




项目背景
Alibaba Otter 是一个开源的数据库同步系统,可以用于 MySQL 之间的双向数据同步。Alibaba Otter 是 Alibaba Canal 的父项目,在 Alibaba Otter 中,Alibaba Canal 会作为一个依赖项以内嵌服务的形式运行,完成读取增量数据的工作。
Alibaba Otter 主要由 manager 和 node 两部分组成,其中 manager 是一个 web 管理平台,用于管理集群和任务,node 是实际处理数据的工作节点,也就是在 node 里集成了 canal。manager 和 node 分开部署和启动,两者之间通过 dubbo rpc 进行通信。
当前,OceanBase 基于 Alibaba Canal 1.1.6 开发了可用于获取 OceanBase 增量数据的功能,该分支同样可用于 Alibaba Otter。
应用场景
Alibaba Otter 可用于 OceanBase/MySQL 之间的单向同步和双向同步,其中的双向同步既包含数据无交叉的一般双向同步,又包含可能出现修改同一条数据的情况的双A同步。详情参考文档:Manager 配置介绍。
部署框架如下:
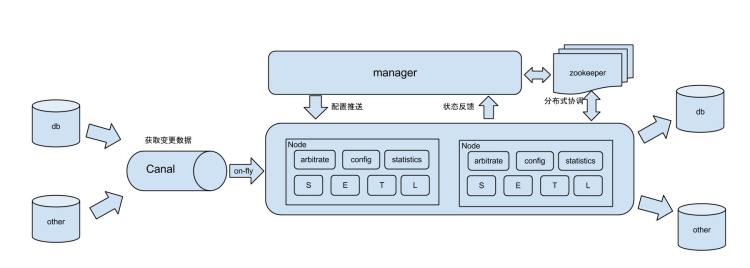
部署的详细步骤,请参考 Otter 双向同步。
特性介绍
机器负载
部署服务时需要考虑机器负载,避免影响业务服务的稳定性。其中 oceanbase 和 oblogproxy 均会使用大量内存,因此不建议部署在同一台机器上。
高可用
Otter 基于 zookeeper 分别实现了 manager 和 node 的高可用部署,详情参考文档:Otter 高可用性。
负载均衡
数据在 node 中会经过 SETL 四个阶段,当数据经过上一个阶段流入下一个阶段时,将通过负载均衡算法确定下一阶段将在哪个 node 上执行。目前 Otter 提供了 3 种负载均衡策略:轮询(Round Robin)、随机(Random)和固定(Stick)。
实际生产环境中,若使用轮询和随机策略,当数据经过上一个阶段流入下一个阶段时,可能会跳到新的 node 上,该过程中涉及到 node 和 manager 的 rpc 通信,以及 manager 与 zookeeper 的通信,可能会增加处理流程的时延。因此对于追求效率的用户来说,可以选择 Stick 模式。
白名单
node 中 内嵌的 canal 服务在启动 pipeline 时才被真正创建和启动,canal 所监听的表范围是由租户和 pipeline 中的表映射关系共同组成的。由于一个 canal 只能用于一个 channel,因此应当为不同的 channel 配置不同的 canal 对象,即便他们使用了同一套 oceanbase 和 oblogproxy。
