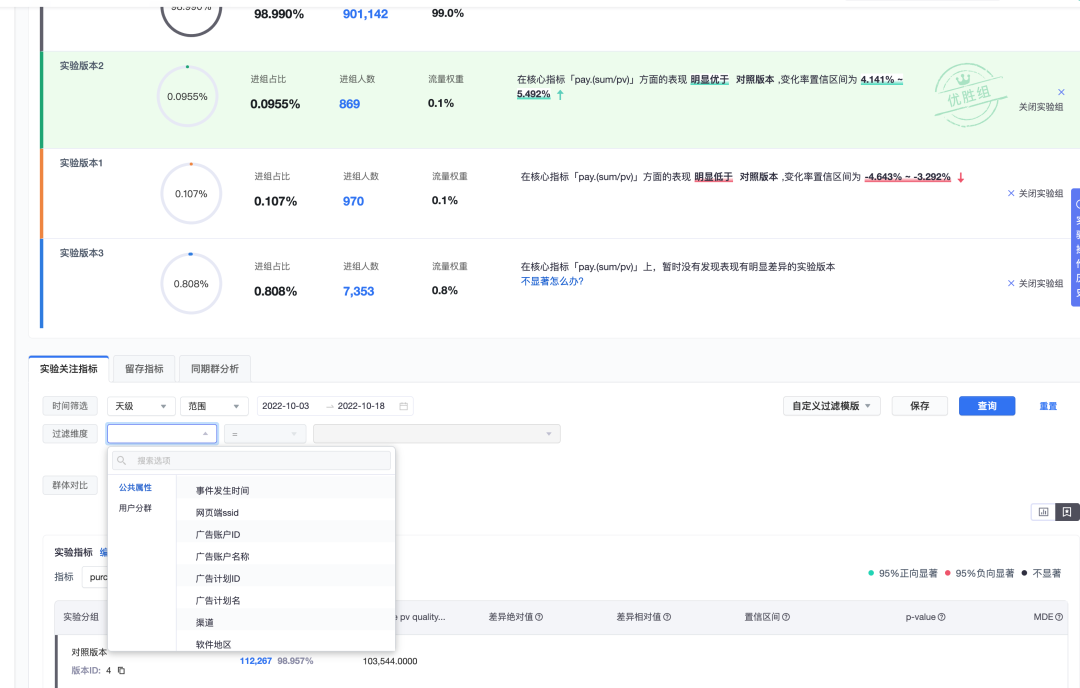
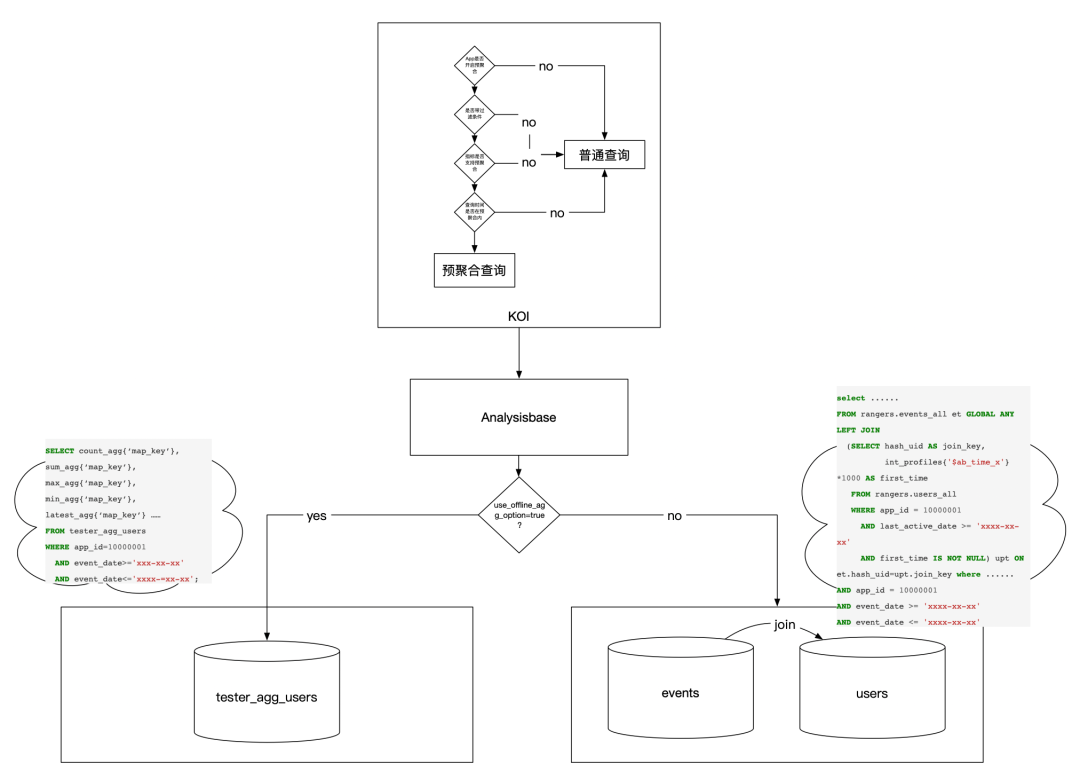
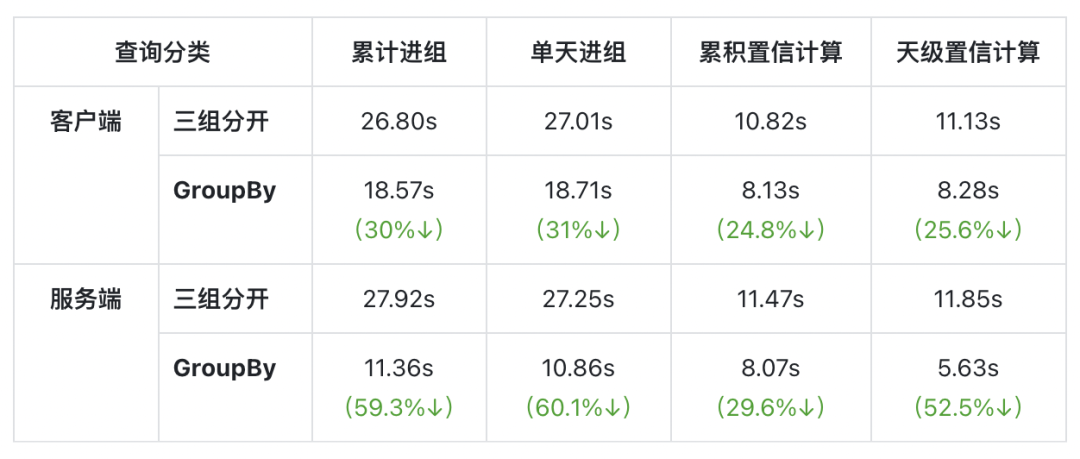
DataTester的数据查询和其他数据应用产品不同,DataTester在数据查询时,所有的查询都会针对每一个实验版本都查一遍,而过程中中唯一的区别就在于实验版本ID,所以和SQL中GroupBy的应用场景特别契合,通过GroupBy查询不仅可以极大的减少查询的数量,也可以降低多次查询造成的重复扫表,提高查询效率。
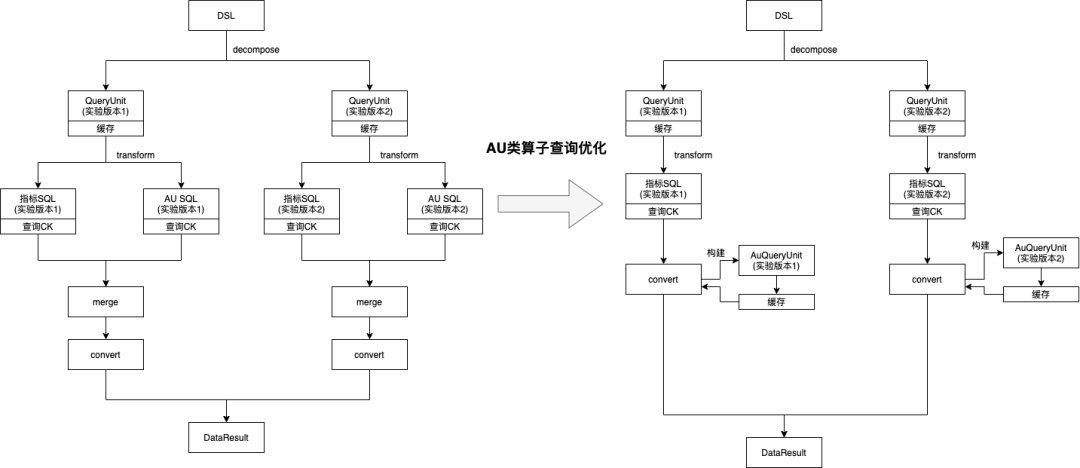
指标查询引擎对DataTester的au类型算子都做了定制,一个指标查询会产生两条sql,一条正常指标的查询sql,另一条是对any_event的au的查询,在最后结果处理的时候对两条sql的查询结果做了一个合并,一起返回到DataTester的科学计算模块。但是,每次打开报告页都必定会查进组人数,它和any_event的au是同一个值,au类型算子查询的时候无法复用进组人数的结果,而au查询又可以算是最慢的查询之一,降低了报告页打开的速度。
DataTester报告页等一些查询数据的接口本身确实比较耗时,需要实时计算,而大部分网关都有超时限制,这个问题在私有化中尤为明显,所以对报告页的整体交互做了优化改造。
前后端交互
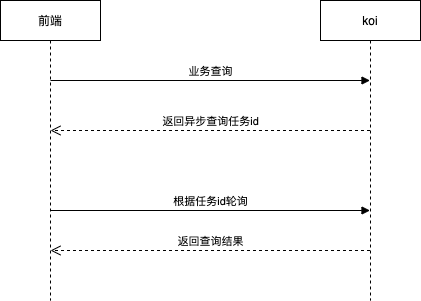
服务端架构设计
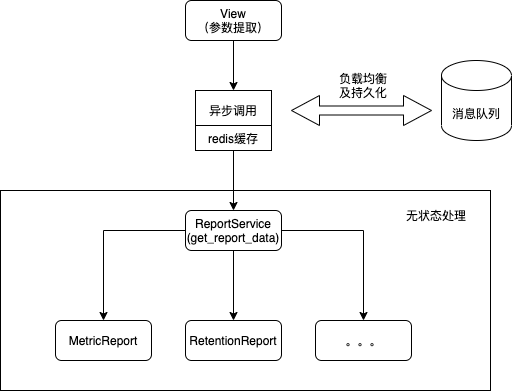
④ 灵活开关多种报告的缓存,保证核心链路正常运行
03
总结

文章转载自DataFunTalk,如果涉嫌侵权,请发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
