




摘要:本文整理自 Apache Flink Contributor 俞航翔 9 月 24 日在 Apache Flink Meetup 的分享。主要内容包括:
Checkpoint 性能优化之路
解析 Changelog
一览 State/Checkpoint 优化
Tips:点击「阅读原文」查看原文视频&演讲 ppt
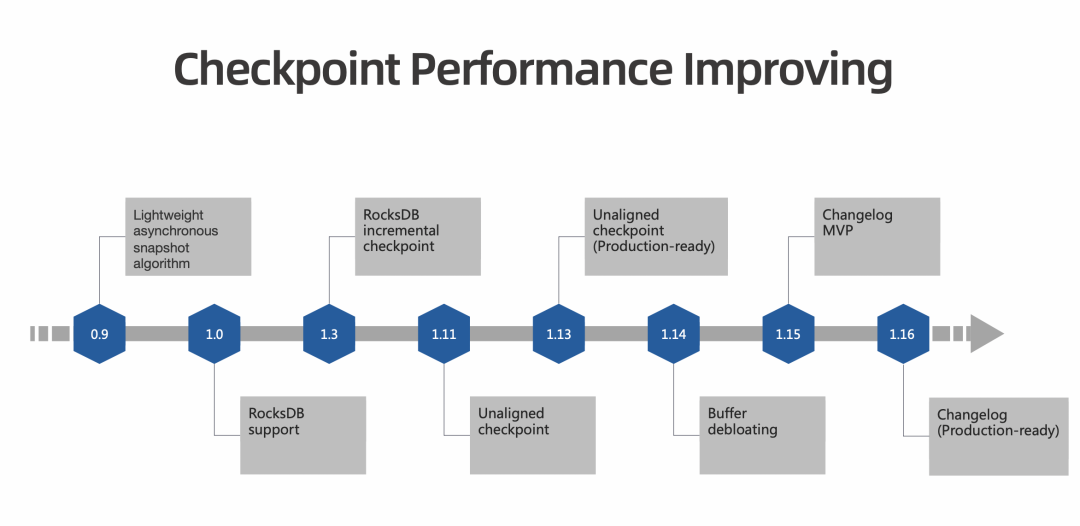
Checkpoint 性能优化之路

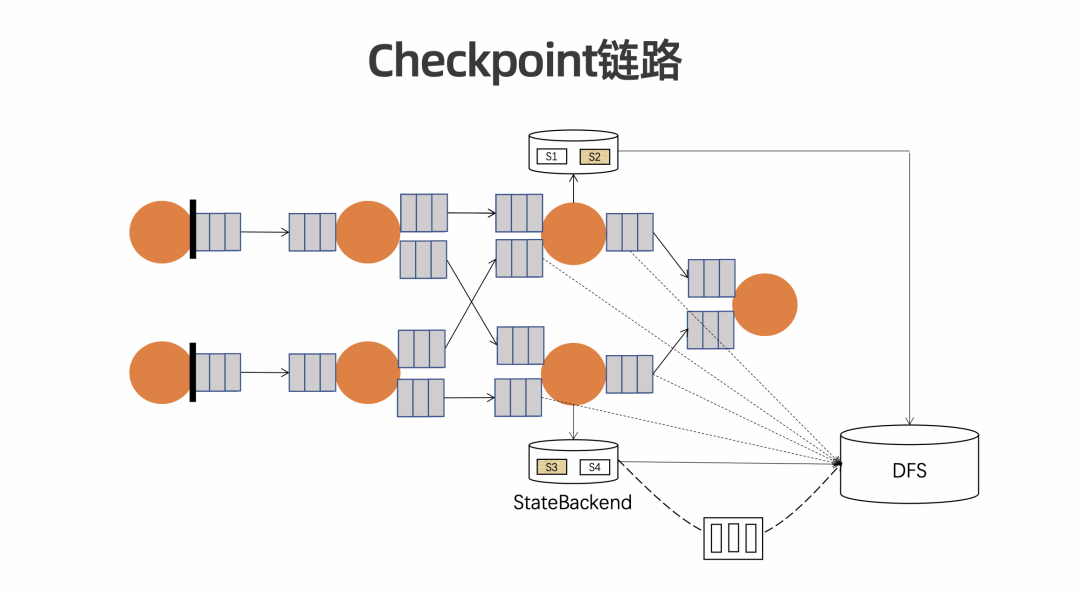
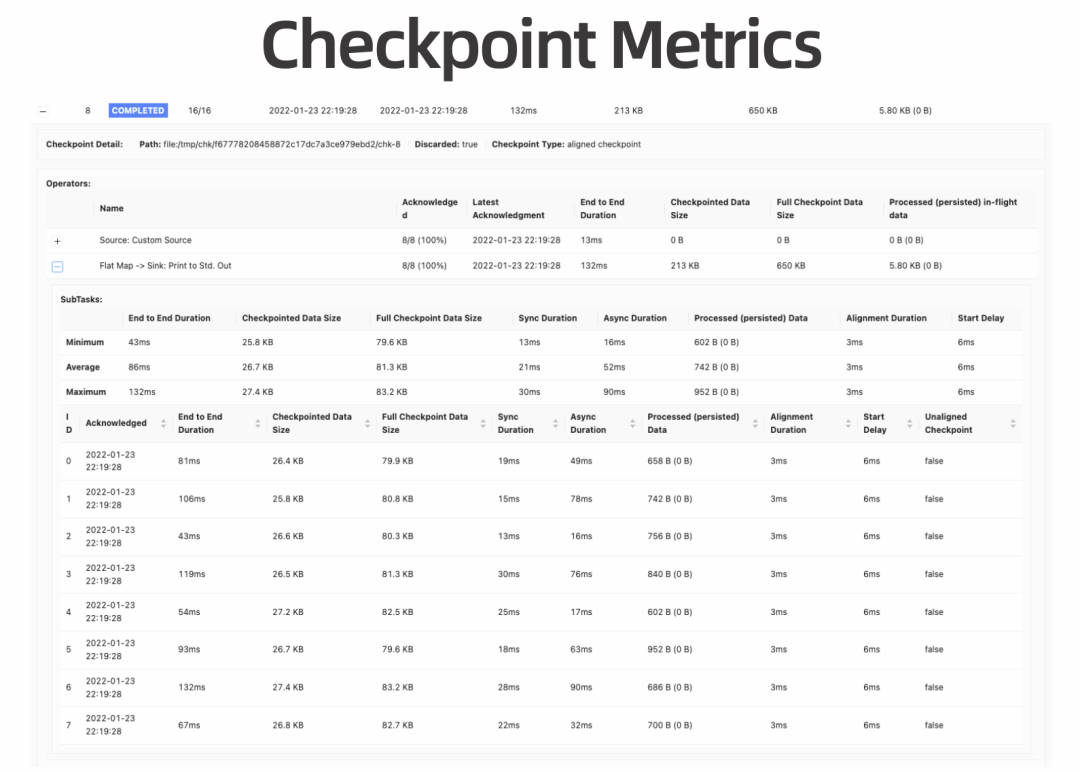
解析 Changelog

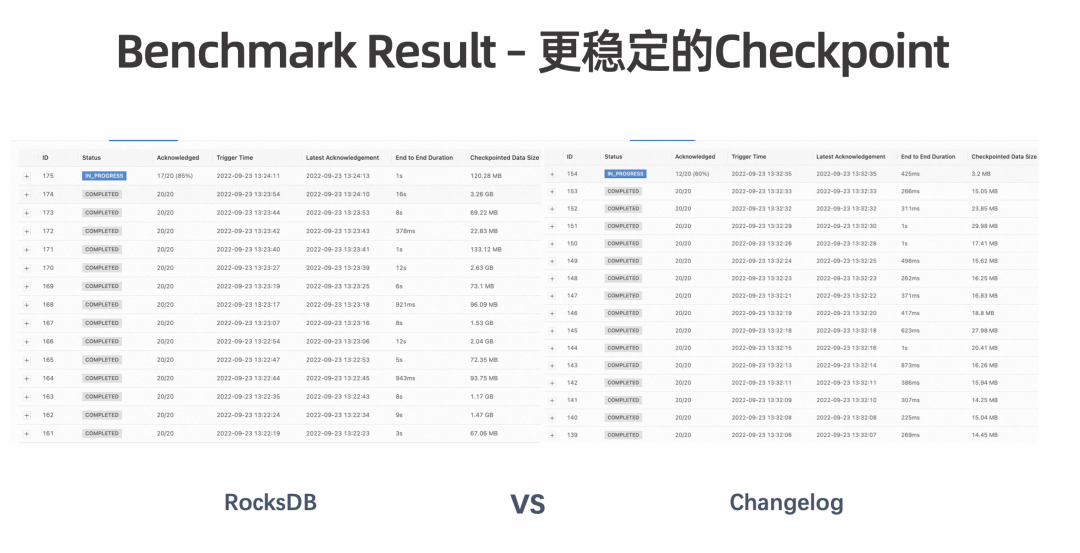
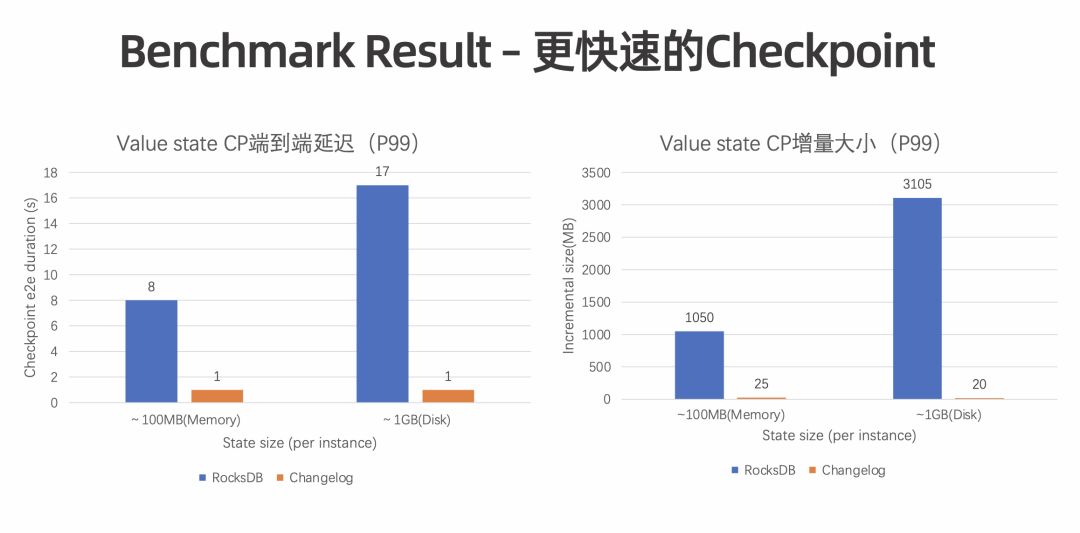
更稳定的 Checkpoint:通过解耦 Compaction 和 Checkpoint 过程,使 Checkpoint 更稳定,大幅减少 Checkpoint Duration 突增的情况,还可进一步减少 CPU 抖动,使网络带宽变得更平稳。 在大规模、大状态作业上经常会出现 CPU 随着 Checkpoint 周期性抖动,进而影响作业和集群稳定性的情况。Changelog 通过解耦 Checkpoint 触发 Compaction 的过程,可以使 CPU 变得更平稳。另外,在异步过程中,Compaction 导致的大量文件同时上传有时会将网络带宽打满, 而 Changelog 是能够缓解该状况的。 更快速的 Checkpoint:Checkpoint 期间会上传相对固定的增量,可以达到秒级完成 Checkpoint 的目标。 更小的端到端延迟:Flink 中实现端到端的 Exactly-once 语义主要依赖于 Checkpoint 的完成时间。Checkpoint 完成越快,Transactional sink 可以提交得更频繁,保证更好的数据新鲜度。后续可与 Table Store 结合,保证 Table Store 上的数据更新鲜。 更少的数据回追:通过设置更小的 Checkpoint Interval 加速 Failover 过程,可以减少数据回追。 虽然目前 Changelog 的机制下,Restore 时在 TM 上会有额外的 Replay 时间开销,但总体来看,耗费的时间还是相对减少的。
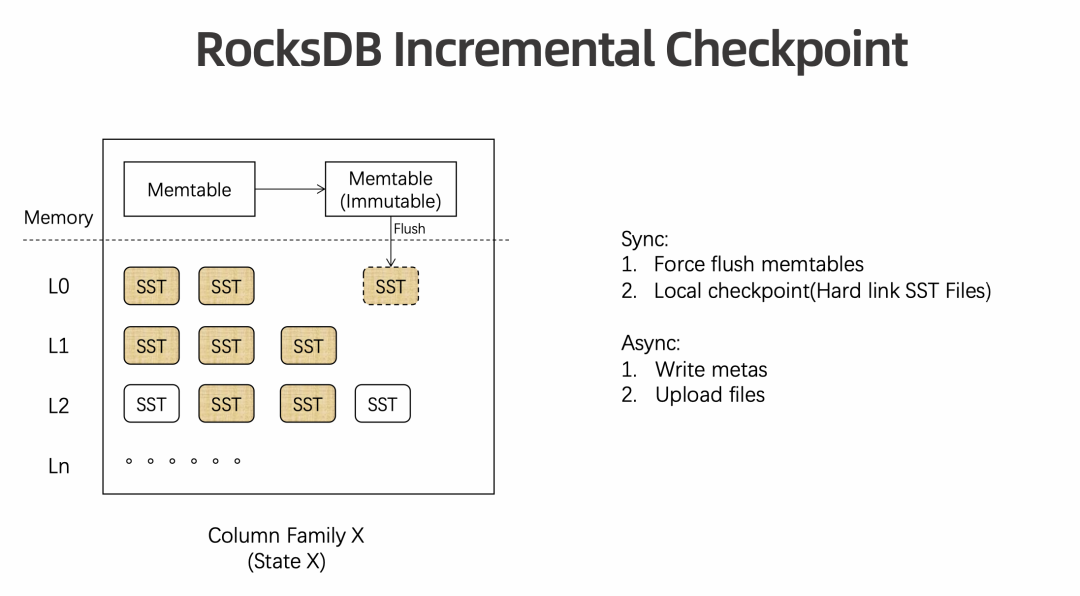
数据量达到阈值,或者 cp 的同步阶段,是会触发 Memtable Flush,进一步触发级联 Level Compation,进一步导致大量文件需要重新上传的 在大规模作业中,每次 Checkpoint 可能都会因为某一个 Subtask 异步时间过长而需要重新上传很多文件。端到端 Duration 会因为 Compaction 机制而变得很长。

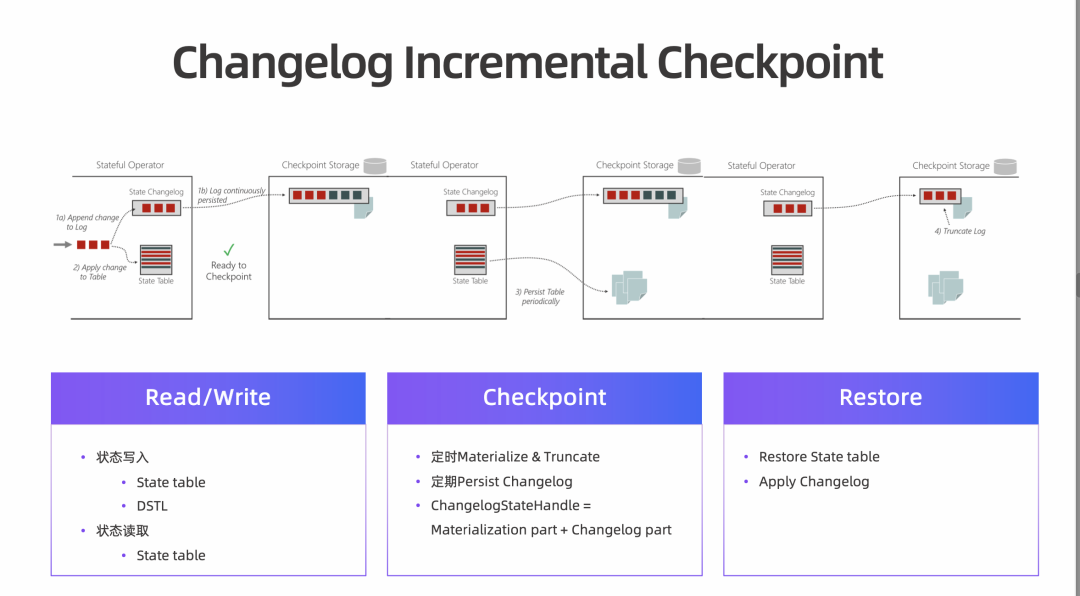
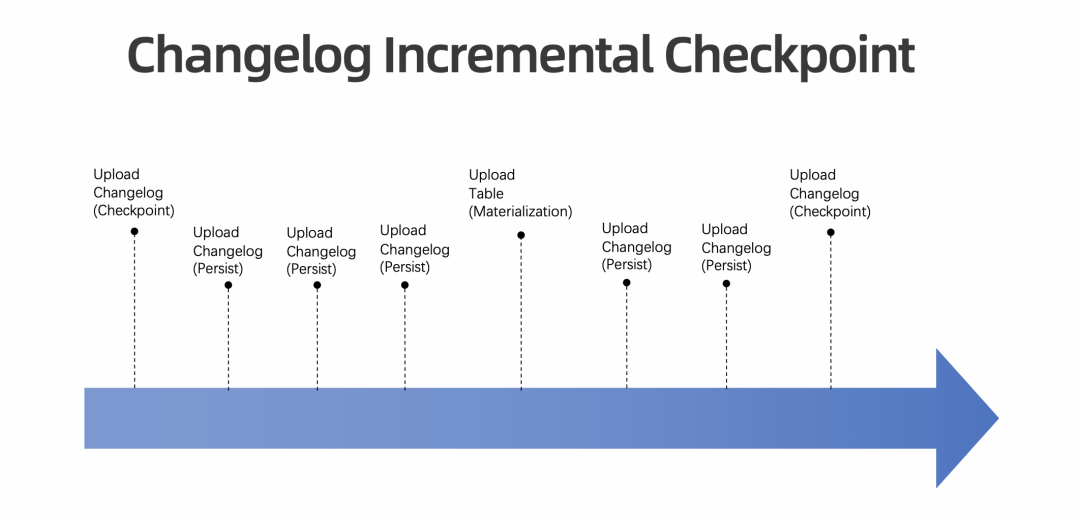
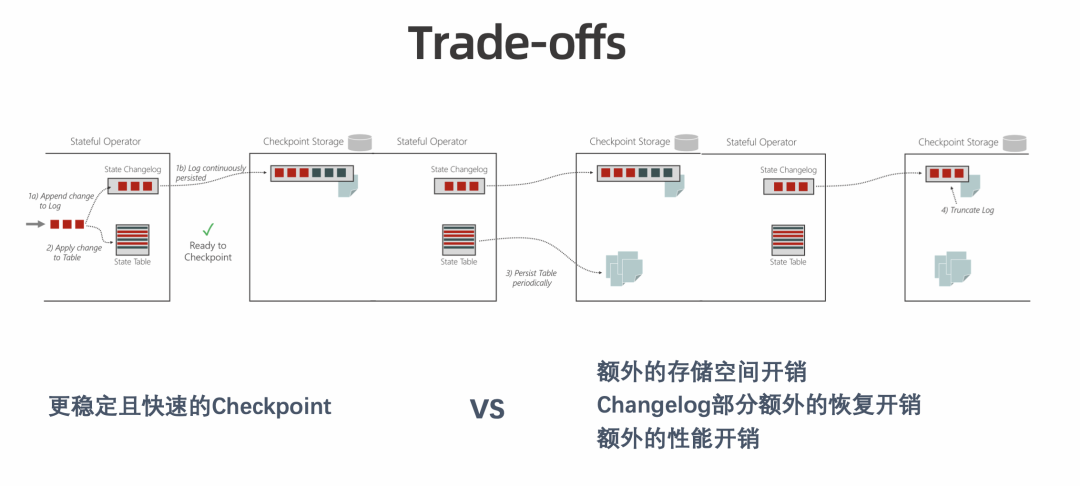
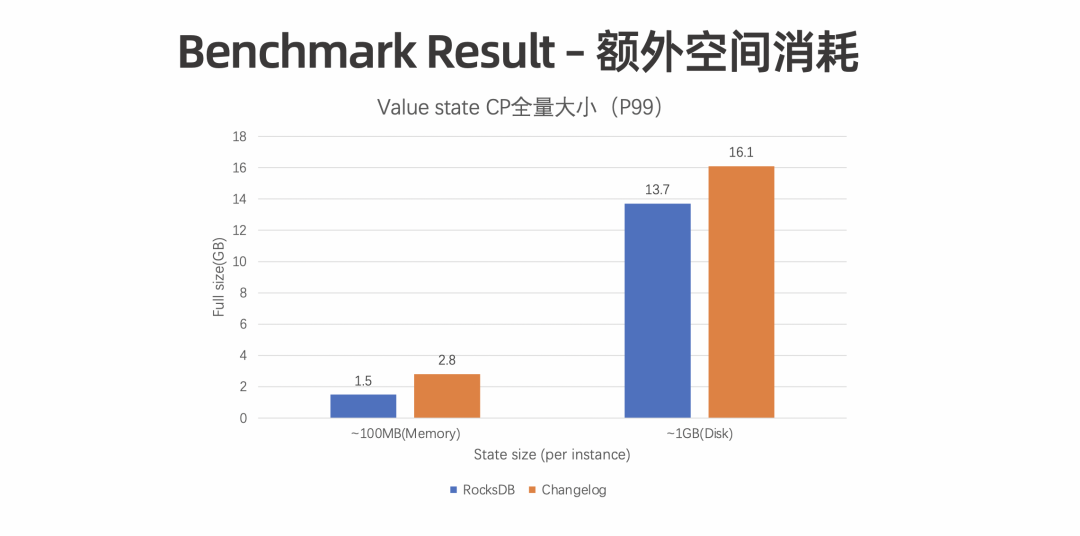
额外的存储空间。Truncate 之前,State Changelog 会一直占用额外的存储空间。 额外的恢复开销。Restore 过程需要额外 Apply 以及额外下载,因此也需要额外的恢复,恢复过程会占用耗时。 额外的性能开销。State Changelog 会做定时上传,存在一定的性能开销。
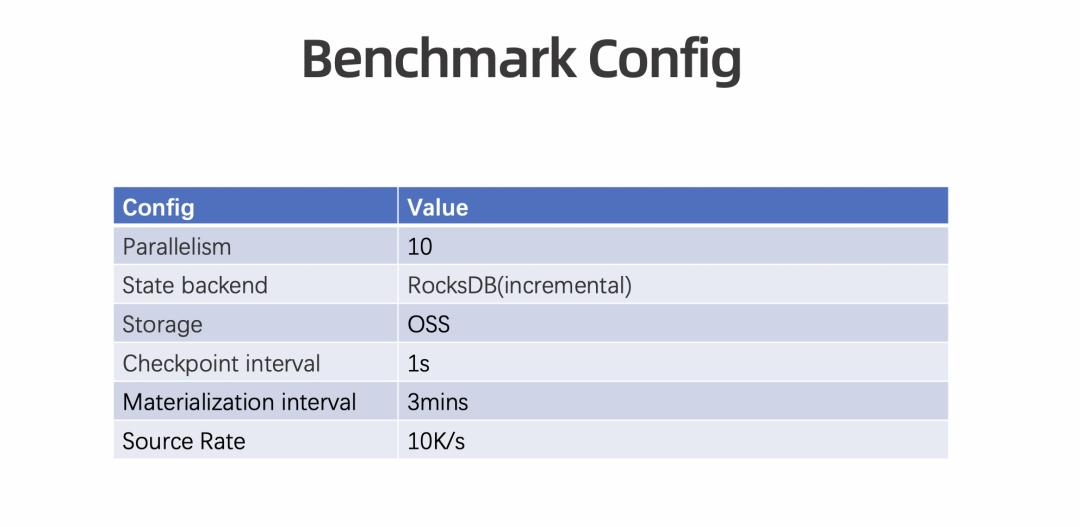
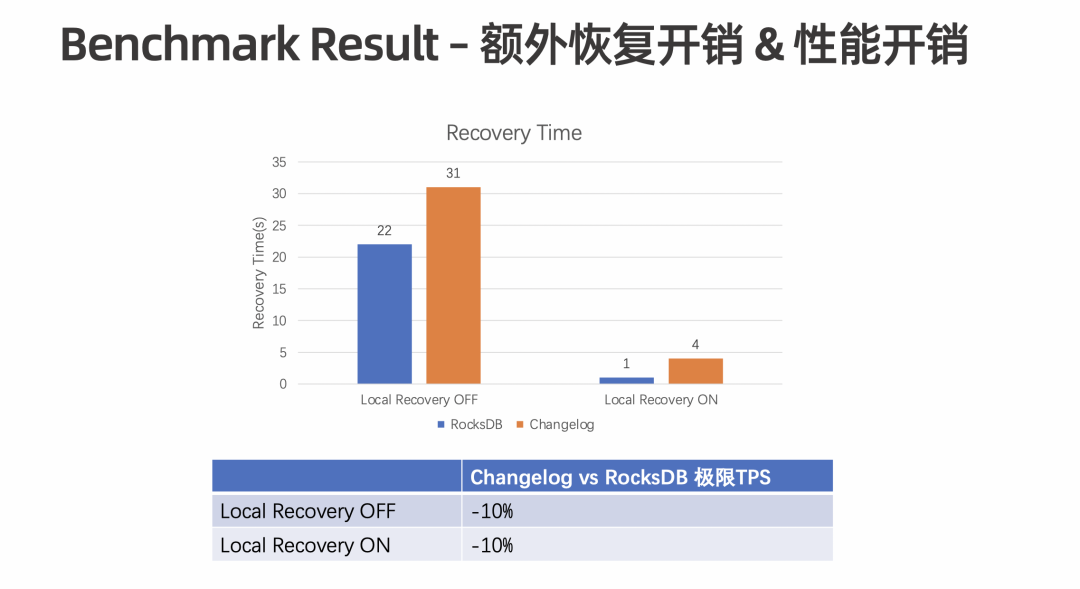
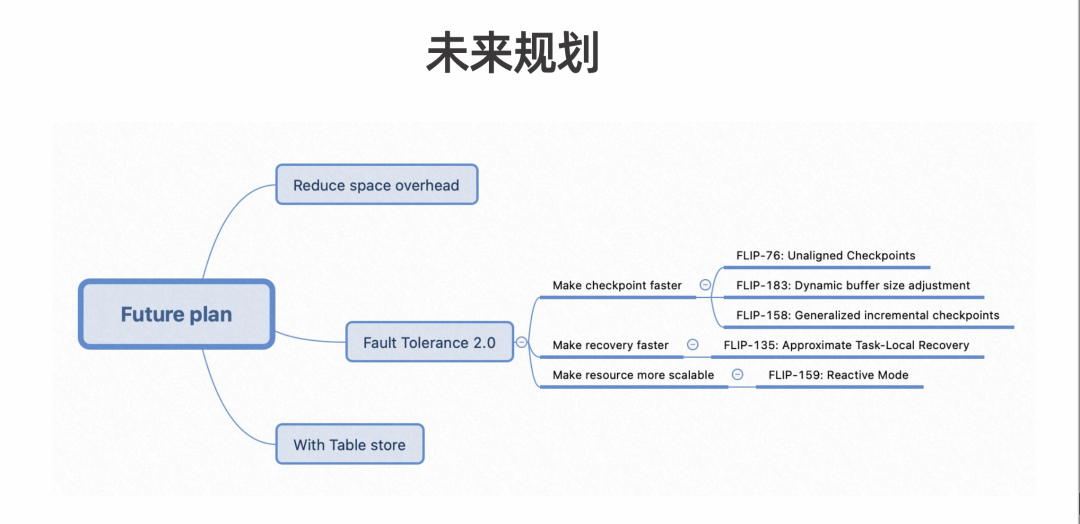
第一,减少空间消耗,以及优化极限 TPS 场景。
第二,结合 Failover 2.0,使 Checkpoint 做得更快、使 Recovery 变得更快以及实现 Reactive Mode 功能。因为在 Reactive Mode 下,增加了资源后会依赖于该机制做 Failover 后重启。如果能够将 Checkpoint 做得更快,状态恢复也会变得更快。
第三,让 Table Store 获得更好的数据新鲜度。
一览 State/Checkpoint 优化

■ 后面在 Flink Forward Asia 2022 核心技术专场分享的文章中,会有更加完整的展示!
往期精选






 点击「阅读原文」,查看原文视频&演讲 PPT
点击「阅读原文」,查看原文视频&演讲 PPT文章转载自Flink 中文社区,如果涉嫌侵权,请发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
