





案例环境
SQL> drop table t purge;
SQL> create table t as select * from dba_objects;
SQL> update t set object_id = rownum;
SQL> alter table t add constraint pk_object_id primary key (OBJECT_ID);
SQL> set autotrace on
SQL> set linesize 1000
测试案例
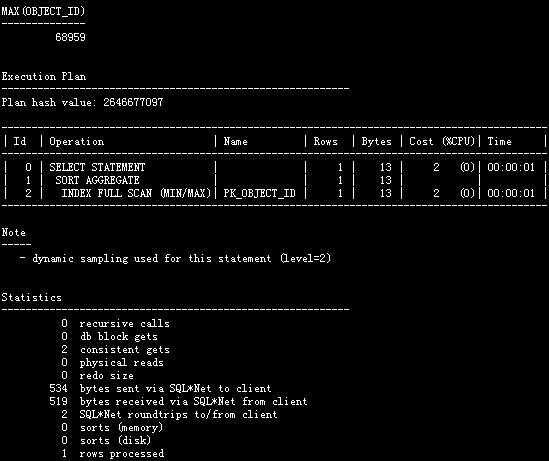
SQL> select max(object_id) from t;
使用INDEX FULL SCAN (MIN/MAX)扫描类型
同样min()也是,执行计划这里就不再列出。
SQL> select min(object_id) from t;
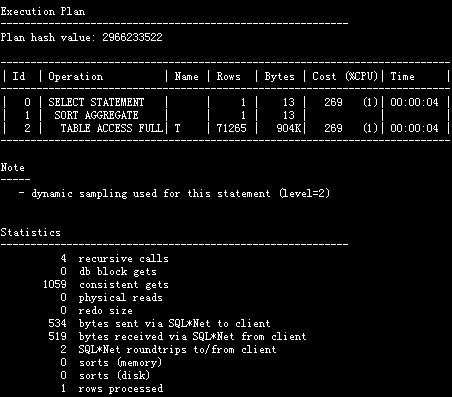
没用到索引的情况
(看代价和逻辑读的差异)
SQL> select *+full(t)*/ max(object_id) from t;
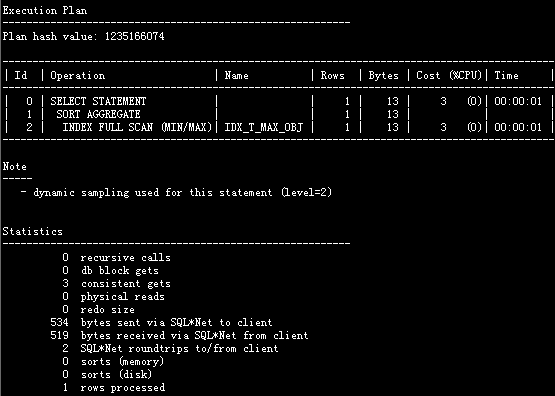
有索引的情况下,记录数增加,看性能变化
SQL> set autotrace off
SQL> create table t_max as select * from dba_objects;
SQL> insert into t_max select * from t_max;
SQL>
SQL>
SQL> select count(*) from t_max;
COUNT(*)
----------
551688
SQL> create index idx_t_max_obj on t_max(object_id);
记录增加对性能也不会有影响。
object _id如果允许为空,加个索引后,还会走INDEX FULL SCAN (MIN/MAX)高效算法吗?答案:会,取最大值最小值忽略空值。
附加
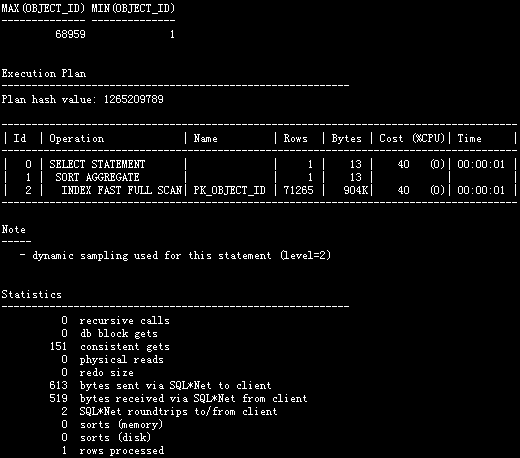
max()和min()同时出现时,Oracle使用的扫描方式还是这样吗?
测试案例:
SQL> select max(object_id),min(object_id) from t;
执行计划
并没有使用INDEX FULL SCAN (MIN/MAX)索引。
原来INDEX FULL SCAN (MIN/MAX)是无法一次取到两个值的,所以ORACLE不得不选择了INDEX FULL SCAN ,把叶子的索引扫了个遍,同时取到了两个值。
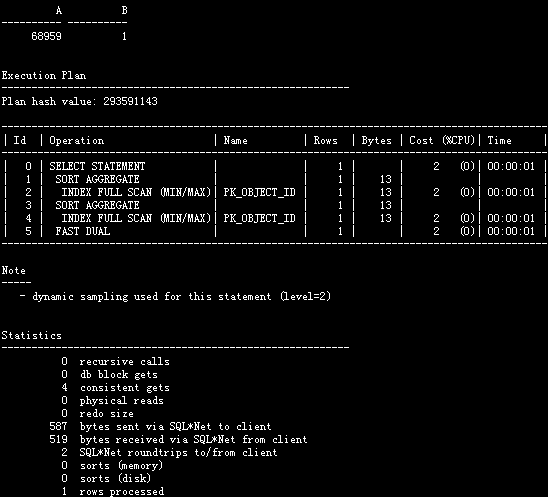
怎样使用高效的INDEX FULL SCAN (MIN/MAX)索引呢?
将语句改写成如下:
SQL> select(select max(object_id) from t) a,(select min(object_id) from t)b from dual;
执行计划
总结:
max() 和 min() 是大家常用的使用频率很高的sql写法,各种报表中需要这样编写的地方很多,对这样的查询建立索引,在保证该列不空的情况下,就有可能利用到INDEX FULL SCAN (MIN/MAX)这个索引扫描方式,能为查询性能带来很大的提高。

