




在之前关于数据库一致性的博客中,我们详细讨论了应用程序在处理最终一致的NoSQL数据库时所面临的风险和挑战。我们也打破了最终一致的数据库比强一致的数据库表现更好的神话。在这篇博客中,我们将更深入地研究YugaByte数据库是如何在提供强一致性的同时优于Apache Cassandra这样的最终一致性数据库的。注意,YugaByte DB保留了与Cassandra Query Language (CQL) API的drop-in兼容性。
YugaByte DB vs Apache Cassandra性能
雅虎云服务基准测试(YCSB)是一个广为人知的NoSQL数据库基准测试。我们对YugaByte DB和Apache Cassandra运行了YCSB测试,并且兴奋地发现YugaByte DB在吞吐量和百分之99 (p99)延迟上都比Apache Cassandra要好。
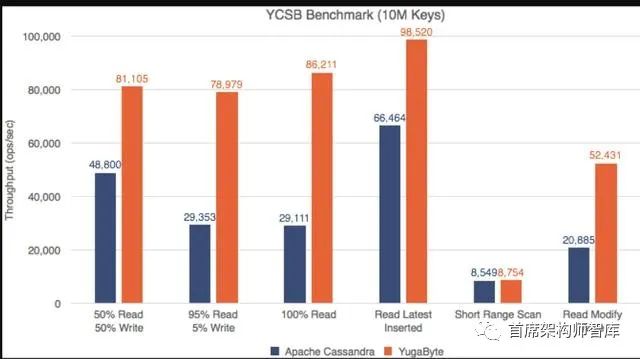
YCSB—读写吞吐量(越多越好)
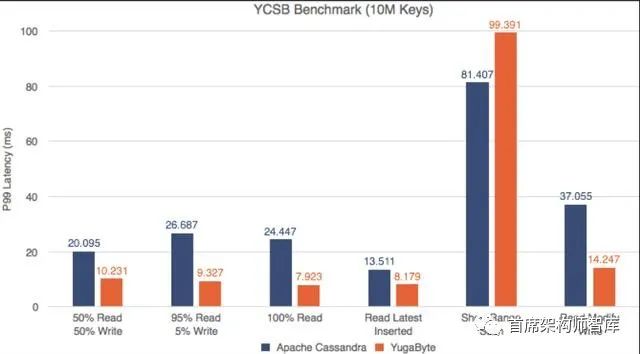
YCSB -读取和写入P99延迟(越少越好)
不仅YugaByte的DB性能更好,而且随着数据密度(更多的键)的增加,边际也会扩大。对详细的性能数字和测试配置感兴趣的读者可以在这里查看我们的文章。
为什么YugaByte DB优于Apache Cassandra?
YugaByte DB优于Apache Cassandra有6个重要的架构上的原因。
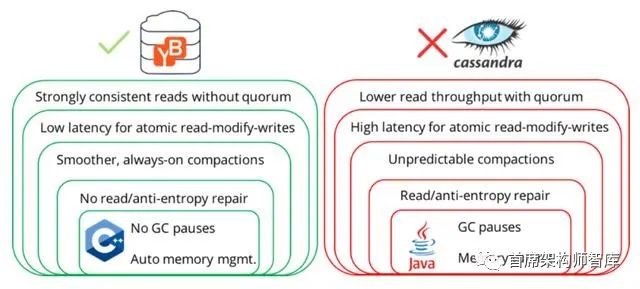
1. 较高的读取吞吐量和较低的延迟
为了使用仲裁读取在最终一致的DB中实现强一致性(到某一点),读操作需要从仲裁中的所有副本中读取数据,以返回大多数仲裁同意的结果。因此,读取的次数乘以复制因子(3x或更多)。同样的复制因子放大了系统负载,从而对系统的吞吐量产生了负面影响。
不仅负载放大了,而且由于从副本读取所需的额外网络往返,响应时间也增加了一倍以上。当网络被额外的流量堵塞时,情况会变得更糟。另外,在读取的关键路径上放置3台服务器会对p99延迟产生不利影响。由于这些架构上的约束,Apache Cassandra的吞吐量较低,延迟较高。
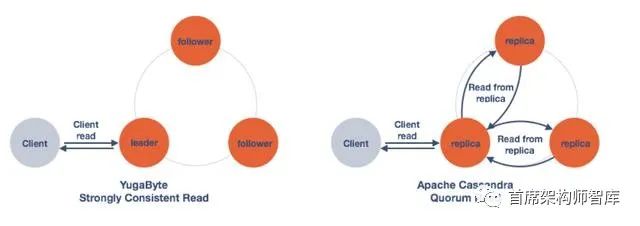
1x vs 3x读取YugaByte vs Apache Cassandra
让我们将其与在读取操作期间执行的YugaByte进行比较。由于使用了RAFT consensus协议,quorum leader持有的数据保证是一致的。所以读操作只需要从前导器读取一次(1x)。因此,如下表所示,YugaByte可以提供更好的性能,因为它既没有读取放大也没有到其他副本的往返。
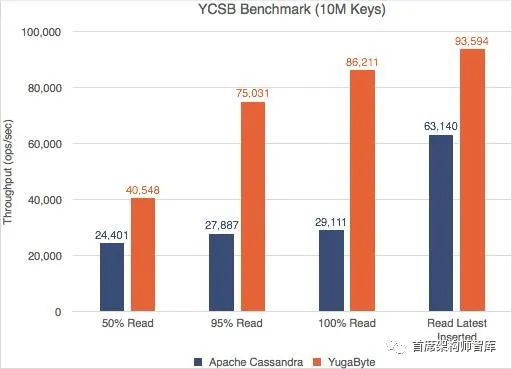
YCSB – Read Throughput (More is Better)
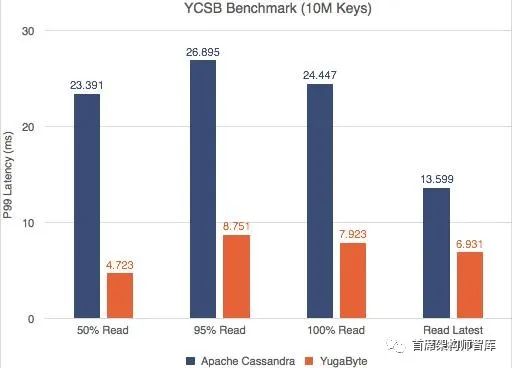
YCSB -读取P99延迟(越少越好)
2. 较高的读-修改-写吞吐量和较低的延迟
非原子的读-修改-写:在上面的读-修改-写工作负载中,YCSB使用两个独立的不带原子性的读和写数据库语句对读-修改-写操作建模。因此,我们已经看到YugaByte DB比Apache Cassandra更好。
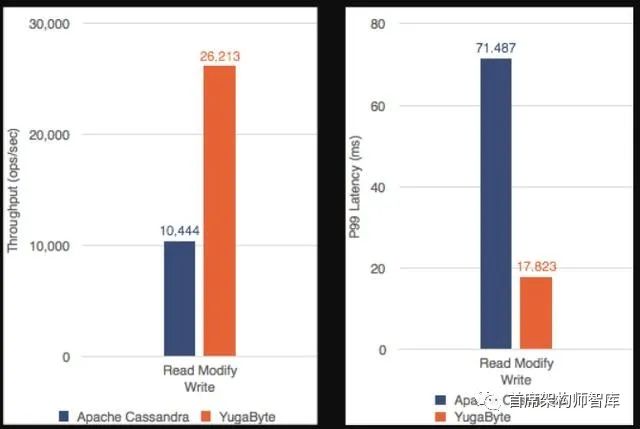
YCSB—读写吞吐量(越多越好)和P99延迟(越少越好)
原子的读-修改-写:为了实现原子性,读-修改-写操作可以作为一个轻量级事务(LWT)执行。在Apache Cassandra中,LWT从leader到副本总共需要4次往返,以准备、读取、提议和提交事务。许多往返会导致严重的延迟和LWT性能差,对用户应用程序产生负面影响。
在ygabyte DB中,因为quorum leader总是保存一致的并且是最新的数据副本,所以LWT只需要一次(1x)往返到副本来更新数据。这种更好的一致性设计使YugaByte执行LWT比Apache Cassandra更快。
3.压缩期间的可预测性能
Apache Cassandra中另一个导致速度变慢的主要原因是后台压缩。当运行主要的压缩时,用户经常抱怨他们的应用层有较高的前台延迟。
这是因为长时间运行或主要压缩会“饿死”较小但关键的压缩作业。这种饥饿会导致读取延迟的增加。完成较大的压缩之后,就可以运行较小的压缩,延迟也会降低。这使得延迟在应用程序端不可预测。高级技术用户通常会在非高峰时间在后台安排自己的压缩,但这既困难又不总是可能的。
在YugaByte DB中,我们将压缩分为主压缩和小压缩,并将它们安排在不同的队列中,并具有不同的优先级。这保证了较小的关键压缩具有一定的服务质量,将后台压缩对用户应用程序的影响降到最低。
4. 没有读取/反熵修复
在像Apache Cassandra这样最终一致的数据库中,任何副本中都可能存在不一致的数据。有两种处理方法。
读修复:一个读操作需要从所有副本读取以确定一致的结果。每当在任何副本中检测到不一致的数据时,该副本将需要立即进行前台读修复。
反熵维护:此外,最终一致的数据库还需要定期的后台反熵维护,对所有副本中的数据进行比较,并修复任何不一致的数据。
上面的操作开销很大,需要大量的CPU和网络带宽来将数据的副本发送给副本并进行比较。对于最终用户应用程序,这表现为更高的/不可预测的延迟,以及系统无法有效地支持更大的数据集。
在YugaByte DB的情况下,由于筏协议保证了强一致性,既不需要读修复,也不需要反熵维护。这将导致较低且可预测的p99延迟。我们使用Netflix数据存储基准(NDBench)进行了7天的基准测试,很高兴地看到p99的延迟低于6毫秒,甚至p995的延迟低于7毫秒。
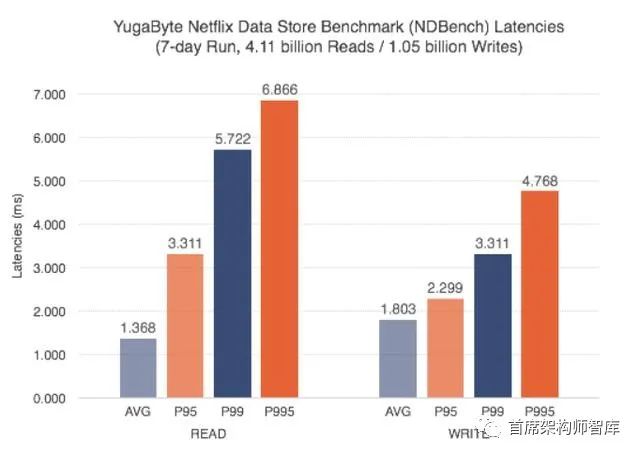
NDBench - YugaByte DB vs Cassandra Latency
5. 没有垃圾收集暂停
在基于java的NoSQL数据库(如Apache Cassandra)中,长时间的垃圾收集(GC)暂停是生产环境中的一个众所周知的问题。当垃圾收集器暂停应用程序、标记和移动正在使用的对象以及丢弃未使用的对象以回收内存时,就会发生这种情况。在一个长时间运行的数据库中,这种GC暂停通常会导致周期性的系统不可用和长响应时间(“长尾”问题)。虽然最先进的垃圾优先(Garbage First, G1) GC可以通过限制暂停时间在一定程度上缓解这个问题,但不幸的是,它是以降低吞吐量为代价的。最后,用户将不得不牺牲应用程序吞吐量或延迟。
因为YugaByte DB是用c++实现的,不需要垃圾收集,所以我们的用户可以毫无妥协地拥有最大的吞吐量和可预测的响应时间。
6. 利用更大的内存来获得更好的性能
除了GC调优,Java内存调优是Apache Cassandra用户面临的另一个典型挑战。它需要非常了解JVM堆大小应该是什么,哪些数据存储在堆外缓冲区中。而且,将更多内存分配给Java堆可能会损害性能,因为GC暂停时间更长。所有这些都增加了用户需要克服的操作复杂性。
另一方面,YugaByte DB可以在大内存机器上高效运行,有效利用可用内存,而不需要手动调整和调优。
总结
在这篇博客中,我们深入探讨了YugaByte DB如何通过更好的设计和实现来提供强大的一致性和卓越的性能。
本文:http://jiagoushi.pro/node/1140
讨论:请加入知识星球【首席架构师圈】或者小号【jiagoushi_pro】
| 微信公众号 | 【首席架构师智库】 适合物业仔细反复阅读。 精彩图文详解架构方法论,架构实践,技术原理,技术趋势。 我们在等你,赶快扫描关注吧。 |  |
| 微信小号 | 激烈深度讨论,报上你想加入的群:企业架构,云计算,大数据,数据科学,物联网,人工智能,安全,全栈开发,DevOps,数字化. 社群已经有5000人,赶快加入讨论。 |  |
| QQ群 | 深度交流企业架构,业务架构,应用架构,数据架构,技术架构,集成架构,安全架构。以及大数据,云计算,物联网,人工智能等各种新兴技术。 QQ大群,不用担心群满。 |
|
| 视频号 | 【首席架构师智库】 1分钟快速了解架构相关的基本概念,模型,方法,经验。 每天1分钟,架构心中熟。 |
|
| 知识星球 | 向大咖提问,近距离接触,或者获得私密资料分享。 | 知识星球【首席架构师圈】 |
| 微信圈子 | 志趣相投的同好交流。 | 微信圈子【首席架构师圈】 |
| 喜马拉雅 | 路上或者车上了解最新黑科技资讯,架构心得。 | 【智能时刻,架构君和你聊黑科技】 |
| 知识星球 | 认识更多朋友,职场和技术闲聊。 | 知识星球【职场和技术】 |


