





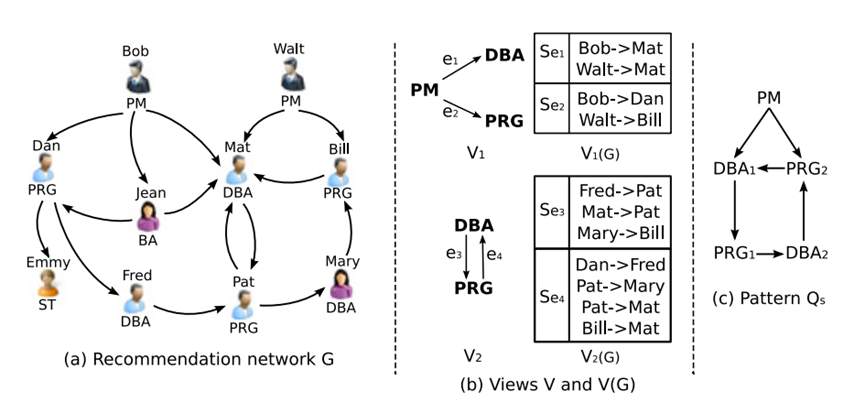
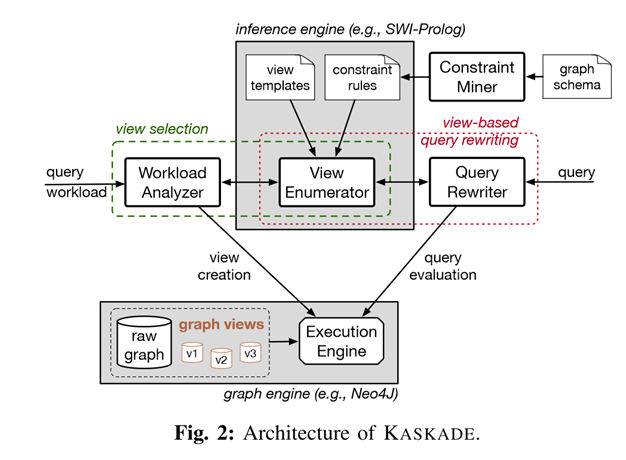
 。在此候选集的基础上在进行图模拟构建,从而回答了查询。
。在此候选集的基础上在进行图模拟构建,从而回答了查询。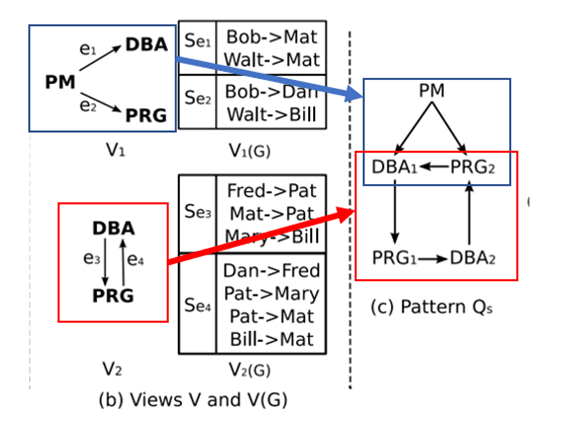
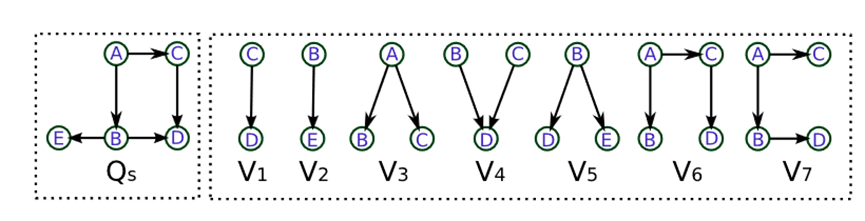
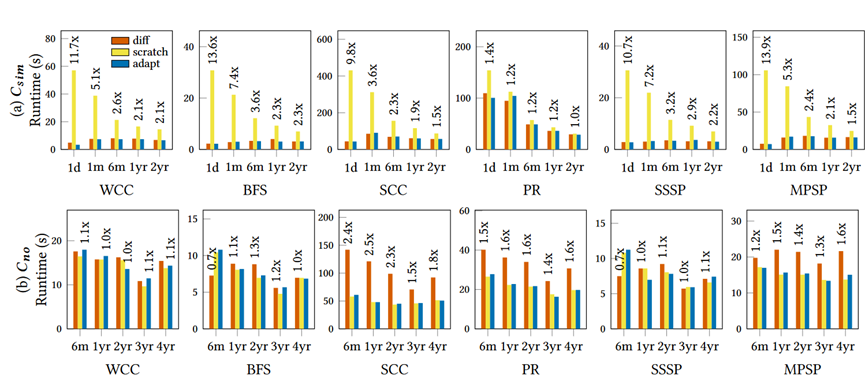
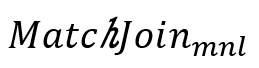 是使用极小覆盖的覆盖方法进行视图加速,而
是使用极小覆盖的覆盖方法进行视图加速,而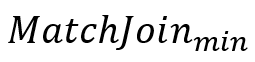 是使用最小覆盖的覆盖方法进行视图加速。可以看出视图能够起到加速的效果。
是使用最小覆盖的覆盖方法进行视图加速。可以看出视图能够起到加速的效果。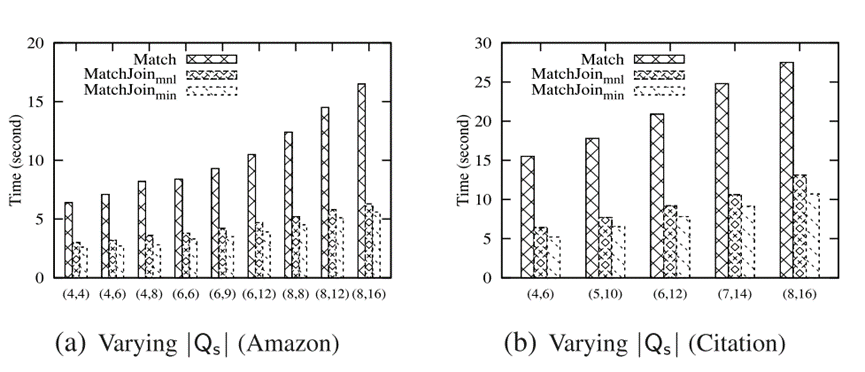

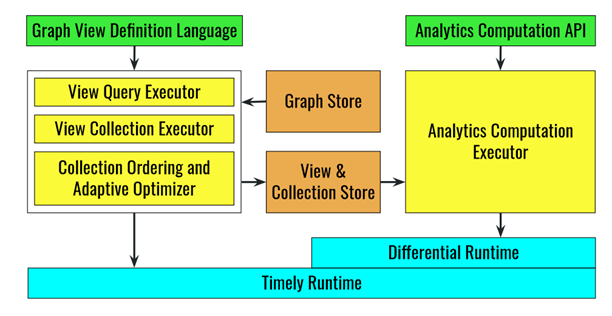
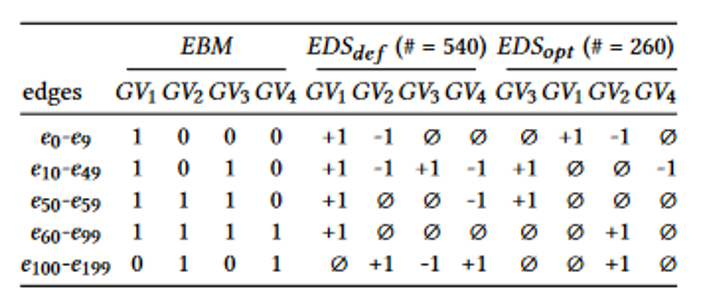
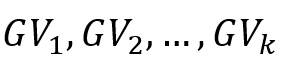 ,Graphsurge会存储为
,Graphsurge会存储为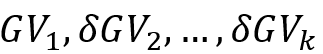 的形式。
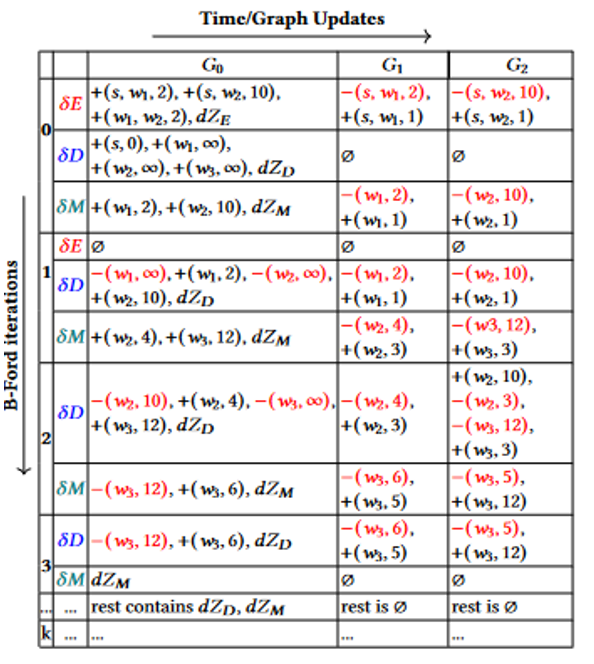
的形式。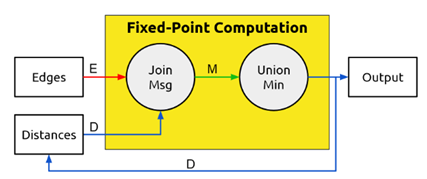





欢迎关注北京大学王选计算机研究所数据管理实验室微信公众号“图谱学苑“
实验室官网:https://mod.wict.pku.edu.cn/
微信社区群:请回复“社区”获取
gStore官网:http://www.gstore.cn/
GitHub:https://github.com/pkumod/gStore
Gitee:https://gitee.com/PKUMOD/gStore

文章转载自图谱学苑,如果涉嫌侵权,请发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
