









本期内容
跨版本升级
原集群版本过低,运维难度大,决定进行版本升级。经过测试发现,v5.3.0版本相对于v3.0.10版本性能有很大提升。
于是乎~决定将TiDB v3.0.10升级到TiDB v5.3.0~
本文将分享一下此次跨版本升级的流程。
升级方式
升级方式划分
大体分为停机升级与不停机升级。根据字面意思理解,我们可以根据业务的要求进行选择。
如果业务允许进行停机升级,我们会优先选择停机升级,这会更加安全、快速;如果业务不允许停机的话,则需要通过特定方式来进行滚动升级(不停机升级)
滚动升级对于我们来说或许是一个很好的选择,但问题就是:
业务需求回滚,我们的回滚方案通常需要针对于全备+增量的方式来进行回滚,回滚进度较慢。
因版本差距过大的话,连续进行滚动升级,不可控因素增多。
老版本通常采用Ansible安装,又想让新版本适用tiup进行管理,操作起来较为复杂。
因此,最终决定采用Dumpling+Lightning+TiDB Binlog的方式进行升级,以规避一系列繁琐的问题。
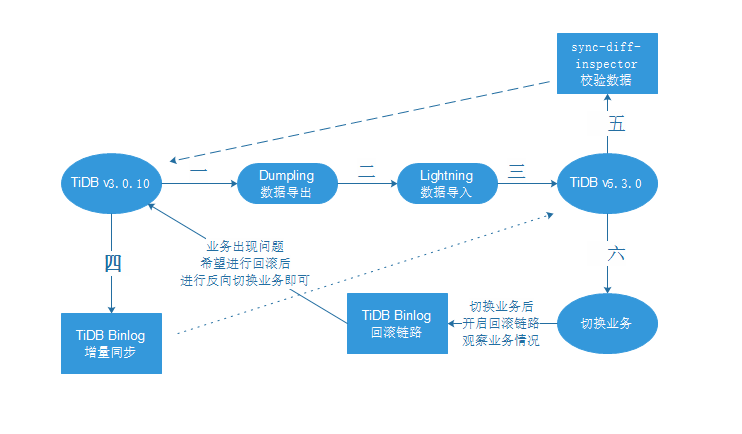
详细过程
获取相关信息
针对兼容性问题,进行详细的调查与测试。
当从一个早期的 TiDB 版本升级到 TiDB v5.3.0 时,如需了解所有中间版本对应的兼容性更改说明,请查看对应版本的 Release Notes。
搭建TiDB v5.3.0的目标集群
#1 编辑拓扑文件topology.yaml
#2 部署TiDB集群
#3 启动TiDB集群
#4 验证集群状态
Dumpling对原集群进行数据导出
数据导出工具Dumpling可以把存储在TiDB/MySQL中的数据导出为SQL或CSV格式,可以用于完成逻辑上的全量备份或者导出。
#适用场景
导出数据量小。
需要导出SQL语句或者CSV的场景,可以在异构数据库或者系统中进行迁移。
对于导出效率要求不高的。由于需要读取数据和转换,所以比起物理导出效率低下。
#选择导出数据的一致性方式
flush(执行时会出现一句 flush table with read olck)只能读不能写(锁全库)
snapshot(会获取指定时间戳的一致性快照并导出)
lock(备份什么锁什么)
none(数据穿越)不用
auto(根据数据库不同选择方式,TiDB选择snapshot Mysql会选择flush)
# 注意事项
确定原集群数据量大小,来判断导出数据所需要的磁盘大小,防止导出数据量过大导致磁盘容量不够报错。
因为我们后续需要搭建Drainer进行增量同步,所以需要在导出之前进行Pump部署和开启Binlog。
为确保导出数据的可用性,判断导入与导出时间,调长GC时间。
#1 编写Dumpling脚本
#2 执行Dumpling脚本,并观察日志
Lightning对目标集群进行数据导入
TiDB Lightning是TiDB数据库的生态工具之一,可以将全量数据高速导入到TiDB集群中。
#使用场景
大量新的数据需要迅速导入到TiDB数据库中。
#Lightning流程
启动Lightning,TiKV会切换到导入模式(他可以对写入进行优化,并且停止数据的压缩)
建立schema和表(就是连接到TiDB Server执行DDL语句,建立相关库和表)
分割表(将表分成一个一个的,做增量的并行导入,提高效率)
读取SQL dump(并发的读取,给转化成键值对)
写入本地临时存储文件(将数据转换成TiDB想通的键值对,然后存储在本地TiKV文件中)
导入数据到TiKV集群(将数据加载到TiKV当中)
检验分析
导入完毕退出并且TiKV切换回普通模式
# 注意事项
注意sorted-kv-dir目录大小,防止导入时候磁盘空间不够。
若 `tidb-lightning` 因不可恢复的错误而退出(例如数据出错),重启时不会使用断点,而是直接报错离开。为保证已导入的数据安全,这些错误必须先解决掉才能继续。使用 `tidb-lightning-ctl` 工具可以标示已经恢复。
可以关注progress来查看剩余时间与导入效率。
#1 编辑Lightning配置文件
#2 编辑执行Lightning脚本
#3 执行Lightning脚本并查看运行情况
启动Drainer进行增量同步
TiDB Binlog工具可以收集TiDB数据库的日志(binlog),并且提供数据同步和准实时备份功能。
#TiDB Binlog流程
PD获取上游数据库TiDB Server的binlog日志。
分散写入到Pump Cluster(里面有多个Pump组件)(它负责存储自己接收的binlog,并且按时间顺序进行排序)。
在由Drainer进行总排序(一个Drainer对应一个下游数据库或者存储日志或者Apache Karka)。
#Pump组件用于实时记录上游数据库传过来的binlog
多个Pump形成一个集群,可以水平扩容。
TiDB通过内置的Pump Client将Binlog分发到各个Pump。
Pump负责存储Binlog,并将Binlog按顺序提供给Drainer。
#Drainer组件收集Pump组件发送过来的Binlog,进行归、排序、发送给下游数据库
Drainer负责读取各个Pump的Binlog,归并排序后发送到下游。
Drainer支持relay log功能,通过relay log保证下游集群的一致性状态。
Drainer支持将Binlog同步到MySQL、TiDB、Kafka或者本地文件当中。
#TiDB数据库的Binlog格式
与MySQL Binlog的Row格式类似(按事务提交的顺序记录,并且只记增删改,记录每一行的改变)。
以每一行数据的变更为最小单位进行记录。
只有被提交的事务才会被记录,且记录的是完整事务。
在Binlog中会记录主键和开始的时间戳以及提交的时间戳
# 注意事项
在导出数据之前要部署好Pump组件和开启Binlog。
commit\_ts通过dumpling导出数据的目录的metadata获取。
部署完毕查看Pump、Drainer运行状态和checkpoint。
#1 TiDB Binlog集群监控
Pump状态

Drainer状态
#2 编辑Ansible集群文件inventory.ini文件
#3 修改drainer.toml配置文件
#4 部署Drainer
#5 启动Drainer
sync-diff-inspector进行数据校验
sync-diff-inspector 是一个用于校验 MySQL/TiDB 中两份数据是否一致的工具。
该工具提供了修复数据的功能(适用于修复少量不一致的数据)
#主要功能
对比表结构和数据。
如果数据不一致,则生成用于修复数据的 SQL 语句。
支持不同库名或表名的数据校验。
支持分库分表场景下的数据校验。
支持TiDB主从集群的数据校验。
支持从TiDB DM拉取配置的数据校验。
# 注意事项
个别数据类型目前不支持比对,需要过滤掉不可比对的列再进行手工比对。
对于 MySQL 和 TiDB 之间的数据同步不支持在线校验,需要保证上下游校验的表中没有数据写入,或者保证某个范围内的数据不再变更。
支持对不包含主键或者唯一索引的表进行校验,但如果数据不一致,生成的用于修复的 SQL 可能无法正确修复数。
snapshot配置通过checkpoint获得。
#1 获取ts-map
#2 编辑sync-diff-inspector
#3 创建sync-diff-inspector启动脚本
#4 运行sync-diff-inspector脚本
搭建回滚链路
回滚链路通过反向搭建一套TiDB Binlog来完成。
回滚链路的Binlog与Pump需要在搭建集群时候同步搭建。
只需要配置好Drainer扩容文件即可,需要回滚时再扩容上去。
升级总结
相对于v3.0.10版本,v5.4.0版本性能上更加稳定,运维起来也更加方便。
针对于这种跨版本的数据库升级,我相信它会是一种操作比较多也是比较重要的项目。在这里只是简单的介绍了方法的流程与步骤。
具体的操作执行,还需要自己进行相应的测试,毕竟对于我们来说,安全、稳定更为重要。
有几个重点我们再次回顾一下:
1、Dumpling导出数据之前一定要开启Pump和Drainer。
2、Dumpling导出数据之前GC时间要进行调整。
3、Lightning导入数据会有部分由于版本差距过大导致的不兼容问题,尽量提前测试、避免。
4、sync-diff-inspector数据校验,针对于不支持的列提前找出并过滤,进行手工比对。
5、记着获取原集群的用户信息导入到目标集群。
6、回滚链路只需要配置好文件在切换业务时候扩容即可。
7、需求回滚时把原业务反向切换。


本期内容就到这里啦
赶紧动手试试吧~
如果还有好的方法
⬇欢迎加入社群一起讨论哦⬇

本期作者
神州数码钛合金团队 付家明

更多精彩内容



了解云基地,就现在!
IT技术哪家强
神州数码最在行
行业新星,后起之秀
历史虽不长,但是实 力 强











