






TiDB
神州数码云基地
在 TiDB 上的尝试、调研与分享
本期作者
漆锐
TiDB 数据库工程师
熟悉 DevOps

用过 TiDB 的小伙伴,或多或少都头疼过 TiDB 读写热点的问题,但这也无法避免。为了有效缓解在实际生产中比较常见的读写热点问题,TiDB 也在各种方面做出了自己的尝试。
比如说,其在 v6.0.0 推出的缓存表,就是一个有效解决小表读热点问题的新特性。
注意这里的定语,有两个:一个是小表,一个是读热点。本篇我们会一一解释。
#了解缓存表
在 TiDB 中,数据调度的最小单位为region,新建一张表,意味着新建一个 region 。如果这张表的数据不够多的话,默认情况下,这些数据就只会存在这一个 region 上。
这样,在 TiDB 上频繁对这些小表进行读查询时,就很容易出现对某个 region 的热点操作,出现读热点问题。这会对 TiKV 造成一定的压力,进而导致整个集群出现性能瓶颈,这也就是前面提到的小表读热点问题。

缓存表,主要就是将这种小表中的数据,先一步从 region 读到TiDB Server的内存中缓存起来,有点类似 MySQL 的内存表。
当查询使用到这种表的时候,就直接从TiDB Server 的内存中读取,进而节省到 TiKV 节点访问相应数据的时间。
此处,我们可以看下缓存表的优点:
1. 减少到 TiKV 节点访问数据的频次,节省分布式组件之间在网络链路上的时间消耗。
2. 不会出现因单个 region 的读热点造成的,TiDB 整个集群的读性能损失。
3. 降低查询时延,提升查询效率,充分利用分布式资源。
同时,缓存表也有使用限制:
1.表大小不超过64MB
因为每张小表会被加载到内存中缓存起来,且这个缓存存在租约时间。缓存过久会失效,需要重新加载,所以表不易过大 。
2.更适于读表
缓存表对写极不友好,因此适合于只读表,或者几乎不会对表中数据进行更新的表。
3.缓存表无法进行DDL操作
无法直接对缓存表进行 DDL 操作,需要将缓存表转换为普通表,才能进行DDL操作。
因此,缓存表的适用场景:
1. 表的数据量不大。
2. 只读表,或者几乎很少修改的表。
3. 表的访问非常频繁,希望避免因出现读热点而造成的性能损失。
TiDB缓存表的典型使用场景如下:
1. 配置表,业务通过该表读取配置信息。
2. 金融场景中的存储汇率的表,该表不会实时更新,每天只更新一次。
3. 银行分行或者网点信息表,该表很少新增记录项。
以配置表为例,当业务重启的瞬间,全部连接一起加载配置,会造成较高的数据库读延迟。如果使用了缓存表,则可以解决这样的问题。
接下来,我们带领大家从源码层面,一点点深入了解缓存表!
#普通表
转换为缓存表
首先来看看普通表转换成缓存表的过程,这里使用的是 SQL 语句: `ALTER TABLE tbl_name CACHE` 。
1、语句被 Parser 解析转化成为
ast 树 ‘ast.AlterTableCache’
// Support caching or non-caching a table in memory for tidb, It can be found in the official Oracle document, see: https://docs.oracle.com/database/121/SQLRF/statements_3001.html| "CACHE"{$$ = &ast.AlterTableSpec{Tp: ast.AlterTableCache,}}| "NOCACHE"{$$ = &ast.AlterTableSpec{Tp: ast.AlterTableNoCache,}}
2、根据语法树类型生成语句
执行器 `Executor`根据语法树类型来生成。
# 比如说这里属于 `DDL`语句,会生成 `DDLExec`。
# 接着由 `DDLExec` 根据解析出来 ` DDL` 语句的`stmt`类型。
# 于是,这里是 `AlterTableStmt` ,就会调用`executeAlterTable` 方法。
# 最终根据`ast.AlterTableCache` 调用 `AlterTableCahe` 方法。
ddl/ddl_api.go:3204 case ast.AlterTableCache:ddl/ddl_api.go:3205 err = d.AlterTableCache(sctx, ident)
3、在AlterTableCahe方法中
主要做的事情:
# 获取表的元信息
schema, t, err := d.getSchemaAndTableByIdent(ctx, ti)if err != nil {return err}
# 根据表的元信息判断
· 判断表是否已经是缓存表,如是,则直接结束执行,然后返回;
· 判断表是否位于系统库,如是,则会报错,不支持将系统库中的表转换为缓存表;
· 判断表是否是视图或临时表,如是,则会报错;
· 判断表是否为分区表,如是,则会报错;
// if a table is already in cache state, return directly// 如果表已经是缓存表,则直接返回,model.TableCacheStatusEnableif t.Meta().TableCacheStatusType == model.TableCacheStatusEnable {return nil}// forbit cache table in system database.// 禁止缓存存在于系统库中的表(这里源码注释写的是forbit,笔者猜测是写错了,应该是 forbid,禁止)if util.IsMemOrSysDB(schema.Name.L) {return errors.Trace(dbterror.ErrUnsupportedAlterCacheForSysTable)// 判断表的TempTableType 是否为TempTableNone,如不是,则就是临时表或者视图中的一种,会报错} else if t.Meta().TempTableType != model.TempTableNone {return dbterror.ErrOptOnTemporaryTable.GenWithStackByArgs("alter temporary table cache")}// 如果表为分区表,也不能转换为缓存表if t.Meta().Partition != nil {return dbterror.ErrOptOnCacheTable.GenWithStackByArgs("partition mode")}
# 计算表的大小若超过限制,会报错
succ, err := checkCacheTableSize(d.store, t.Meta().ID)if err != nil {return errors.Trace(err)}if !succ {return dbterror.ErrOptOnCacheTable.GenWithStackByArgs("table too large")}
计算表大小的主要逻辑:
# 执行一个 SQL语句
往 `mysql.table_cache_meta`中插入一条数据,并记录信息
ddlQuery, _ := ctx.Value(sessionctx.QueryString).(string)// Initialize the cached table meta lock info in `mysql.table_cache_meta`.// The operation shouldn't fail in most cases, and if it does, return the error directly.// This DML and the following DDL is not atomic, that's not a problem._, err = ctx.(sqlexec.SQLExecutor).ExecuteInternal(context.Background(),"insert ignore into mysql.table_cache_meta values (%?, 'NONE', 0, 0)", t.Meta().ID)if err != nil {return errors.Trace(err)}ctx.SetValue(sessionctx.QueryString, ddlQuery)
# 生成 DDLjob
生成 `model.ActionAlterCacheTable` 类型的 `DDLjob`,然后调用 `doDDLjob`执行
job := &model.Job{SchemaID: schema.ID,SchemaName: schema.Name.L,TableID: t.Meta().ID,Type: model.ActionAlterCacheTable,BinlogInfo: &model.HistoryInfo{},Args: []interface{}{},}err = d.doDDLJob(ctx, job)
4、 进入到 DDLjob 的执行阶段
刚刚我们已经生成了 `DDLjob`。
接下来进入到该 `DDLjob` 的执行阶段,会根据类型调用 `onAlterCacheTable` 方法,这个方法中的主要逻辑如下:
# 获取表元信息,进行一系列判断
// 获取表元信息tbInfo, err := getTableInfoAndCancelFaultJob(t, job, job.SchemaID)if err != nil {return 0, errors.Trace(err)}// If the table is already in the cache state// 判断表是否已经是缓存表,如是则会直接结束该jobif tbInfo.TableCacheStatusType == model.TableCacheStatusEnable {job.FinishTableJob(model.JobStateDone, model.StatePublic, ver, tbInfo)return ver, nil}// 没错,这里又会判断一遍是否为临时表、视图或者分区表if tbInfo.TempTableType != model.TempTableNone {return ver, errors.Trace(dbterror.ErrOptOnTemporaryTable.GenWithStackByArgs("alter temporary table cache"))}if tbInfo.Partition != nil {return ver, errors.Trace(dbterror.ErrOptOnCacheTable.GenWithStackByArgs("partition mode"))}
# 转换表

走到这里,会发现转换过程已经结束了,而文档提到的最重要的一个机制,lease,在整个转换过程中并未出现。
让人不禁好奇,缓存表最重要的租约时间,是在哪赋予给表的?此时表中的数据已经缓存到tidb-server 内存当中了吗?不急,我们接着往下看:
# lock & lease
为了实现缓存表,同时为了保证数据的准确性,TiDB 引入了一套基于 lease 的复杂机制。
在 lease 期间内,只能对表做读操作,此时会对表上一个 READ lock,同时阻塞写操作,而READ lease 过期之后,才能对该表执行数据修改的操作。
此时会到 TiKV 中修改,同时读操作也会到 TiKV中读取相应数据,此时读的性能会下降,进而需要续约。不禁又有疑惑,续约租期时间是怎么续的?

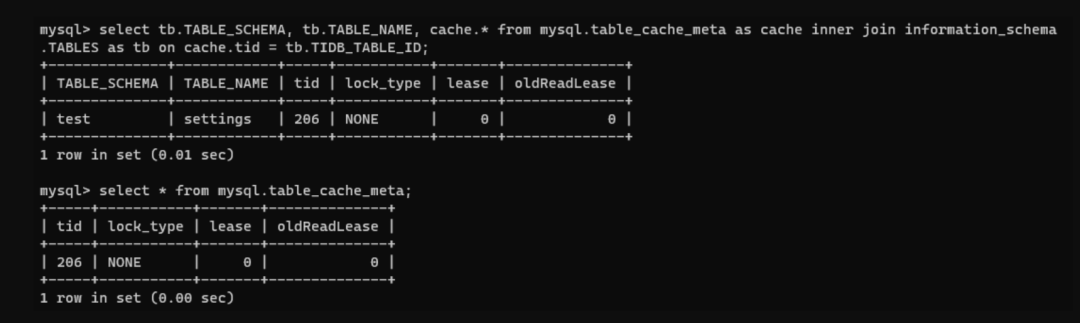
刚创建缓存表,没有对该表做任何查询、更新操作。通过mysql.table_cache_meta去看该表的 CACHE 信息,会发现,该表此时是没有上锁,也没有租约时间的😣。
按照小编的想法,这里应该有个READ lock,但事实是没有的,刚创建的缓存表,lock_type 为 NONE,lease 也为 0 。
此时,查询数据会直接从缓存中读数据吗?
通过trace来看,缓存表刚创建时,第一次读取读表中数据,还是会通过rpcClient.SendRequest 到 TiKV 中查询数据。此时数据是还存储在 TiKV中,而在lease 时间内,再读一次,会发现此时数据是通过 memTableReader.getMemRows 从缓存中读取。
这时,前面的疑惑就解开了:缓存表刚创建时,表中的数据还没有缓存到tidb-server 的内存当中,而是在读取一次之后,才会缓存数据;同时赋予表 lease 期限,这也意味着在 lease 期间读数据,都是直接从 tidb-server的内存中读取数据。

关于续约的问题也迎刃而解了,当租约过期之后,TiDB 是不会主动从TiKV 中将对应的数据读取到 tidb-server 的内存中缓存起来的,当重新再读这张表的时候,就会被赋予一个新的 lease期限,就相当于续约啦。
#写在最后
本篇带领大家从源码层面,了解整个缓存表的创建过程,对其源码有一个简单的分析与介绍。同时,对于缓存表的 lease 机制有一个简单的解释。其实里面还有很多复杂的设计,也十分的精彩😎。
但,这个表也存在一些令人费解的地方。
比如:
1. 如果不翻看源码,很难发现这个表的存在,妥妥一个隐藏款😅
2. 这张表在使用体验上,目前还并不是那么完善。
3. 如果将缓存表变为普通表,mysql.table_cache_meta中的记录并不会被删除,如果删除,是否会更好呢?
...
不过,作为一个在v6.0.0 DMR 推出的新特性,其在解决小表读热点问题上的突出表现!这已经十分优秀了~纵使存在一点不足之处,相信在后面,会慢慢变得完善,完美!
对此,你还有什么想讨论的呢?
欢迎到我们的TiDB社群一起唠唠嗑呀
👇👇👇
扫描下方二维码,
加入群聊,关于 TiDB 你想了解的全都有!

#更多精彩内容





