测试环境
SQL> drop table dept purge;
SQL>drop table emp purge;
SQL>create table dept as select * from scott.dept;
SQL>create table emp as select * from scott.emp;
SQL>set term off
SQL>set heading on
SQL>set verify off
SQL>set feedback off
SQL>set linesize 2000
SQL>set pagesize 30000
SQL>set long 999999999
SQL>set longchunksize 999999
SQL>set autotrace off
案例1
按部门名和职位分别汇总工资:
SQL>SELECT a.dname,b.job,SUM(b.sal) sum_sal FROM dept a,emp b WHERE a.deptno = b.deptno GROUP BY a.dname,b.job;
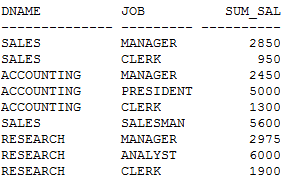
需求改变,要再加一列部门汇总
首先想到如下的办法实现需求:
SQL> set autotrace on
SQL> select * from (
SELECT a.dname,b.job,SUM(b.sal) sum_sal
FROM dept a,emp b
WHERE a.deptno = b.deptno
GROUP BY a.dname,b.job
UNION ALL
--实现了部门的小计
SELECT a.dname,NULL, SUM(b.sal) sum_sal
FROM dept a,emp b
WHERE a.deptno = b.deptno
GROUP BY a.dname
UNION ALL
--实现了所有部门总的合计
SELECT NULL,NULL, SUM(b.sal) sum_sal
FROM dept a,emp b
WHERE a.deptno = b.deptno)
order by dname;
union all 合并笨办法产生的执行计划:
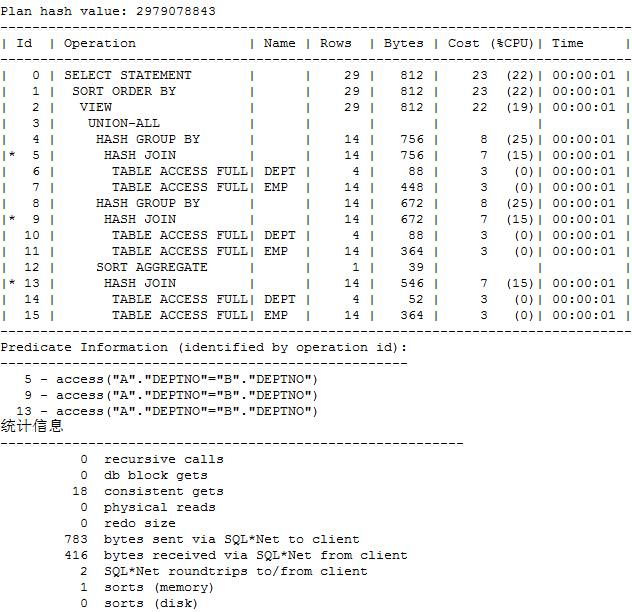
以上办法开销太大,需要优化,可以用rollup实现,性能大幅提高
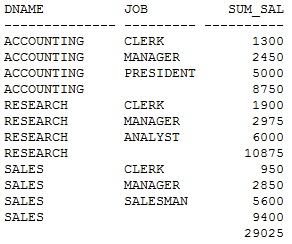
SQL> set autotrace on
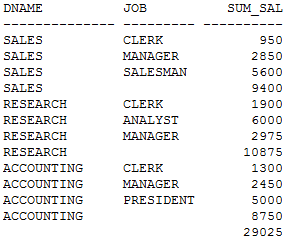
SQL> SELECT a.dname,b.job, SUM(b.sal) sum_sal
FROM dept a,emp b
WHERE a.deptno = b.deptno
GROUP BY ROLLUP(a.dname,b.job);
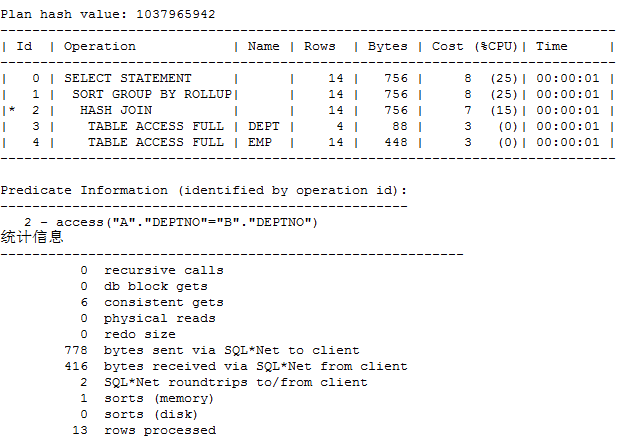
rollup写法产生的执行计划:
这里可以清楚的看到,表的访问次数比union all硬拼凑要少,而且COST和逻辑读也少的多。
案例2
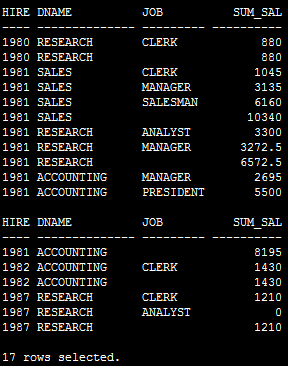
如果需求再多一个维度,比如再增加雇佣年份的统计,之前union all硬拼凑的方法要崩溃了吧,不过rollup轻松搞定,如下:
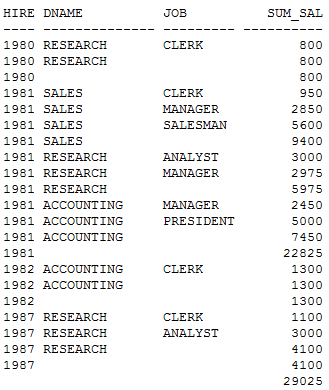
SQL> SELECT to_char(b.hiredate,'yyyy') hire_year,a.dname,b.job, SUM(sal) sum_sal
FROM dept a,emp b
WHERE a.deptno = b.deptno
GROUP BY ROLLUP(to_char(b.hiredate,'yyyy'),a.dname,b.job);
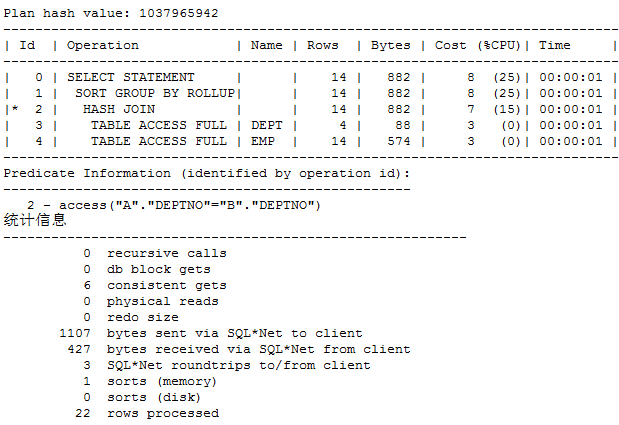
执行计划:
多了一个维度的统计,无论是COST还是逻辑读,都没有增加。
案例3
另外,不止是增加维度,更换维度的次序,对rollup 也是轻而易举的事,如下:
SQL> SELECT b.job,a.dname, SUM(b.sal) sum_sal
FROM dept a,emp b
WHERE a.deptno = b.deptno
GROUP BY ROLLUP(b.job,a.dname);
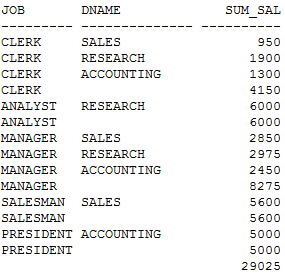
扩展(部分字段分组)
SQL> SELECT to_char(b.hiredate,'yyyy') hire_year,a.dname,b.job, SUM(sal) sum_sal
FROM dept a,emp b
WHERE a.deptno = b.deptno
GROUP BY to_char(b.hiredate,'yyyy'),a.dname,ROLLUP(b.job);