





测试环境
SQL> drop table dept purge;
SQL> drop table emp purge;
SQL> create table dept as select * from scott.dept;
SQL> create table emp as select * from scott.emp;
SQL> set term off
SQL> set heading on
SQL> set verify off
SQL> set feedback off
SQL> set linesize 2000
SQL> set pagesize 30000
SQL> set long 999999999
SQL> set longchunksize 999999
SQL> set autotrace off
cube分组例子
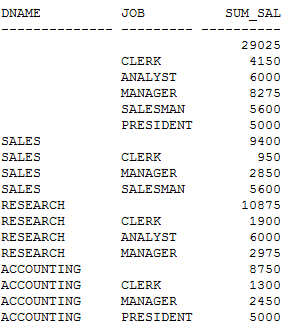
SQL> SELECT a.dname,b.job, SUM(b.sal) sum_sal
FROM dept a,emp b
WHERE a.deptno = b.deptno
GROUP BY CUBE(a.dname,b.job);
部分CUBE分组
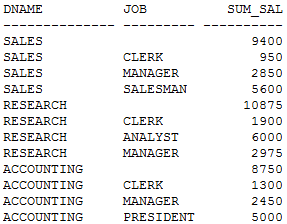
SQL> SELECT a.dname,b.job, SUM(b.sal) sum_sal
FROM dept a,emp b
WHERE a.deptno = b.deptno
GROUP BY a.dname,CUBE(b.job);
cube与rollup的差别对比
rollup(a,b) 统计列包含:(a,b)、(a)、()
rollup(a,b,c) 统计列包含:(a,b,c)、(a,b)、(a)、()
…以此类推ing…
cube(a,b) 统计列包含:(a,b)、(a)、(b)、()
cube(a,b,c) 统计列包含:(a,b,c)、(a,b)、(a,c)、(b,c)、(a)、(b)、(c)、()
…以此类推ing…总结:CUBE在ROLLUP的基础上进一步从各种维度上给出细化的统计汇总结果。

