





MySQL内存分配与管理总体上分为上中下三篇介绍,上篇中主要介绍了 InnoDB 层和 SQL 层内存分配管理器,其中InnoDB的内存分配主要依靠ut_allocator和mem_heap_allocator完成。本篇为中篇,主要介绍InnoDB的内存构成和使用,代码版本主要基于8.0.25。
InnoDB 是 MySQL 默认的存储引擎,而提到InnoDB的内存,就绕不开Buffer Pool,该结构对性能的影响重大。但事实上InnoDB的内存消耗并不只有BP而已,其内部还有许多重要的结构(如AHI、Change Buffer、Log buffer等)也占据着不可忽视的内存空间。了解InnoDB的内存结构和使用特点对于MySQL运行期间的内存选型和使用有很大帮助。
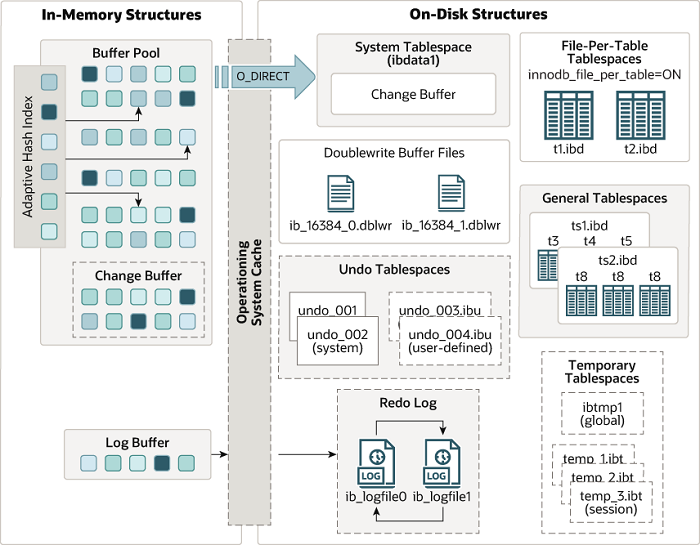
图源:https://dev.mysql.com/doc/refman/8.0/en/innodb-architecture.html
1.Buffer Pool
1.1 数据结构
struct buf_pool_t {...ulint instance_no; // 缓冲池实例编号ulint curr_pool_size; // 缓冲池实例大小buf_chunk_t *chunks; // 缓冲池实例的物理块列表hash_table_t *page_hash; // 页哈希表hash_table_t *zip_hash; // 伙伴系统分配frame对应的block哈希表UT_LIST_BASE_NODE_T(buf_page_t) free; // 空闲链表UT_LIST_BASE_NODE_T(buf_page_t) LRU; // LRU 链表UT_LIST_BASE_NODE_T(buf_page_t) flush_list; // flush 链表UT_LIST_BASE_NODE_T(buf_buddy_free_t) zip_free[BUF_BUDDY_SIZES_MAX]; //伙伴分配系统空闲链表BufListMutex free_list_mutex; // 空闲链表的互斥锁BufListMutex LRU_list_mutex; // LRU 链表的互斥锁BufListMutex flush_state_mutex; // flush 链表的互斥锁BufListMutex zip_free_mutex; // 伙伴分配互斥锁BufListMutex zip_hash_mutex;BufListMutex chunks_mutex; // chunk mutex链表...}
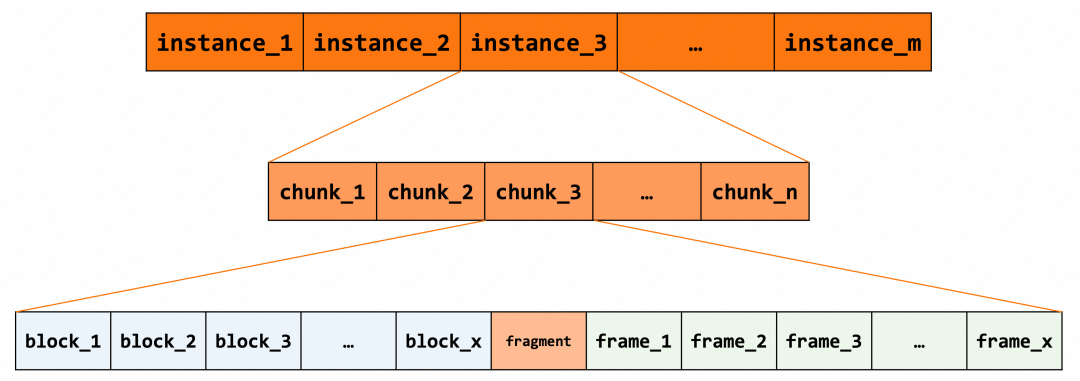
chunk 是物理内存分配的基本单位,instance 由一块一块的 chunk 组成。每个 chunk 被切分成 block 串和 frame 串,block 串在前,frame 串在后,两者之间可能存在不圆整的内存碎片。其中 block 为控制块,包含了页面的控制信息;frame 存储了实际的数据,由 bytes 组成。
struct buf_chunk_t {ulint size; /*!< frames[]/blocks[]的数量 */unsigned char *mem; /*!< frame内存区域指针 */ut_new_pfx_t mem_pfx; /*!< 监控信息 */buf_block_t *blocks; /*!< 控制块数组 */uint32_t chunk_no; /*! chunk号 */UT_LIST_BASE_NODE_T(buf_page_t) chunk_page_list; /*!< chunk list根结点 */...};
struct buf_block_t {buf_page_t page; // 放在第一个位置,以便于block和page进行强制转换BPageLock lock; // frame的读写锁byte *frame; // 实际数据...BPageMutex mutex; // block锁:state、io_fix、buf_fix_count、accessed};
struct buf_page_t {...page_id_t id; // page idpage_size_t size; // page 大小ib_uint32_t buf_fix_count; // 用于并发控制buf_io_fix io_fix; // 用于并发控制buf_page_state state; // 页状态lsn_t newest_modification; // 最新 lsn,即最近修改的 lsnlsn_t oldest_modification; // 最老 lsn,即第一条修改 lsn...}
1.2 初始化过程
BP初始化的过程和上述的各个层级的数据结构紧密相关。初始化的主线过程大致步骤可分为:BP初始化---BP isntance初始化---chunk 初始化---block初始化;此外AHI、page_hash等结构的初始化也会在此过程中完成。
// 1. 构建BP instance指针数组buf_pool_ptr =(buf_pool_t *)ut_zalloc_nokey(n_instances * sizeof *buf_pool_ptr);// 2. 多线程并发初始化BP instancefor (ulint id = i; id < n; ++id) {threads.emplace_back(std::thread(buf_pool_create, &buf_pool_ptr[id], size,id, &m, std::ref(errs[id]))); }// 3. AHI的初始化btr_search_sys_create(buf_pool_get_curr_size() sizeof(void *) 64);
buf_pool_create() 函数负责构建每个BP instance,主要做了几件事:
7.初始化 flush 相关数据,如 Hp 指针、链表包含关系等。
static void buf_pool_create(buf_pool_t *buf_pool, ulint buf_pool_size,ulint instance_no, std::mutex *mutex,dberr_t &err) {...// 1. 构建锁信息mutex_create(LATCH_ID_BUF_POOL_CHUNKS, &buf_pool->chunks_mutex);mutex_create(LATCH_ID_BUF_POOL_LRU_LIST, &buf_pool->LRU_list_mutex);...// 2. 计算chunks数量buf_pool->n_chunks = buf_pool_size srv_buf_pool_chunk_unit;chunk_size = srv_buf_pool_chunk_unit;buf_pool->chunks = reinterpret_cast<buf_chunk_t *>(ut_zalloc_nokey(buf_pool->n_chunks * sizeof(*chunk)));...// 3. 初始化各链表UT_LIST_INIT(buf_pool->LRU, &buf_page_t::LRU);UT_LIST_INIT(buf_pool->free, &buf_page_t::list)UT_LIST_INIT(buf_pool->flush_list, &buf_page_t::list);...// 4. 初始化chunkdo {if (!buf_chunk_init(buf_pool, chunk, chunk_size, mutex)) {...} while (++chunk < buf_pool->chunks + buf_pool->n_chunks);...// 5. 设置instance参数buf_pool->instance_no = instance_no;buf_pool->curr_pool_size = buf_pool->curr_size * UNIV_PAGE_SIZE;...// 6. 构建page_hash和lockssrv_n_page_hash_locks =static_cast<ulong>(ut_2_power_up(srv_n_page_hash_locks));buf_pool->page_hash =ib_create(2 * buf_pool->curr_size, LATCH_ID_HASH_TABLE_RW_LOCK,srv_n_page_hash_locks, MEM_HEAP_FOR_PAGE_HASH);buf_pool->zip_hash = hash_create(2 * buf_pool->curr_size);...// 7. 初始化flush相关信息,如Hp指针等for (i = BUF_FLUSH_LRU; i < BUF_FLUSH_N_TYPES; i++) {buf_pool->no_flush[i] = os_event_create();}...new (&buf_pool->flush_hp) FlushHp(buf_pool, &buf_pool->flush_list_mutex);...}
static buf_chunk_t *buf_chunk_init(...){// 1. ut_allocator + large方式申请内存...if (!buf_pool->allocate_chunk(mem_size, chunk)) {return (nullptr);}...// 2. 切分block和framechunk->blocks = (buf_block_t *)chunk->mem;frame = (byte *)ut_align(chunk->mem, UNIV_PAGE_SIZE);chunk->size = chunk->mem_pfx.m_size UNIV_PAGE_SIZE - (frame != chunk->mem);{ulint size = chunk->size;while (frame < (byte *)(chunk->blocks + size)) {frame += UNIV_PAGE_SIZE;size--;}chunk->size = size;}...// 3. 初始化页控制体blockfor () {buf_block_init(buf_pool, block, frame, chunk, sync_init_nolock);UT_LIST_ADD_LAST(buf_pool->free, &block->page);}// 4. 注册chunkbuf_pool_register_chunk(chunk);...}
buf_pool->page_hash =ib_create(2 * buf_pool->curr_size, LATCH_ID_HASH_TABLE_RW_LOCK,srv_n_page_hash_locks, MEM_HEAP_FOR_PAGE_HASH);buf_pool->page_hash_old = nullptr;buf_pool->zip_hash = hash_create(2 * buf_pool->curr_size);
1.3 页面管理链表
BP 中的每个链表都是双向链表,节点类型都是 buf_block_t ,基节点中保存了首尾节点信息和链表长度等,大致结构如下图所示。
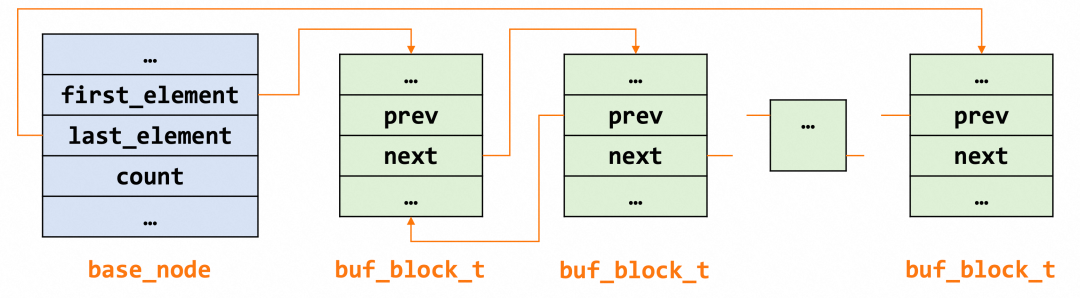
Buffer Pool 中的页面使用情况如下图所示。其中每个小方格可视为一个页,free 表示空闲页,即该页面对应的数据为空,随时可以填入新的数据;clean 表示干净页,即该页面存在数据,且该数据未被更新;dirty 表示脏页,即该页面存在数据已被更新。各个类型的页同时存在于 BP 中,它们被各个链表串起来,协同管理。
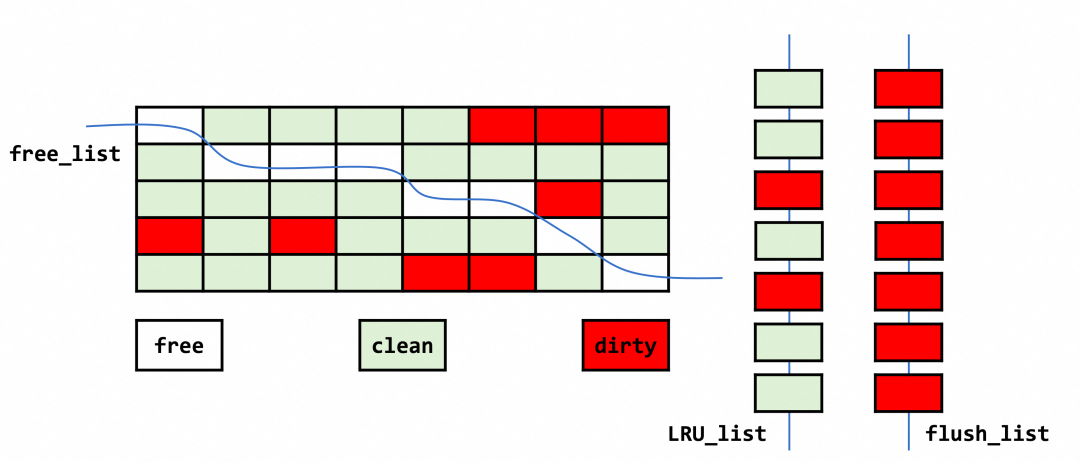
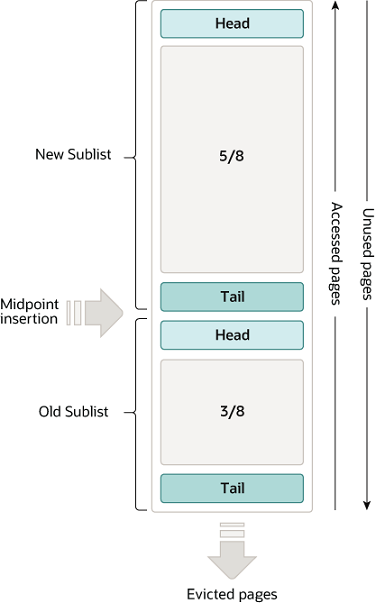
LRU优化
LRU 分为了 Old Sublist 和 New Sublist 两段,加载数据首先会加载到 Old 位置,只有当满足一定的条件时,数据才会从 Old 段转移到 New 段。当发生类似全表扫描的操作时,LRU 的淘汰就不会影响到真正的热点数据,从而保证缓存的热度。
响应时间优化
如果后续的访问时间与第一次访问的时间小于 innodb_old_blocks_time,则不将该缓存页从 Old 区域移动到 New 区域。
如果后续的访问时间与第一次访问的时间大于 innodb_old_blocks_time,则将该缓存页从 Old 区域移动到 New 区域的头部。
缓冲池中所有脏页都会挂载在 flush list 中,以等待数据落盘。在数据更改被刷入磁盘前,数据很有可能会被修改多次。数据页控制体中记录了最新修改的 lsn(newset_modification) 和最早修改的 lsn(oldest_modification)。最新加入的数据页放在链表头部,刷数据时从链表尾开始,即优先刷新最早加入的页节点。
该结构是由 5 个链表构成的二维数组,分别是 1K、2K、4K、8K 和 16K 的碎片链表,存储从磁盘读入的压缩页,引擎使用伙伴系统来管理该结构。
2. Change Buffer
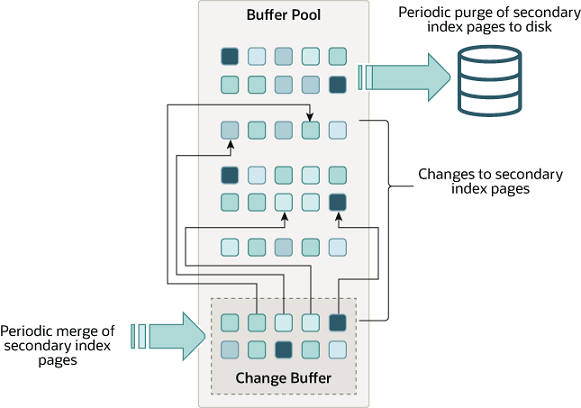
图源:https://dev.mysql.com/doc/refman/8.0/en/innodb-change-buffer.html
1.相关互斥量的构建;
2.ibuf参数的初始化,包括max_size、index等相关的数据;
void ibuf_init_at_db_start(void) {...// 1.互斥量操作mutex_create(LATCH_ID_IBUF, &ibuf_mutex);...// 2.构建root{buf_block_t *block;// IBUF_SPACE_ID = 0, FSP_IBUF_TREE_ROOT_PAGE_NO = 4block = buf_page_get(page_id_t(IBUF_SPACE_ID, FSP_IBUF_TREE_ROOT_PAGE_NO),univ_page_size, RW_X_LATCH, &mtr);buf_block_dbg_add_level(block, SYNC_IBUF_TREE_NODE);// 对应的frame作为Change Buffer B+树的rootroot = buf_block_get_frame(block);}...// 3. 参数设置// CHANGE_BUFFER_DEFAULT_SIZE默认是25ibuf->max_size = ((buf_pool_get_curr_size() UNIV_PAGE_SIZE) *CHANGE_BUFFER_DEFAULT_SIZE)100;ibuf->index =dict_mem_index_create("innodb_change_buffer", "CLUST_IND", IBUF_SPACE_ID,DICT_CLUSTERED | DICT_IBUF, 1);ibuf->index->id = DICT_IBUF_ID_MIN + IBUF_SPACE_ID;ibuf->index->table = dict_mem_table_create("innodb_change_buffer",IBUF_SPACE_ID, 1, 0, 0, 0, 0);...}
3.视情况进行 merge。
static MY_ATTRIBUTE((warn_unused_result)) dberr_tibuf_insert_low(ulint mode, ibuf_op_t op, ibool no_counter,const dtuple_t *entry, ulint entry_size,dict_index_t *index, const page_id_t &page_id,const page_size_t &page_size, que_thr_t *thr) {...// 1. 构建entryibuf_entry = ibuf_entry_build(op, index, entry, page_id.space(), page_id.page_no(),no_counter ? ULINT_UNDEFINED : 0xFFFF, heap);...// 初始化游标btr_pcur_open(ibuf->index, ibuf_entry, PAGE_CUR_LE, mode, &pcur, &mtr);...// 2. 插入操作err = btr_cur_optimistic_insert(...);// 也可能是btr_cur_pessimistic_insertblock = btr_cur_get_block(cursor);...// pcur收尾工作,包括rec、block的清空等btr_pcur_close(&pcur);// 3. 视情况进行merge}
Change Buffer 本身没有很多额外的内存申请,依赖 Buffer Pool 中的 block 进行操作。大部分都是申请一些临时的 mem_heap_t,使用完毕后立即释放,不会在内存中长时间驻留。
3. AHI
InnoDB 的索引组织结构为 btree,当查询的时候会根据条件一直索引到叶子节点。为了减少开销,InnoDB 中引入了自适应哈希索引(Adaptive Hash Index,后文简称AHI)对索引的前缀建立了一个哈希表,用来加速查询。AHI 是为那些频繁被访问的索引页而建立的,可以理解为 btree 上的索引,其中包含了多个 hash_table。初始创建的数组大小为 buf_pool_get_curr_size() sizeof(void *) 64,使用 malloc 分配。数组大小最终对应了 hash_table 中 cell(bucket)的总数,这个数量实际上还要进行一个质数化的处理。
3.1 数据结构
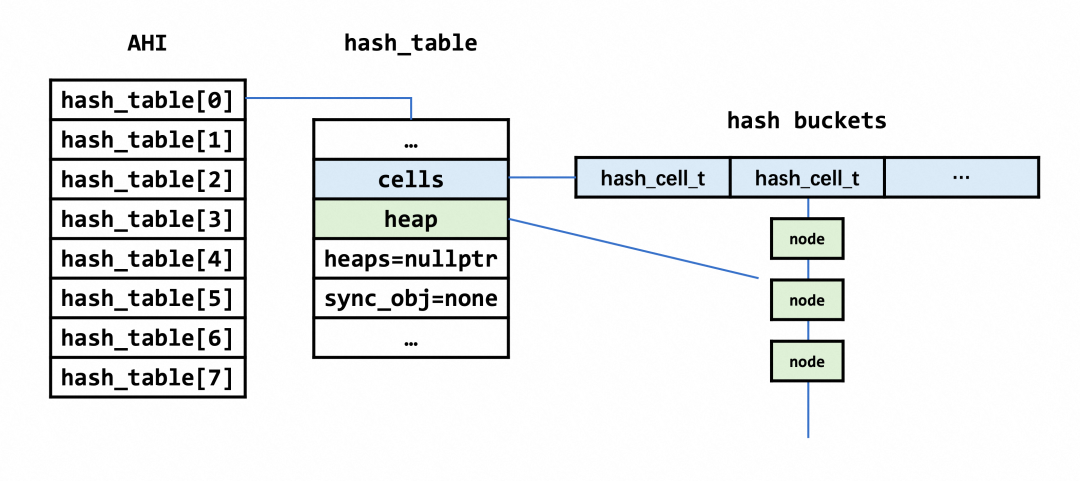
struct hash_cell_t {void *node; /*!< 哈希链 */};/* The hash table structure */struct hash_table_t {enum hash_table_sync_t type; /*!< MUTEX/RW_LOCK/NONE. */ibool adaptive;ulint n_cells; /* 哈希桶数量 */hash_cell_t *cells; /*!< bucket数组 */ulint n_sync_obj; /* 互斥量、锁的数量 */union {ib_mutex_t *mutexes;rw_lock_t *rw_locks;} sync_obj;mem_heap_t **heaps; // 多个part时,用于分配哈希链的内存数组,个数和n_sync_obj相关,如在page_hash中用到mem_heap_t *heap; // 分配哈希链的内存堆};
3.2 内存初始化
在AHI构建的时候,分成了 8 个 part,每个 part 负责不同的 bucket ,拥有各自部分的锁。构建和初始化主要分为以下几个步骤:
2.hash_table 的初始化,底层调用 ib_create(),注意这里传入的 type 是 MEM_HEAP_FOR_BTR_SEARCH,这直接决定了 hash_table 中 heap 的类型,即内存的来源。
void btr_search_sys_create(ulint hash_size) {/* Step-1: Allocate latches (1 per part). */btr_search_latches = reinterpret_cast<rw_lock_t **>(ut_malloc(sizeof(rw_lock_t *) * btr_ahi_parts, mem_key_ahi));for (ulint i = 0; i < btr_ahi_parts; ++i) {btr_search_latches[i] = reinterpret_cast<rw_lock_t *>(ut_malloc(sizeof(rw_lock_t), mem_key_ahi));rw_lock_create(btr_search_latch_key, btr_search_latches[i],SYNC_SEARCH_SYS);}/* Step-2: Allocate hash tablees. */btr_search_sys = reinterpret_cast<btr_search_sys_t *>(ut_malloc(sizeof(btr_search_sys_t), mem_key_ahi));btr_search_sys->hash_tables = reinterpret_cast<hash_table_t **>(ut_malloc(sizeof(hash_table_t *) * btr_ahi_parts, mem_key_ahi));for (ulint i = 0; i < btr_ahi_parts; ++i) { // 循环调用ib_create()btr_search_sys->hash_tables[i] =ib_create((hash_size / btr_ahi_parts), LATCH_ID_HASH_TABLE_MUTEX, 0,MEM_HEAP_FOR_BTR_SEARCH);...}
进一步地,ib_create中主要做两件事:
调用 hash_create() 创建 hash_table
初始化table->heap
4. 其他
4.1 Log Buffer
// 内存申请static void log_allocate_buffer(log_t &log) {...log.buf.create(srv_log_buffer_size);}// 内存释放static void log_deallocate_buffer(log_t &log) { log.buf.destroy(); }
4.2 table cache
int ha_innobase::open(const char *name, int, uint open_flags,const dd::Table *table_def) {...// session级缓存ib_table = thd_to_innodb_session(thd)->lookup_table_handler(norm_name);...// 全局dict_sys级缓存ib_table = dict_table_check_if_in_cache_low(norm_name);...// 缓存中不存在,直接开表ib_table = dd_open_table(client, table, norm_name, table_def, thd);...// m_prebuilt结构构建m_prebuilt = row_create_prebuilt(ib_table, table->s->reclength);...}
1. session_table_cache
class innodb_session_t {table_cache_t m_open_tables;...};
2. dict_sys->table_hash
void dict_init(void) {...dict_sys->table_hash = hash_create(buf_pool_get_curr_size() / (DICT_POOL_PER_TABLE_HASH * UNIV_WORD_SIZE));dict_sys->table_id_hash = hash_create(buf_pool_get_curr_size() / (DICT_POOL_PER_TABLE_HASH * UNIV_WORD_SIZE));...}
3. dd_open_table()
dd_open_table|->dd_open_table_one| |->dd_fill_dict_table //create dict_table_t| |->dict_mem_table_create // create| {| // dict_table_t和内部的col、locks等内存都从这个heap上面分配,DICT_HEAP_SIZE=100| heap = mem_heap_create(DICT_HEAP_SIZE);| ...| table = static_cast<dict_table_t *>(mem_heap_zalloc(heap, sizeof(*table)));| ...| table->heap = heap;| table->cols = static_cast<dict_col_t *>(| mem_heap_alloc(heap, table->n_cols * sizeof(dict_col_t)));| table->v_cols = static_cast<dict_v_col_t *>(| mem_heap_alloc(heap, n_v_cols * sizeof(*table->v_cols)));| table->autoinc_lock =| static_cast<ib_lock_t *>(mem_heap_alloc(heap, lock_get_size()));| ...| }|->dict_table_add_to_cache(m_table, TRUE, heap); // 添加到缓存
Server 层中的总的 table cache 和打开表数量、字段长度都有关系,每个 table cache 占据的内存从几十k ~ 几百k不等。
4.3 lock_sys_t
void lock_sys_create(ulint n_cells){...lock_sys->rec_hash = hash_create(n_cells);lock_sys->prdt_hash = hash_create(n_cells);lock_sys->prdt_page_hash = hash_create(n_cells);...}void lock_sys_close(void) {...hash_table_free(lock_sys->rec_hash);hash_table_free(lock_sys->prdt_hash);hash_table_free(lock_sys->prdt_page_hash);...}
主要的内存消耗都是在 3 个 hash_table 的构造上,并且是直接调用 hash_create() 进行“裸”构造,没有涉及 heap/heaps 的初始化,所有的内存都是通过 malloc 的方式去构造。各个 hash_table 的需要的内存大小和 srv_lock_table_size 相关,其值在 InnoDB 启动时被指定:srv_lock_table_size = 5 * (srv_buf_pool_size / UNIV_PAGE_SIZE)。
4.4 os_event_t
大多数锁、互斥量的构建和初始化最终都会落到 os_event_t 的构造,但是零散的、临时的 mutex 并不会造成很大的内存压力。前文提到的在 buf_block_t 的初始化中就有大量 mutex 和 rw_lock 的初始化,其生命周期和 BP 相当,数量和 buf_block_t 相等,因此会占据很大一部分内存空间。
buf_block_init:
/** Initializes a buffer control block when the buf_pool is created. */static void buf_block_init(buf_pool_t *buf_pool, /*!< in: buffer pool instance */buf_block_t *block, /*!< in: pointer to control block */byte *frame, /*!< in: pointer to buffer frame */buf_chunk_t *chunk, /*!< in: pointer to chunk */bool sync_init_nolock){...mutex_create(LATCH_ID_BUF_BLOCK_MUTEX, &block->mutex); // mutex构建...rw_lock_create(PFS_NOT_INSTRUMENTED, &block->lock, SYNC_LEVEL_VARYING); // rw_lock构建...}
mutex_create
mutex_create()|->mutex_init()|->TTASEventMutex::init()|->os_event_create() // 构建os_event_t
rw_lock_create
rw_lock_create()|->pfs_rw_lock_create_func()|->rw_lock_create_func()|->os_event_create() // 构建os_event_t
os_event_t os_event_create() {os_event_t ret = (UT_NEW_NOKEY(os_event()));return ret;}
5. 总结
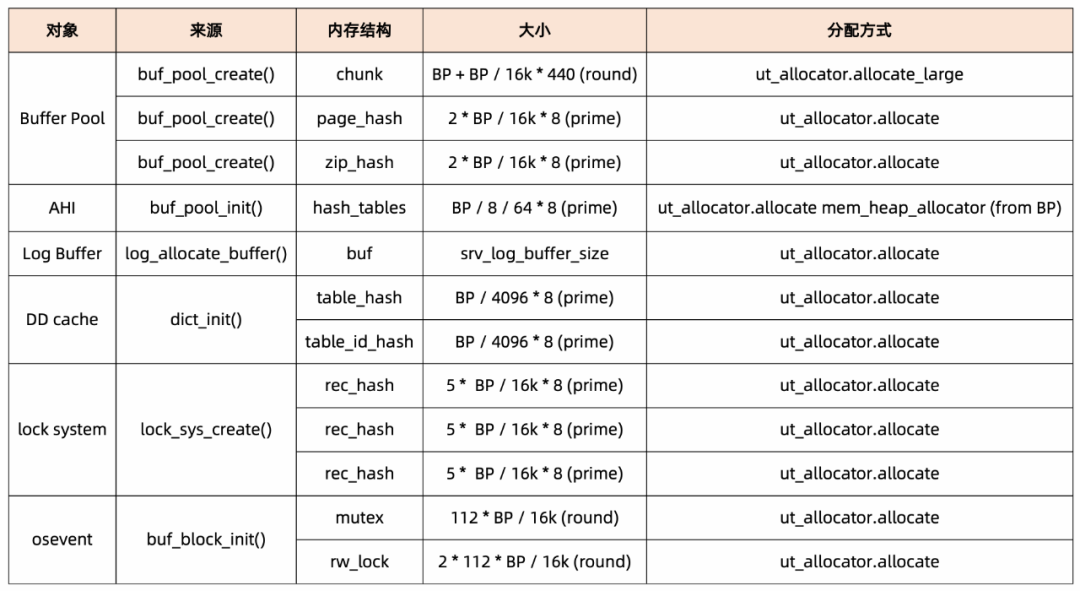
BP指代innodb_buffer_pool_size,round代表分配的大小需要做圆整对齐处理、prime代表需要做质数化处理。
● BP 指定的 size 最终体现在 chunk 的内存中,实际内存和指定的 size 可能存在差异。
● 在实际的内存分配中,除了指定的 BP 大小之外,系统还会产生额外的内存,本节只是列举部分。Oracle 的分配内存的方式对用户更加友好,指定固定的内存,具体的分配在内部完成,可以很好控制内存总量。
参考
[1] https://dev.mysql.com/doc/refman/8.0/en/innodb-architecture.html
[2] https://dev.mysql.com/doc/refman/8.0/en/innodb-buffer-pool.html
[3] http://mysql.taobao.org/monthly/2021/01/06/
[4] https://www.leviathan.vip/2018/12/18/InnoDB%E7%9A%84BufferPool%E5%88%86%E6%9E%90/
[5] https://juejin.cn/post/7109811386091307039
[6] https://juejin.cn/post/6882298660965580814
[7] https://juejin.cn/post/6974389300884570149
[8] https://dev.mysql.com/doc/refman/8.0/en/innodb-change-buffer.html
[9] 《MySQL内核:InnoDB存储引擎 》Chapter 11
[10] https://juejin.cn/post/6892659139794157575
[11] https://dev.mysql.com/doc/refman/8.0/en/innodb-adaptive-hash.html
[12] https://dev.mysql.com/doc/refman/8.0/en/innodb-redo-log-buffer.html
[13] https://dev.mysql.com/doc/refman/8.0/en/memory-use.html










 点击「阅读原文」了解云数据库RDS MySQL更多内容
点击「阅读原文」了解云数据库RDS MySQL更多内容
