





跟 Doris 代码耦合度高,需要自己打包编译 Doris 源码 只支持 C++ 语言并且 UDF 代码出错会影响 Doris 集群稳定性 对于只熟悉 Hive、Spark 等大数据组件的用户有一定使用门槛
不熟悉 C++?Java 代码一样可以实现自己的 UDF 使用条件苛刻?只要有 Jar 包就能使用 担心稳定性?Java UDF 出错只影响自身,对 Doris 的稳定性几乎无影响 迁移旧大数据平台的数据和 UDF 费时费力?Java UDF 完全兼容 Hive UDF,轻松实现快速迁移 .......
设计思路
大体思路
Apache Doris 的 BE 是由 C++ 代码编写,如果想在 Doris 中实现 Java UDF,不可避免需要调用 JNI,而不正确的 JNI 调用将导致严重的性能问题。那么该如何设计 Java UDF 以解决这个问题呢?
首先,制定用户在创建 UDF 时必须遵循的一些规则。例如,UDF 类必须具有 Evaluate 方法,并且必须是 Public 和 Non-Static 的。这些规则确保我们可以正确调用 UDF。
其次,Doris 查询引擎会执行一个新的 Java 函数调用,BE 会创建或重用一个 JVM 来调用真正的 Java UDF。为了隔离不同的 UDF 实例,选择使用不同的类加载器来加载 UDF。
最后,由于执行时是向量化的,因此可以实现一次执行多行数据只调用一次 JNI,原因是 JNI 开销被输入列中所有行分摊了[1], 这将给用户带来更好的性能体验。
详细思路
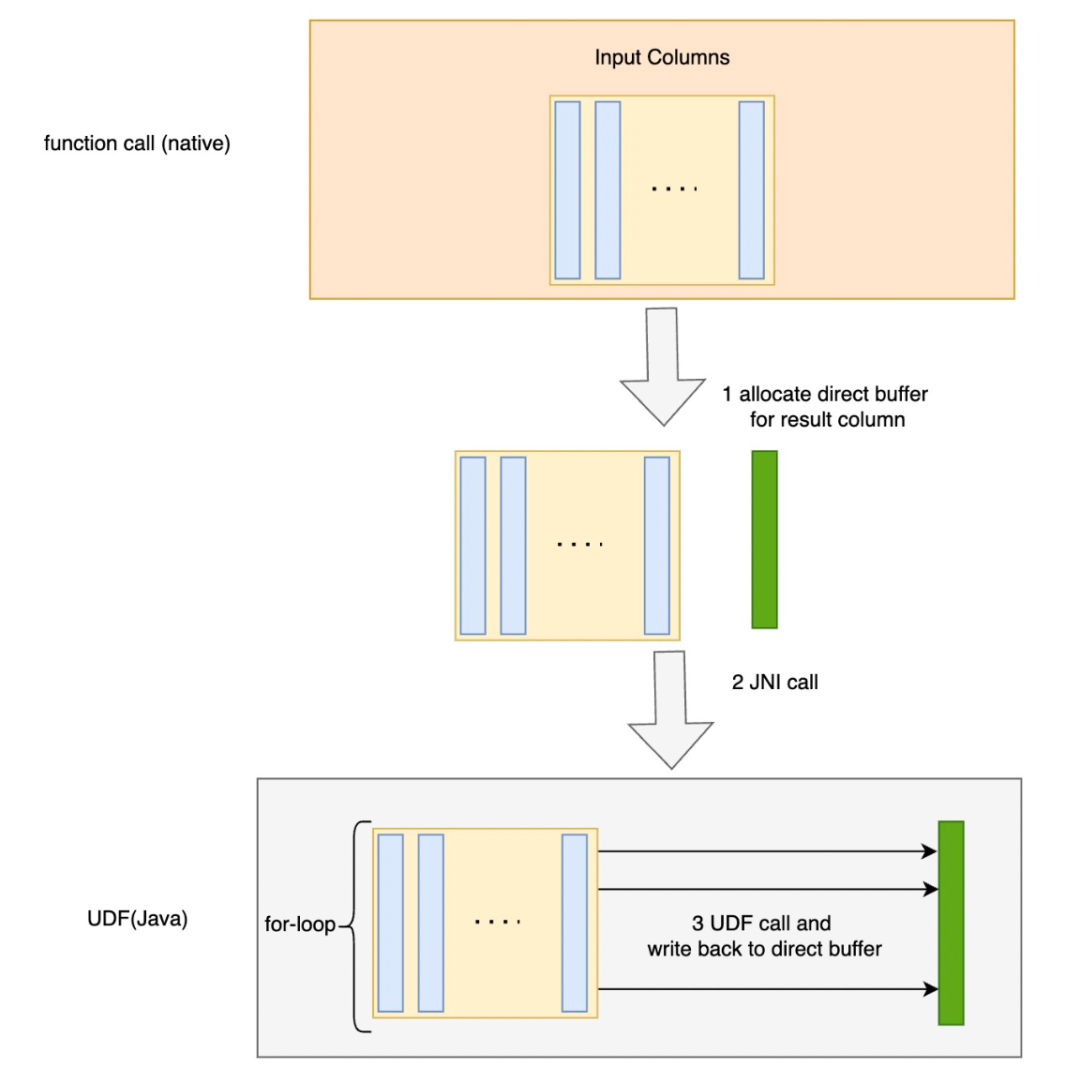
一般 UDF(定长 UDF)
此处的基本思想是传递直接指向输入缓冲区和输出缓冲区的地址,Apache Doris 可以直接从所给地址中读取和写回数据,这可以帮助 Doris 避免不必要的数据拷贝。Input Buffer 和 Output Buffer 都是 JVM 的堆外内存,可以直接通过Java 的 API 来操作这部分内存。
整体执行模式如下图:
Java UDF 的使用
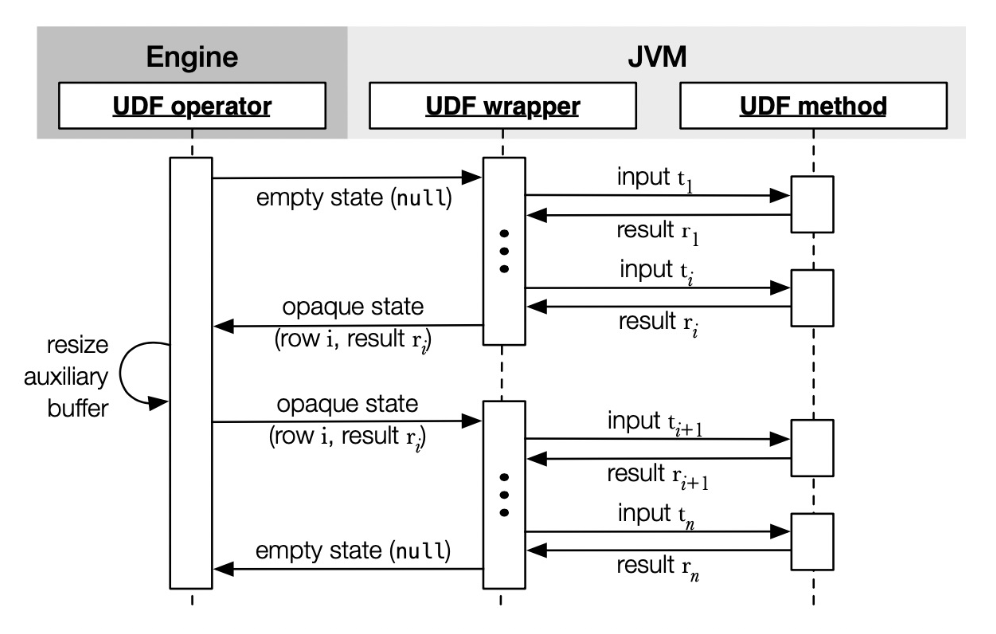
Java UDF 使用起来非常简单。Java UDF 在 Apache Doris 内注册完成后,Apache Doris 执行时通过调用 jar 包来实现 UDF 逻辑。顺序结构如下图:
具体步骤
AddOne.java文件内容如下:
// Licensed to the Apache Software Foundation (ASF) under one
// or more contributor license agreements. See the NOTICE file
// distributed with this work for additional information
// regarding copyright ownership. The ASF licenses this file
// to you under the Apache License, Version 2.0 (the
// "License"); you may not use this file except in compliance
// with the License. You may obtain a copy of the License at
//
// http://www.apache.org/licenses/LICENSE-2.0
//
// Unless required by applicable law or agreed to in writing,
// software distributed under the License is distributed on an
// "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
// KIND, either express or implied. See the License for the
// specific language governing permissions and limitations
// under the License.
package org.apache.doris.udf;
import org.apache.hadoop.hive.ql.exec.UDF;
public class AddOne extends UDF {
public Integer evaluate(Integer value) {
return value == null? null: value + 1;
}
}
执行 mvn 打包命令
mvn clean package
CREATE FUNCTION java_udf_name(int) RETURNS int PROPERTIES (
"file"="file:///path/to/your_jar_name.jar",
"symbol"="org.apache.doris.udf.AddOne",
"always_nullable"="true",
"type"="JAVA_UDF"
);
建表:
CREATE TABLE IF NOT EXISTS test.t1 (`col_1` int NOT NULL)
DISTRIBUTED BY HASH(col_1) PROPERTIES("replication_num" = "1");
插入数据:
insert into test.t1 values(1),(2);
使用udf:
MySQL [(none)]> select col_1, java_udf_name(col_1) as col_2 from test.t1;
+------------+------------+
| col_1 | col_2 |
+------------+------------+
| 1 | 2 |
| 2 | 3 |
+------------+------------+
至此,Doris Java UDF 的创建和使用就完成了,非常简单。
注意事项
最开始需要确定 BE 节点是否配置了 JAVA_HOME
,如果环境变量没有配置,则可以在be/bin/start_be.sh文件第一行加上
export JAVA_HOME=/xxx/xxx
UDF 代码中必须要带有以下信息(UDAF 则替换成对应的)
import org.apache.hadoop.hive.ql.exec.UDF;
创建 Doris java UDF 的语句,其格式如下
CREATE FUNCTION name ([,...])
[RETURNS] rettype
PROPERTIES (["key"="value"][,...])
例子中完整的 SQL如下:
CREATE FUNCTION java_udf_name(int) RETURNS int PROPERTIES (
"file"="file:///path/to/your_jar_name.jar",
"symbol"="org.apache.doris.udf.AddOne",
"always_nullable"="true",
"type"="JAVA_UDF"
);
例子说明:
java_udf_name
是创建 UDF 的名称,可以进行更改,UDF 名称不能与 Doris 其他函数重名。名称后的
(int)
表示函数输入参数是 int 类型,RETURNS
后的 int 表示函数输出也是 int 类型;输入输出类型跟 Java 代码中 Evaluate 函数的输入输出类型要保持一致。PROPERTIES
file表示 jar 包在本机的路径,应该修改
"/path/to/your_jar_name.jar"
作为 jar 包的绝对路径。如果是多机环境,也可以使用 http 形式表示的路径,例如"file"="http://${host}:${http_port}/${your_jar_file}"Symbol 可以参考 Java 代码中的 Package always_nullable
表示 UDF 返回结果中是否可能出现 NULL 值,如果想要在计算中对出现的NULL值有特殊处理,以确定结果中不会返回 NULL,可以设为false,有利于提升整个查询计算过程的性能。
可以使用python命令来简单启动一个http server:
nohup python -m SimpleHTTPServer 12345 > /dev/null 2>&1
(启动python的目录需要跟你的jar包保持一致,比如你的jar放在A机器的/usr/lib下,那么python命令最好也在该机器的该目录下启动)
收益总结
熟悉 Java 的同学也可以快速上手开发 Doris,使用简单便捷,较大提升开发效率。 兼容 Hive UDF,有效降低从 Hadoop 迁移数据的成本。 UDF 代码出错并不会影响 Doris,某种程度上保证了 Doris 的更好稳定运行。 与 Doris 代码解耦,真正做到了"Write Once Run Anywhere" 执行效率方面,Java UDF 是完全向量化执行的,一次执行多行数据只调用一次 JNI,结合堆外内存、Zero Copy 等优化技术,用户在使用 Java UDF 时,也能得到与之前的 C++ UDF 一致甚至更佳的查询性能体验。
社区贡献
[1] Viktor Rosenfeld, René Müller, Pinar Tözün, etc. Processing Java UDFs in a C++ environment. SoCC 2017: 419-431.
[2] Marcel Kornacker, Alexander Behm, Victor Bittorf, etc. Impala: A Modern, Open-Source SQL Engine for Hadoop. CIDR 2015.
[3]DSIP-001: Java UDF:https://cwiki.apache.org/confluence/display/DORIS/DSIP-001%3A+Java+UDF
本文作者:李仕杨,SelectDB 生态研发工程师,Apache Doris Contributor。
- End-
欢迎更多的开源技术爱好者加入 Apache Doris 社区交流群,携手成长,共建社区生态。

