




预写日志(WAL)
预写式日志(Write Ahead Log,WAL)是保证数据完整性的一种标准方法。简单来说,WAL的中心概念是数据文件(存储着表和索引)的修改必须在这些动作被日志记录之后才被写入,即在描述这些改变的日志记录被刷到持久存储以后。如果我们遵循这种过程,我们不需要在每个事务提交时刷写数据页面到磁盘,因为我们知道在发生崩溃时可以使用日志来恢复数据库:任何还没有被应用到数据页面的改变可以根据其日志记录重做(这是前滚恢复,也被称为REDO)。
使用WAL可以显著降低磁盘的写次数,因为只有日志文件需要被刷出到磁盘以保证事务被提交,而被事务改变的每一个数据文件则不必被刷出。日志文件被按照顺序写入,因此同步日志的代价要远低于刷写数据页面的代价。在处理很多影响数据存储不同部分的小事务的服务器上这一点尤其明显。此外,当服务器在处理很多小的并行事务时,日志文件的一个fsync可以提交很多事务。关闭 fsync 对 SELECT 无影响, 而 UPDATE 性能有较大提升,这个场景提升了 111%;当然关闭 fsync 参数的代价是巨大的,当数据库主机遭受操作系统故障或硬件故障时,数据库很有可能无法启动,并丢失数据,建议生产库不要关闭这参数。
WAL也使得在线备份和时间点恢复能被支持。通过归档WAL数据,我们可以支持回转到被可用WAL数据覆盖的任何时间:我们简单地安装数据库的一个较早的物理备份,并且重放WAL日志一直到所期望的时间。另外,该物理备份不需要是数据库状态的一个一致的快照 — 如果它的制作经过了一段时间,则重放这一段时间的WAL日志将会修复任何内部不一致性。
简介
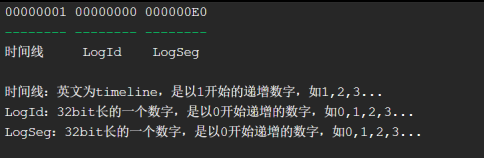
类似于Oracle的redo,PostgreSQL的redo文件被称为WAL文件或XLOG文件,存放在 $PGDATA/pg_xlog或 $PGDATA/pg_wal目录中(PostgreSQL从10版本开始,将所用xlog相关的全部用wal替换了)。任何试图修改数据库数据的操作都会写一份日志到磁盘。wal命名格式文件名称为16进制的24个字符组成,每8个字符一组,每组的意义如下:
通过select pg_switch_xlog()或select pg_switch_wal();可以切换xlog/wal日志。
wal日志即write ahead log预写式日志,简称wal日志。wal日志可以说是PostgreSQL中十分重要的部分,相当于oracle中的redo日志。 当数据库中数据发生变更时: change发生时:先要将变更后内容计入wal buffer中,再将变更后的数据写入data buffer; commit发生时:wal buffer中数据刷新到磁盘; checkpoint发生时:将所有data buffer刷新的磁盘。
如果没有wal日志,那么数据库中将会发生什么? 首先,当我们在数据库中更新数据时,如果没有wal日志,那么每次更新都会将数据刷到磁盘上,并且这个动作是随机i/o,性能可想而知。并且没有wal日志,关系型数据库中事务的ACID如何保证呢? 因此wal日志重要性可想而知。其中心思想就是:先写入日志文件,再写入数据。
说到checkpoint,我们再来看看哪些情况会触发数据库的checkpoing:
1. 手动执行CHECKPOINT命令;
2. 执行需要检查点的命令(例如pg_start_backup 或pg_ctl stop|restart等等);
3. 达到检查点配置时间(checkpoint_timeout);
4. max_wal_size已满。
checkpoint_timeout: 自动 WAL 检查点之间的最长时间,以秒计。合理的范围在 30 秒到 1 天之间。默认是 5 分钟(5min)。增加这个参数的值会增加崩溃恢复所需的时间。
max_wal_size: 在自动 WAL检查点之间允许WAL 增长到的最大尺寸。这是一个软限制,在特殊的情况 下 WAL 尺寸可能会超过max_wal_size, 例如在重度负荷下、archive_command失败或者高的 wal_keep_segments设置。默认为 1 GB。增加这个参数可能导致崩溃恢复所需的时间。( wal_keep_segments用于指定pg_wal目录中保存的过去的wal文件(wal 段)的最小数量,以防备用服务器在进行流复制时需要。)
和max_wal_size相对应的还有个min_wal_size,只要 WAL 磁盘用量保持在这个设置之下,在检查点时旧的 WAL文件总是被回收以便未来使用,而不是直接被删除。
wal切换步骤是这样的:单个wal日志写满(默认大小16MB,编译数据库时指定)继续写下一个wal日志,直到磁盘剩余空间不足min_wal_size时才会将旧的 WAL文件回收以便继续使用。但是这种模式有一个弊端就是如果在checkpoint之前产生了大量的wal日志就会导致发生checkpoint时对性能的影响巨大,因此pg中还有一个参数checkpoint_completion_target 来进行调整。
checkpoint_completion_target: 指定检查点完成的目标,作为检查点之间总时间的一部分。默认是 0.5。假如我的checkpoint_timeout设置是30分钟,而wal生成了10G,那么设置成0.5就允许我在15分钟内完成checkpoint,调大这个值就可以降低checkpoint对性能的影响,但是万一数据库出现故障,那么这个值设置越大数据就越危险。
总结:大多数检查点应该是基于时间的,即由checkpoint_timeout触发。 性能(不频繁检查点)与恢复所需时间(频繁检查点)之间需要抉择: 值在15-30分钟之间是比例合适的,但到1小时不是什么坏事。 在决定checkpoint_timeout后,通过估计WAL的数量选择max_wal_size。 设置checkpoint_completion_target以便内核将数据刷新到磁盘的时间足够(但不是太多)
切换WAL日志
pg_switch_wal()或pg_switch_xlog()强制服务器切换到一个新的预写式日志文件,这允许对当前文件进行归档(假设你正在使用连续归档)。 其结果是在刚刚完成的预写式日志文件中结束预写式日志位置加1。 如果自从上次预写式日志切换以来没有提前写日志活动,pg_switch_wal将不做任何操作,并返回当前正在使用的提前写日志文件的起始位置。默认情况下该函数仅限超级用户使用,但可以授权其他用户执行该函数。pg_switch_xlog()用于PG 10之前,从PG 10开始切换归档日志使用pg_switch_wal()。PG也提供了相应的函数根据LSN获取日志文件名:
自动清理WAL日志
一般来说,设置自动清理archive_log 可以在配置文件中添加archive_cleanup_command = 'pg_archivecleanup archivelocation %r'
或者:alter system set archive_cleanup_command='pg_archivecleanup /var/lib/postgresql/data/pg_wal %r';
