





1.RuntimeFilter
1.1 什么是RuntimeFilter
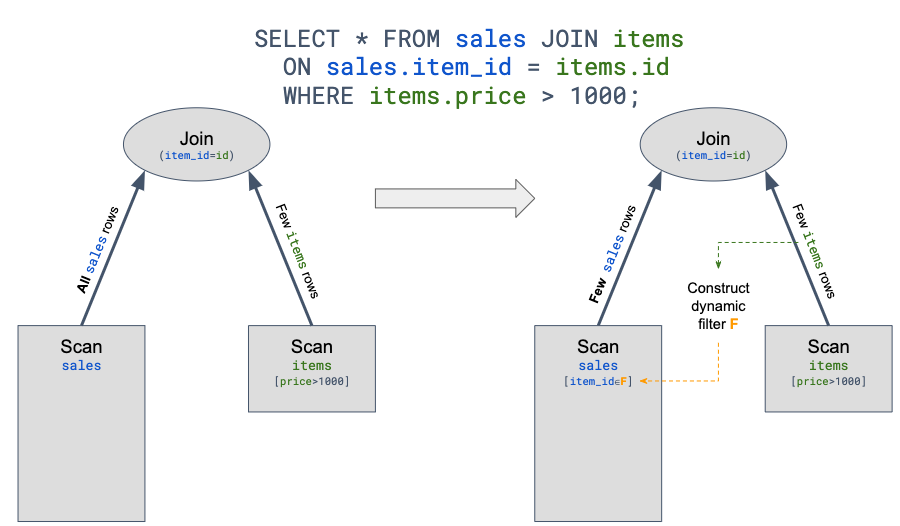
图1
RuntimeFilter优化生效的流程如下:
1. 根据查询的Join Condition,生成一条动态过滤条件传递规则:决定生产者(生成过滤条件的子查询)和消费者(应用过滤条件进行过滤的子查询)。
2. 先执行生产者,用实时结果集动态构建一个RuntimeFilter Object。
3. 将这个RuntimeFilter Object传递给消费者。
4. 消费者使用RuntimeFilter Object进行过滤,从而提前减少后续参与计算的数据量。通常情况下,消费者可以利用RuntimeFilter Object在数据进行分布式shuffle之前提前过滤掉部分数据,从而减少网络传输的数据量。更极端情况下,RuntimeFilter Object还可能下推到存储端命中索引裁剪,直接减少TableScan的磁盘扫描数据量。
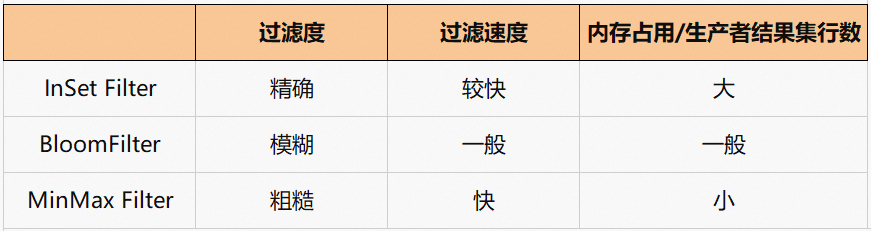
RuntimeFilter Object的过滤原则是属于True Negative范畴,并不保证能把所有无关数据提前过滤掉。业界常见的RuntimeFilter Object包括MinMax Filter、InSet Filter、Bloom Filter等,它们的构建成本、内存占用大小以及单次查找耗时都远小于HashBasedJoin计算使用的HashTable,这是RuntimeFilter可以在Join之前预先粗过滤的根本。
1.2 RuntimeFilter的难点
接下来本文将从创建RuntimeFilter传递规则、RuntimeFilter Object传递以及RuntimeFilter Object的生成和使用三个方面来展开介绍整个RuntimeFilter技术的难点。
▶︎ 1.2.1 如何选择RuntimeFilter Object的生产者以及对应的消费者们
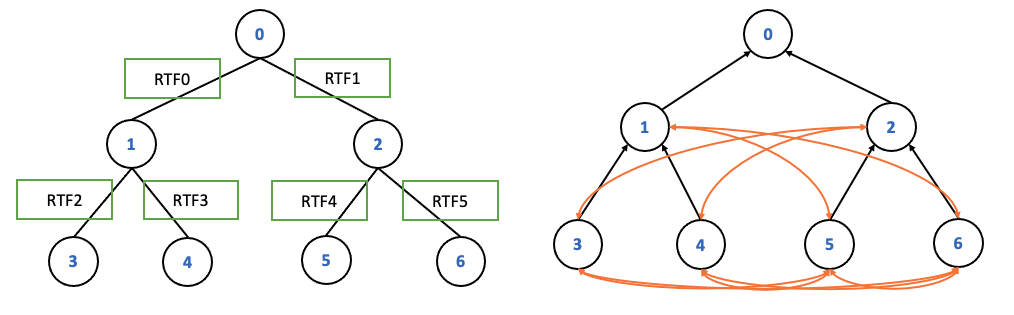
在实际的实现中,我们往往不会生成这样的全联通依赖关系,一方面这会产生循环依赖,不可能全部生效;另一方面生产和消费RuntimeFilter本身都有开销,我们应该选择其中开销更低收益更大的。这包含了以下三个方面的问题:
3.生产者和消费者的关系不能形成循环依赖。
前面我们在介绍RuntimeFilter Object的时候,只是简单把它描述成了一个单一逻辑实体。实际情况下,由于常见的分布式MPP数据库执行引擎具备单机&多机并行能力的,上一节中我们在执行计划图里描绘的一个逻辑RuntimeFilter Object可能是由N个机器节点上的M*N个内存对象共同构成的。这使得RuntimeFilter Object在生产者和消费者之间的传播关系变得非常复杂,这种传播关系打破了SQL执行引擎原有的自底向上数据传播模式。
RuntimeFilter Service是业界最常见的RuntimeFilter Object传递实现,包括Impala、Doris等。这种实现思路是在Coordinator节点(前端节点)上起一个专门的服务,负责接收所有生产者生成的partial RuntimeFilter Object,执行RuntimeFilter Object合并,再广播发给消费者。
2.Sideways Information Passing框架(SIP)
ADB SIP框架是一种SQL执行时的信息收集传递框架,传递的信息可以是数据特征、统计信息也可以是一个临时内存表。一个抽象的SIP框架,不需要感知它收集、传递的信息具体内容或类别,只需要具备收集发送对应的运行时信息能力,Session淘汰能力,以及最优的信息传递链路搭建能力。
2.1 SIP传递的运行时信息概念
运行时信息由类型和粒度来定义,与信息的发布订阅者无关,是对信息本身的一个描述。
类型:信息的类型,比如RowCount/Ndv/Histogram/HashSet/MagicSet等。 粒度:在分布式计算引擎中,数据通过一定的算法划分为不同的分片并行执行。在执行中,每个算子可以获取一个部分的统计信息,如果是传递给具有相同分布属性的算子,可以直接利用分片的统计信息进行一些优化;如果是传递给不同分布属性的算子,或全局的优化器、调度器等模块,就需要讲所有信息聚合在一起生成全局的信息。分片、全局描述的就是信息的粒度。
1.可被推导:基于同一个结果集的信息,支持复杂向简单推导,比如HashSet可以推导Histogram和Ndv。
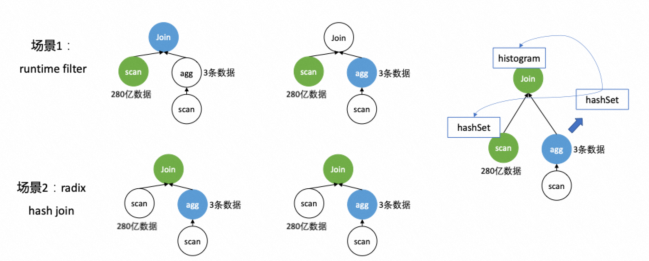
图3
这对我们的实现有三个要求,一是需要定义不同信息类型之间的推导关系,二是定义了发布订阅者的关系是一对多的关系,三是需要有一个信息生命周期的管理,所有订阅者都消费后再进行数据清理。
2.2 SIP框架的组成概念
整个框架由发布者、订阅者、管道三部分组成。信息的发布者是某个算子或者优化器,在执行中进行信息的收集并发布给管道。管道是一个中心化的模块,有一个管理器,进行发布订阅关系的管理和匹配,在接收到来自发布者的信息后,决定发给哪个或哪些消费者;管道还有一个服务模块进行信息的数据接收、处理、分发。订阅者可以是算子、优化器、调度器等,根据应用场景的由规则自定义。
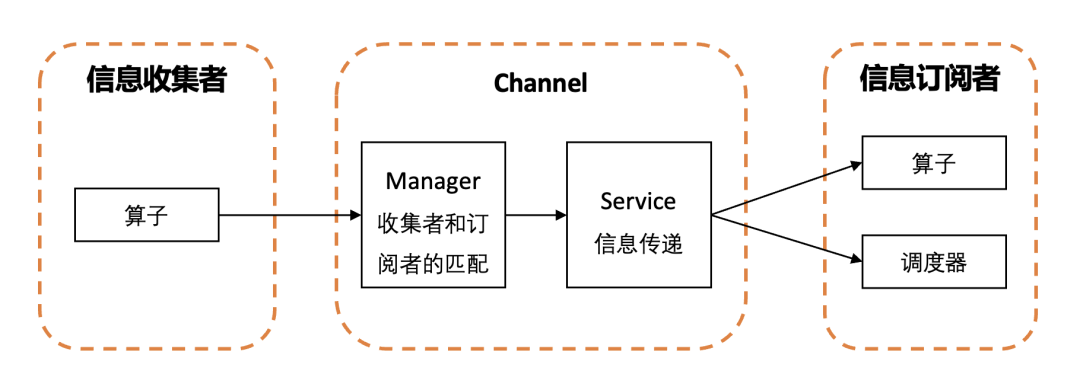
生成信息有一定的开销,我们希望利用已有算子算法的一些特征,在不打断算子流水线计算的同时,以最小的代价进行运行时信息收集。根据算子算法特征的不同,不同类型的信息生成方式各有不同。
1.所有算子可以产生Basic统计信息 - 算子作为执行流水线的组成,在根据其语义进行内存申请和计算时,可以以忽略不计的开销产生一些基础统计信息,如RowCount。
2.某些算子可以产生Derived统计信息 - 比如Hash Agg和Hash Builder Operator,计算过程中就需要生成Hash Table,我们可以直接用这个Hash Table构建出Hash Set,或推导出Histogram和Ndv。
3.可以通过插入算子产生Derived统计信息 - 然而并不是所有算子都会构建Hash Table。我们单独定义了一个InfoCollectOperator,可在不能复用已有算子收集统计信息时用来专门收集统计信息。
根据应用场景的不同,信息的订阅者可以有多种形式。目前我们的应用中包括算子、优化器、调度器。优化器的不同模块中可能有多个订阅者,分别订阅来自不同发布者的不同信息。在执行时,订阅者对发布者有一个信息流的弱依赖。订阅者在整个流水线中有一个阻塞的作用,一般情况下,订阅者会等待收到信息并决策后再继续流水线执行;但由于我们传递的信息是用来调优的,在异常情况下如果超时没有收到信息,为不影响查询整体的响应时间,需要有短路的机制取消阻塞继续执行。
管道分为两个模块。
2.管道服务 - 负责构建数据传输的物理桥梁,在不同节点之间进行信息的传递,由管理器决定传给哪个节点的哪个。
3.AnalyticDB RuntimeFilter实现
AnalyticDB MySQL(简称ADB)是支持高并发低延时查询的新一代云原生数据仓库,高度兼容MySQL协议以及SQL:92、SQL:99、SQL:2003标准,可以对海量数据进行即时的多维分析透视和业务探索。ADB融合了数据库、大数据技术于一体,支持高吞吐的数据实时增删改、低延时的实时分析和复杂ETL混合负载,兼容上下游生态链路工具, 用于构建企业级报表系统、数据仓库和数据服务引擎。
3.1 基于全局等价关系的生产者-消费者的关系发现
这种通过全局等价关系使RuntimeFilter有更多应用场景的思路类似于Data/Join-Induced Predicates (DIP)中的全局思想。DIP通过数据分布特征(data statistics/data layout)和Join列全局等价关系的传导,在计划阶段决定分区裁剪,来减少计算数据量。我们这里的全局等价关系不局限于通过数据分布特征决定分区裁剪,而是应用于广义的RuntimeFilter。
3.2 基于SIP框架的RuntimeFilter Object订阅发布
1.共享:SIP支持一个信息被多个订阅者共享,这个信息只需要产生一次并传递一次到coordinator节点,如果订阅者在同一个计算节点也只需要传递一次。
2.合并:多个信息如果同时产生,我们通过信息合并,在节点间传递时只发送一次网络请求,从而减少网络连接。
3.短路:当信息粒度为分片,即不需要全局信息时,我们直接在节点内部通过传递给对应订阅者短路节点间传递的网络开销。
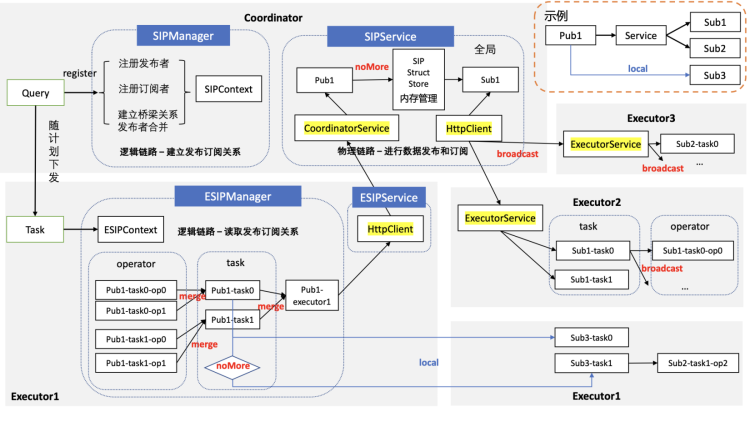
图5
3.3 TPC-DS测试结果
我们在Benchmark数据集TPC-DS 1TB上测试了RuntimeFilter的优化效果。下表计算了RuntimeFilter打开和关闭下的总执行时间和扫描数据量及提升的百分比。图6、图7为query维度的执行时间和扫描数据量对比的柱状图。

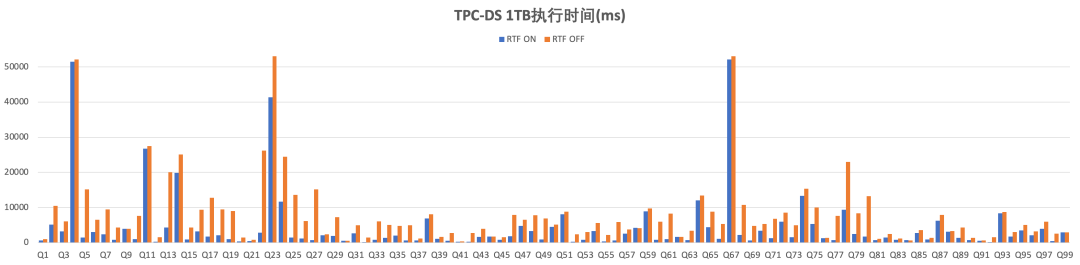
图6
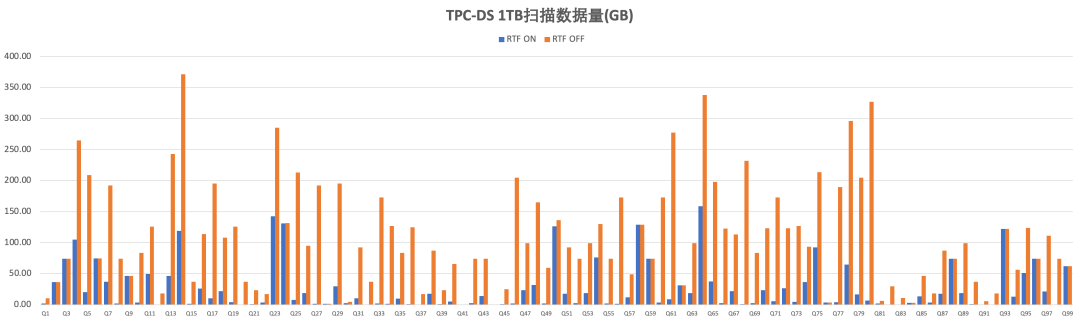
4.总结
AnalyticDB RuntimeFilter具备以下三大优势能力:
AnalyticDB MySQL湖仓版已正式上线商用,对于低成本离线处理ETL有需求,同时又需要使用高性能在线分析支撑BI报表/交互式查询/APP应用的用户,欢迎购买和体验!
/ End /










 点击「阅读原文」查看 云原生数据仓库AnalyticDB 更多内容
点击「阅读原文」查看 云原生数据仓库AnalyticDB 更多内容
