案例环境
SQL> drop table emp purge;
SQL> CREATE TABLE emp(
emp_id NUMBER(6),
ename VARCHAR2(45),
dept_id NUMBER(4),
hire_date DATE,
sal NUMBER(8,2));
插入emp数据:
SQL> INSERT INTO emp (emp_id, ename, dept_id, hire_date, sal) VALUES (101, 'Tom', 20, TO_DATE('21-09-1989', 'DD-MM-YYYY'), 2000);
SQL> INSERT INTO emp (emp_id, ename, dept_id, hire_date, sal) VALUES (102, 'Mike', 20, TO_DATE('13-01-1993', 'DD-MM-YYYY'), 8000);
SQL> INSERT INTO emp (emp_id, ename, dept_id, hire_date, sal) VALUES (120, 'John', 50, TO_DATE('18-07-1996', 'DD-MM-YYYY'), 1000);
SQL> INSERT INTO emp (emp_id, ename, dept_id, hire_date, sal) VALUES (121, 'Joy', 50, TO_DATE('10-04-1997', 'DD-MM-YYYY'), 1000);
SQL> INSERT INTO emp (emp_id, ename, dept_id, hire_date, sal) VALUES (122, 'Rich', 50, TO_DATE('01-05-1995', 'DD-MM-YYYY'), 4000);
SQL> INSERT INTO emp (emp_id, ename, dept_id, hire_date, sal) VALUES (123, 'Kate', 50, TO_DATE('10-10-1997', 'DD-MM-YYYY'), 4000);
SQL> INSERT INTO emp (emp_id, ename, dept_id, hire_date, sal) VALUES (124, 'Jess', 50, TO_DATE('16-11-1999', 'DD-MM-YYYY'), 7000);
SQL> INSERT INTO emp (emp_id, ename, dept_id, hire_date, sal) VALUES (100, 'Stev', 10, TO_DATE('01-01-1990', 'DD-MM-YYYY'), 7000);
SQL> COMMIT;
SQL> set linesize 2000
SQL> set pagesize 2000
SQL> col emp_id format 999
SQL> col dept_id format 99
SQL> col sal format 9999
SQL> col ename format a5
SQL> col hire_date FORMAT DATE
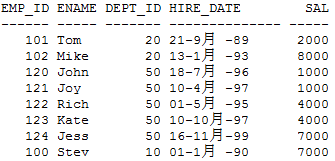
SQL> SELECT * from emp;
案例1
查出各组的最高或者最低收入的雇员
查出各组收入最高的雇员:
SQL> SELECT emp_id, ename, dept_id, hire_date,sal
FROM (SELECT emp.*,
row_number() OVER(PARTITION BY dept_id ORDER BY sal DESC) AS N
FROM emp)
WHERE N = 1;
查出各组收入最低的雇员:
SQL> SELECT emp_id, ename, dept_id, hire_date,sal
FROM (SELECT emp.*,
row_number() OVER(PARTITION BY dept_id ORDER BY sal) AS N
FROM emp)
WHERE N = 1;


如果要考虑并列,就须要用下面的,就要用RANK或DENSE_RANK
(顺便 开启set autotrace on 来看看分析函数和非分析函数写法的性能差异)
SET autotrace ON
SET linesize 1000
SET pagesize 2000
查出各组收入最低的雇员(使用分析函数):
SQL> SELECT emp_id, ename, dept_id, hire_date,sal
FROM (SELECT emp.*,
dense_rank() OVER(PARTITION BY dept_id ORDER BY sal ) AS N
FROM emp)
WHERE N = 1;
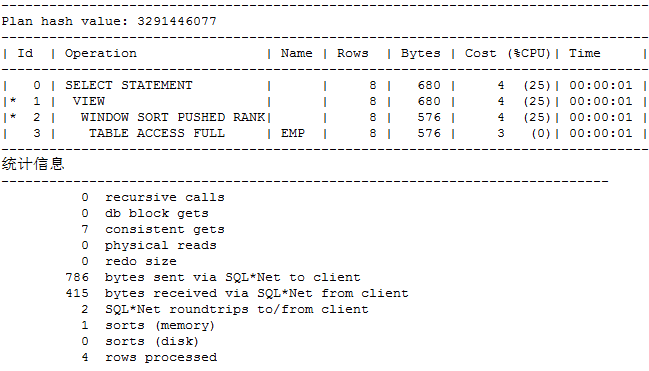
执行计划:
使用普通函数的写法实现:
WITH t as
(SELECT dept_id, min(sal) as min_sal FROM emp GROUP BY dept_id)
select emp.emp_id, emp.ename, emp.dept_id, emp.hire_date,emp.sal
from emp, t
where emp.dept_id = t.dept_id
and emp.sal = t.min_sal;
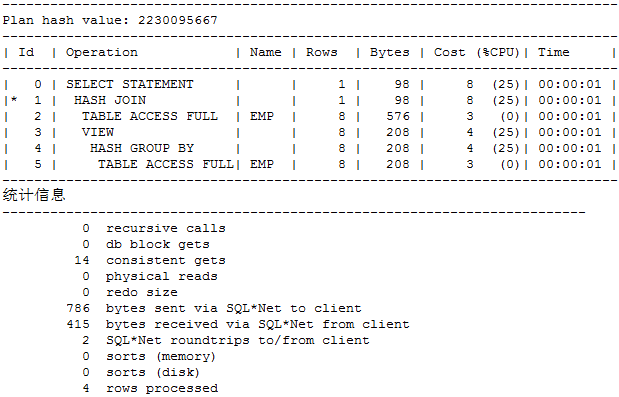
执行计划:
可见分析函数写法比普通写法的性能要好。


例如:
需求要查出各组最高最低收入的前几名
如前3名,就是上述语句的where n=1 改为 n<=3;
或者需求改成查出薪水最高的第几名,那就直接在案例1中的条件 n=几就可以了。
案例2
查出查询部门最雇员和最近雇员的信息(使用FIRST_VALUE、LAST_VALUE)
SQL> select * from emp order by dept_id,hire_date;
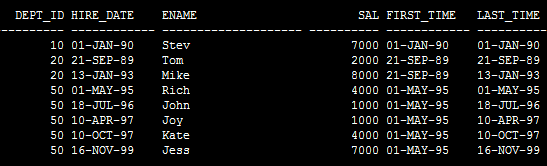
SQL> select
dept_id,
hire_date,
ename,
sal,
first_value(hire_date) over (partition by dept_id order by hire_date) first_time,
last_value(hire_date) over (partition by dept_id order by hire_date desc) last_time
from emp;
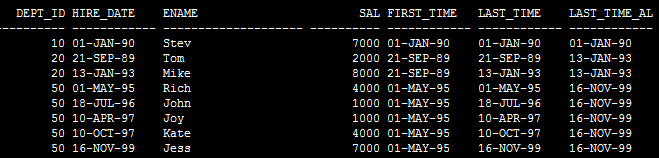
SQL> select
dept_id,
hire_date,
ename,
sal,
first_value(hire_date) over (partition by dept_id order by hire_date) first_time,
last_value(hire_date) over (partition by dept_id order by hire_date desc) last_time,
last_value(hire_date) over (partition by dept_id order by hire_date rows between unbounded preceding and unbounded following) last_time_all
from emp;