





count(列)与count(*)比较谁更快?
in与exists是速度之争?
看似等价的,实则暗藏玄机,了解了本质才能更好使用它们。
做个试验,看看到底谁更快?
SQL> create table t as select * from dba_objects;
Table created.
SQL> update t set object_id =rownum;
72367 rows updated.
SQL> set timing on
SQL> set linesize 1000
SQL> set autotrace on
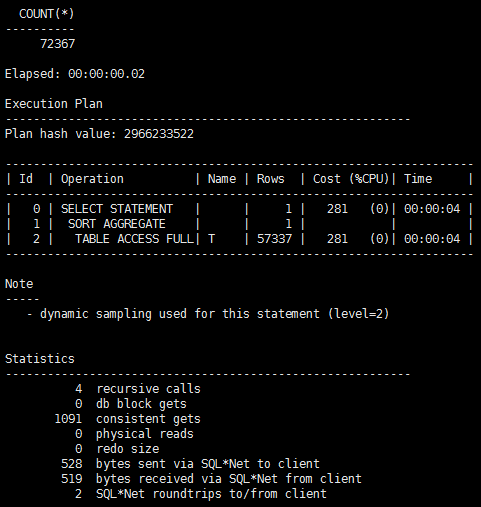
SQL> select count(*) from t;
SQL> select count(object_id) from t;
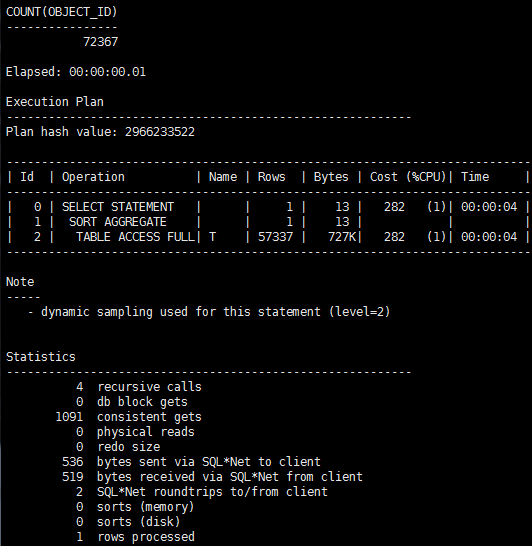
看起来是一样快,但是如果条件有变化呢?
比如建个索引:
SQL> create index idx_object_id on t(object_id);
Index created.
再来查一遍:
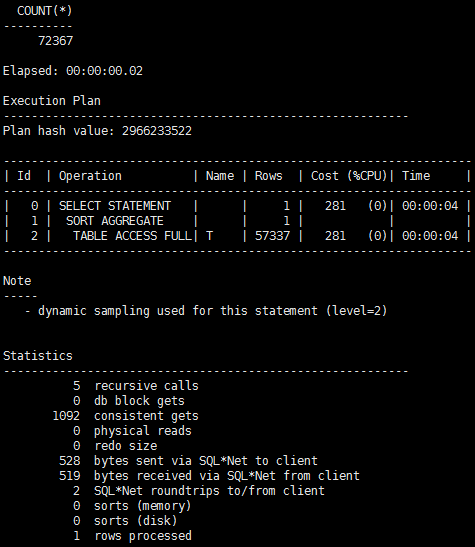
SQL> select count(*) from t;
SQL> select count(object_id) from t;
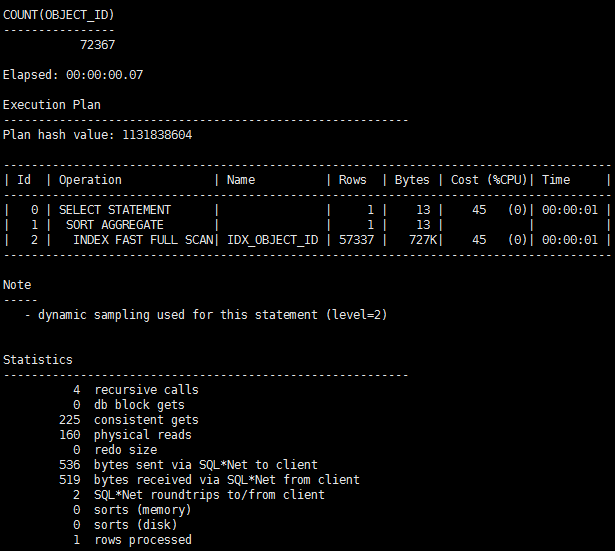
现在发现COUNT(列)比COUNT(*)要快,因为COUNT(*)不能用到索引,而COUNT(列)可以。那如果条件再有变化呢,比如,将列object_id设置为非空:
SQL> alter table T modify object_id not null;
Table altered.
再来查一遍:
SQL> select count(*) from t;
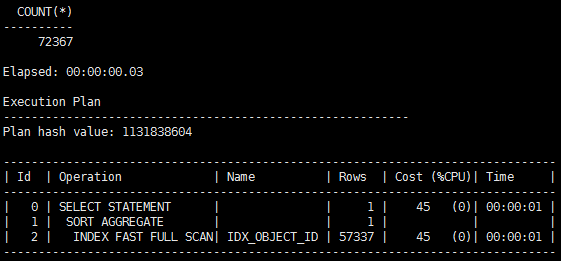
SQL> select count(object_id) from t;
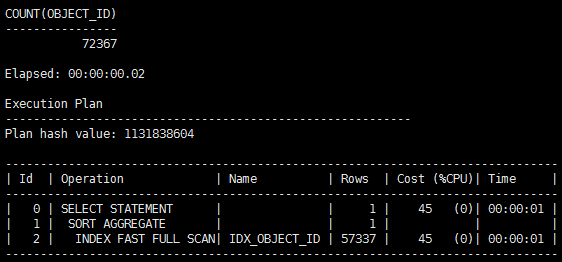
结果又是一样的了,综上所述,似乎两个语句根本就是一样快,如果索引列是非空的,count(*)也可以用到索引,这样两个语句就一样快了,但是真的是这样的吗?我们发现这两个语句其实没法比较,因为它们都不等价。
Tips:Oracle优化器的算法是,列的偏移量决定性能,列越靠后,访问的开销越大。由于count(*)的算法与偏移量无关,所以count(*)最快,count(最后列)最慢。设计表的时候建议把常用的列尽量靠前放。
用not exists代替 not in
在子查询中,not in子句将执行一个内部的排序和合并,无论在哪种情况下,not in都是最低效的(它对子查询中的表执行了一个全表遍历)。使用not exists子句可以有效的利用索引。尽可能使用not exists来代替not in,尽管二者都使用了not(不能使用索引而降低速度),not exists要比not in 查询效率更高。
例:
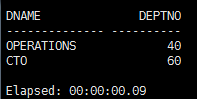
SQL> select dname,deptno from dept where deptno not in(select deptno from emp);
SQL> select dname,deptno from dept where not exists (select deptno from emp where dept.deptno = emp.deptno);
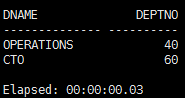
第二个要比第一个的执行性能好很多。
因为第一个中对emp进行了full table scan,这是很浪费时间的操作,而第一个中没有用到emp的index,因为没有where子句。而第二个中的语句对emp进行的是缩小范围的查询。
那是不是都要用not exists 而不要用not in呢?
不一定。
还要考虑两个关联表的大小,如果两个表中一个较小,一个是大表,则子查询表大的用exists,子查询表小的用in。
例如:
表A(小表),表B(大表)
select * from A where cc in (select cc from B); --效率低,用到了A表上cc列的索引;
select * from A where exists(select cc from B where cc=A.cc); -- 效率高,用到了B表上cc列的索引
in 其实与等于相似,比如in(1,2) 就是 = 1 or = 2的一种简单写法,所以一般在元素少的时候使用 in,如果多的话就用exists。

