




我们在上一章讲解了常用的3种基础排序算法,本章我们接着讲解2种经典的深度学习排序算法,即Google的wide & deep和YouTube的深度学习排序。这2个算法是国外大厂在真实业务场景中得到验证的、有真实业务价值的方法,并且也被中国广大互联网公司应用于自己的业务中,是得到业界一致认可的算法。
13.1 wide & deep排序算法
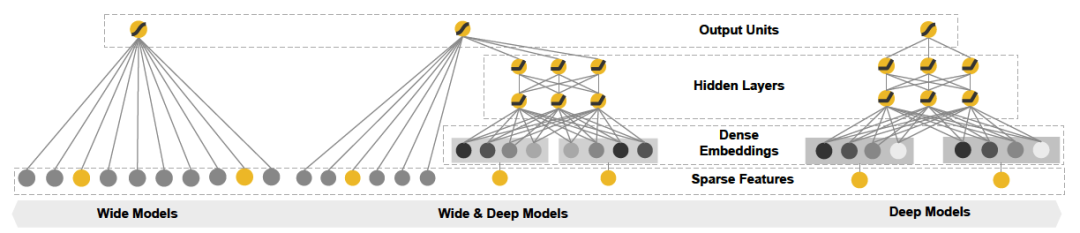
12.3.1 模型特性分析
12.3.2 模型架构
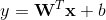 ,y是最终的预测值,这里
,y是最终的预测值,这里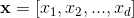 是d个特征,
是d个特征,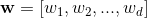 是模型参数,b是bias。这里的特征
是模型参数,b是bias。这里的特征 包含两类特征:
包含两类特征: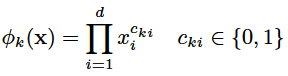
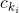 是布尔型变量,如果第 i 个特征
是布尔型变量,如果第 i 个特征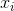 是第 k 个变换
是第 k 个变换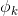 的一部分,那么=1,否则为0。对于交叉积And(gender=female, language=en),只有当它的成分特征都为1时(即gender=femal并且language=en时),
的一部分,那么=1,否则为0。对于交叉积And(gender=female, language=en),只有当它的成分特征都为1时(即gender=femal并且language=en时),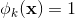 ,否则
,否则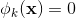 。
。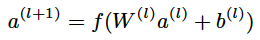
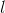 是层数,f 是激活函数(该模型采用了ReLU激活函数),
是层数,f 是激活函数(该模型采用了ReLU激活函数),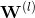 、
、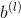 是模型需要学习的参数。
是模型需要学习的参数。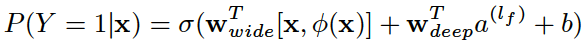
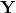 是最终的二元分类变量,
是最终的二元分类变量,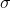 是sigmoid函数,
是sigmoid函数,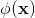 是前面提到的交叉积特征,
是前面提到的交叉积特征,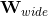 和
和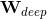 分别是wide模型的权重和deep模型中对应于最后激活
分别是wide模型的权重和deep模型中对应于最后激活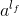 (最后一个隐藏层进行激活函数变换后的向量)的权重。
(最后一个隐藏层进行激活函数变换后的向量)的权重。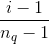 来作为该变量的归一化值,这里
来作为该变量的归一化值,这里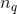 是分位点的个数),数值特征和类别特征拼接起来形成大约1200维的向量再灌入deep模型,而wide模型是APP安装和APP曝光(impression)两类特征通过交叉积变换形成模型需要的特征。最后通过反向传播算法来训练该模型(wide模型采用FTRL优化器,deep模型采用AdaGrad优化器),并上线到APP推荐业务中做AB测试。
是分位点的个数),数值特征和类别特征拼接起来形成大约1200维的向量再灌入deep模型,而wide模型是APP安装和APP曝光(impression)两类特征通过交叉积变换形成模型需要的特征。最后通过反向传播算法来训练该模型(wide模型采用FTRL优化器,deep模型采用AdaGrad优化器),并上线到APP推荐业务中做AB测试。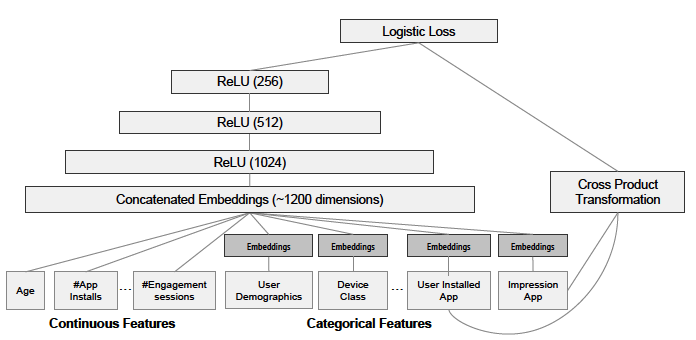
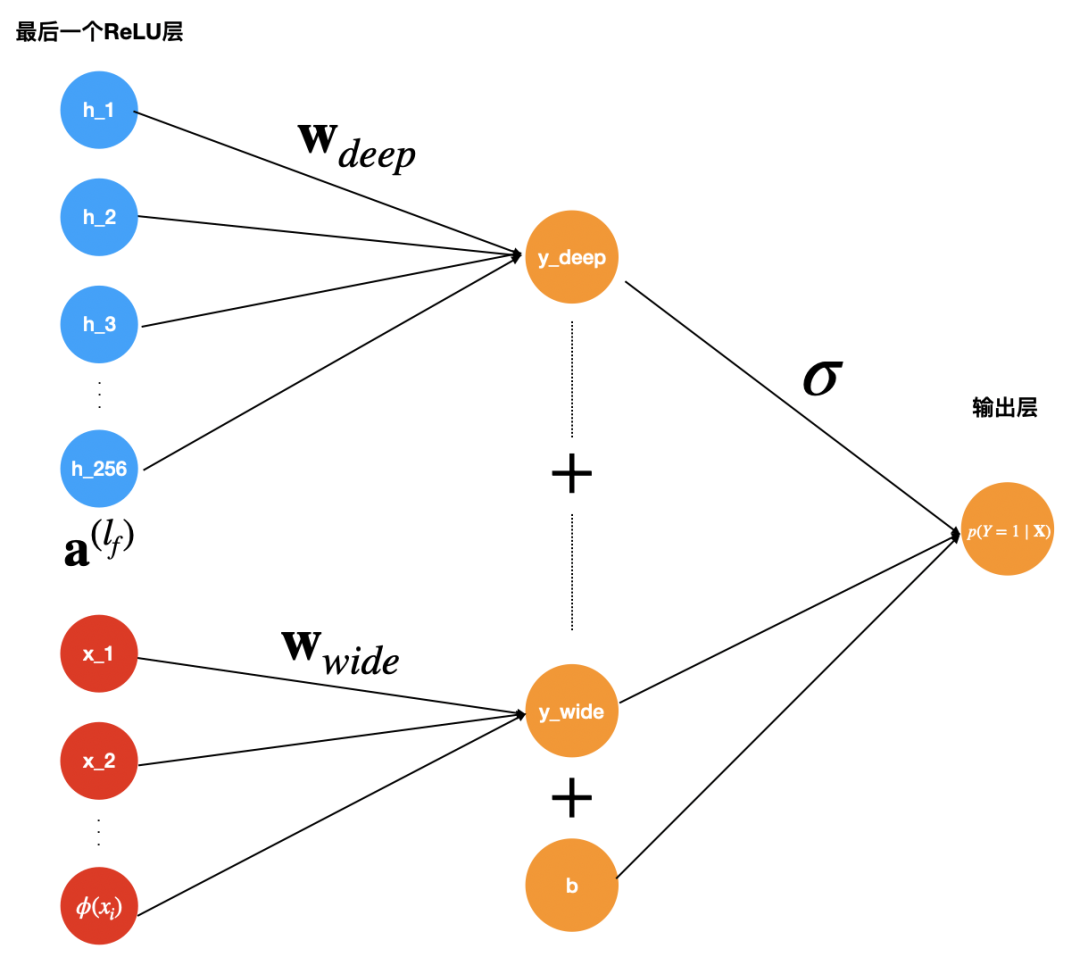
12.3.3 wide & deep的工程实现
13.2 YouTube深度学习排序算法
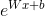 进行预测,可以很好地匹配视频的播放时长这个业务指标。下面来对该模型的架构和特性进行说明。
进行预测,可以很好地匹配视频的播放时长这个业务指标。下面来对该模型的架构和特性进行说明。13.2.1 模型架构
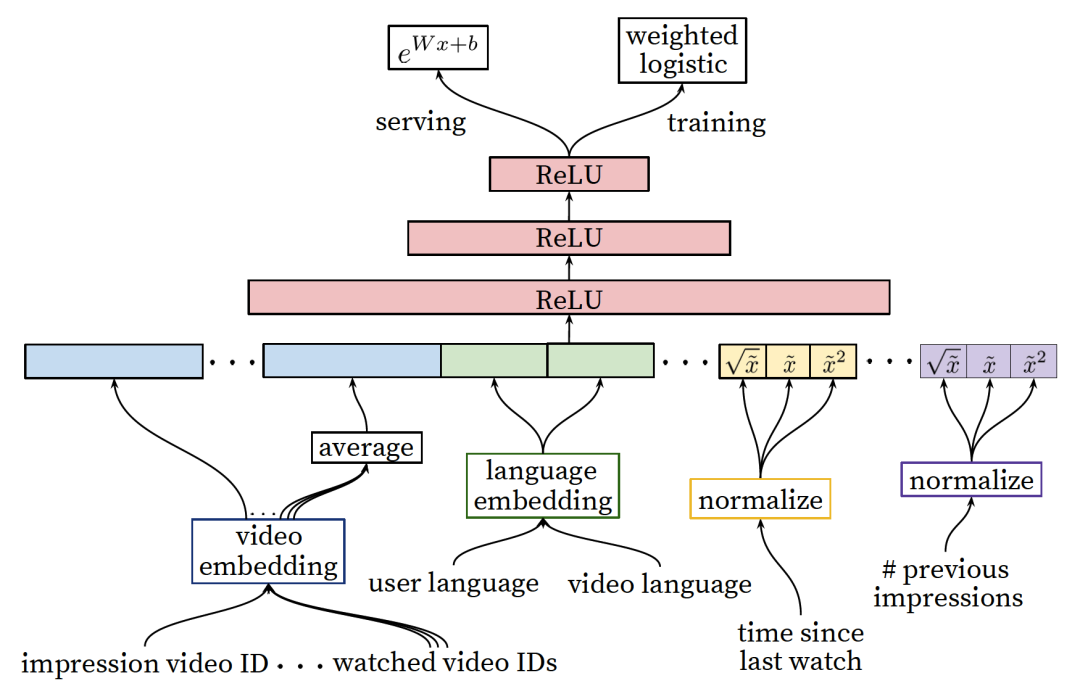 。这里的参数
。这里的参数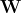 是图4中最后一层隐藏层到输出层的权重矩阵,
是图4中最后一层隐藏层到输出层的权重矩阵,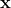 是最后一个隐藏层激活后的向量,b是bias,参见下面图5,可以更好地理解。
是最后一个隐藏层激活后的向量,b是bias,参见下面图5,可以更好地理解。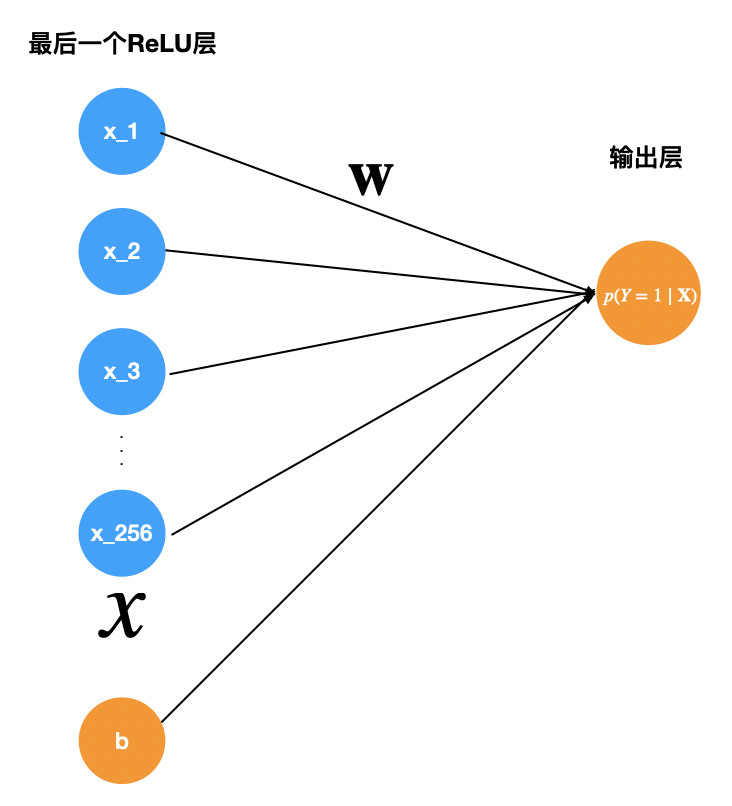 中的参数的解释说明
中的参数的解释说明13.2.2 加权logistics回归解释

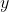 是真实的概率值,
是真实的概率值,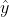 是预测的概率值。对于正样本来说,
是预测的概率值。对于正样本来说,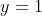 ,
, 。对于负样本来说
。对于负样本来说 ,
,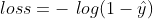 。不管样本是正负,是模型预测出来的,
。不管样本是正负,是模型预测出来的,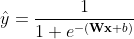 。
。 来进行加权,那么上面的损失函数就是
来进行加权,那么上面的损失函数就是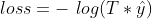 ,越大,损失越小,说明越“奖励”这样的正样本。由于负样本的加权参数为1,损失不变,还是。
,越大,损失越小,说明越“奖励”这样的正样本。由于负样本的加权参数为1,损失不变,还是。13.2.3 预测播放时长
来预测。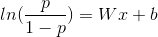
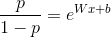
 加权,odds可以计算为
加权,odds可以计算为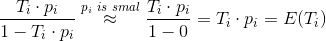
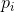 很小,相对于1可以忽略不计。上式计算的结果正好是视频的期望播放时长。因此,通过加权logistic回归来训练模型,并通过来预测,刚好预测的正是视频的期望观看时长,预测的目标跟建模的期望保持一致,这是该模型非常巧妙的地方。
很小,相对于1可以忽略不计。上式计算的结果正好是视频的期望播放时长。因此,通过加权logistic回归来训练模型,并通过来预测,刚好预测的正是视频的期望观看时长,预测的目标跟建模的期望保持一致,这是该模型非常巧妙的地方。总结
来预测视频的播放时长,完美地解决了模型与业务目标(希望用户观看更长的时间)的一致性。参考文献

文章转载自数据与智能,如果涉嫌侵权,请发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
