




作者:xuty
* 爱可生开源社区出品,原创内容未经授权不得随意使用,转载请联系小编并注明来源。
一. 大纲
ClickHouse和
StarRocks这两款目前比较流行的实时数仓,文章仅代表个人拙见,有问题欢迎指出,Thanks♪(・ω・)ノ
ClickHouse
:由Yandex(俄罗斯最大的搜索引擎)开源的一个用于实时数据分析的基于列存储的数据库。StarRocks
:新一代的国产 MPP 数据库,由 Apache Doris 数据库演进而来,并且进行了商业化支持。
二. 调研过程简述
2.1. 调研诉求
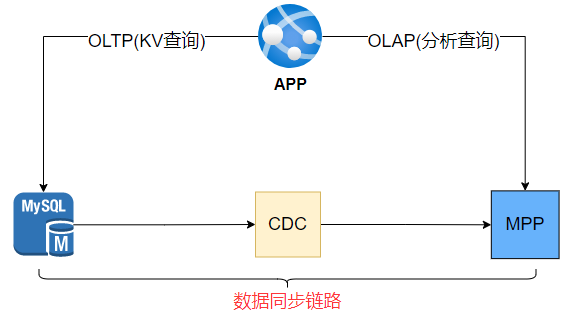
项目上由于 MySQL 中的数据量极速增长后,MySQL 自身无法承担一些实时的olap查询
,所以需要调研一款实时数仓来解决。
实时数仓需要兼容 MySQL 协议与 SQL 语法,开发不需要额外的学习成本,可以快速上手。 日志类数据(只会追加)
需要支撑亿级别实时分析,而业务类数据(不断更新)
需要支撑千万级别实时分析并且对于 JOIN 性能要比较好,因为存在很多 JOIN 查询。整体架构要比较简单,因为很多项目硬件资源相对紧张,并且同步延迟保持在30秒内。 数据同步过程中并不需要清洗转换,只需要将 MySQL 中的数据镜像复制到MPP中即可。
2.2. ClickHouse 调研
日志类流数据的分析,而日志流数据最大的特点就是数据只会追加而不会变更删除,即所谓的
append流。我们用一台单机的 ClickHouse 就可以支撑上亿的日志聚合分析,效果比较满意,部分查询场景还可以配合
物化视图达到更极速的分析。
针对于另外一种业务类数据的分析场景,因为数据会不断的更新,即所谓的change流
,和日志流数据不太相同,因此我们尝试了用ReplacingMergeTree引擎
的自动合并去重能力,再加上查询时显示指定final关键字
去达到精确查询
的效果,但是性能方面不尽如人意,特别是 JOIN 场景。
对于 ClickHouse 的集群模式,因为需要引用 zookeeper 实现分布式协调,并且还需要创建分布式表,个人觉得比较复杂,而且测试下来,对于更新场景效果还是不好,其他精确查询的方式也不太便捷,因此暂时放弃使用ClickHouse实现业务数据的即时分析,更推荐ClickHous去处理日志流数据
。
2.3. StarRocks 调研
非常适合实时更新场景的主键模型(Primary key),和其
比较优越的JOIN性能。
Delete+Insert 的策略,保证同一个主键下仅存在一条记录,虽然牺牲了一些写入性能,但是极大的提升了查询效率。同时 JOIN 性能也相较于 ClickHouse 提升了很多。
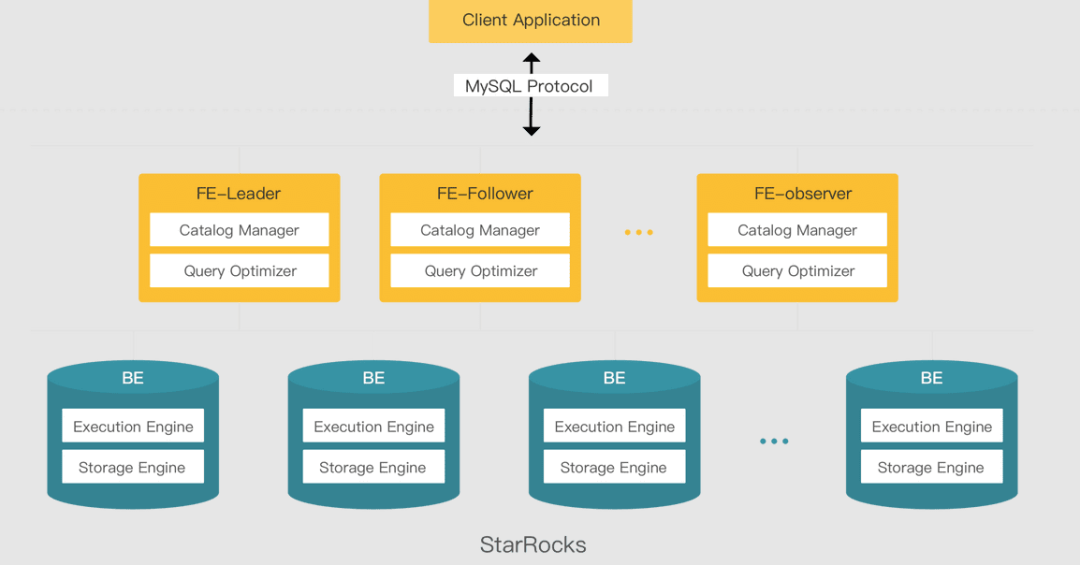
StarRocks 集群方面不依赖于 ZK ,通过 BE 和 FE 模块了组成了存算分离的架构模型,相比于 ClickHouse 的集群实现简单很多,因此我们可以很便捷的完成 StarRocks 集群部署及后期的水平扩展。
最后就是 StarRocks 的兼容性,相比于 ClickHouse ,StarRocks 的 MySQL 兼容性更加优秀,基本完全兼容 MySQL 协议与 SQL 语法,开发也可以无缝切换到 StarRocks 进行开发,比较省事。
三. 实时同步
3.1. ClickHouse 同步
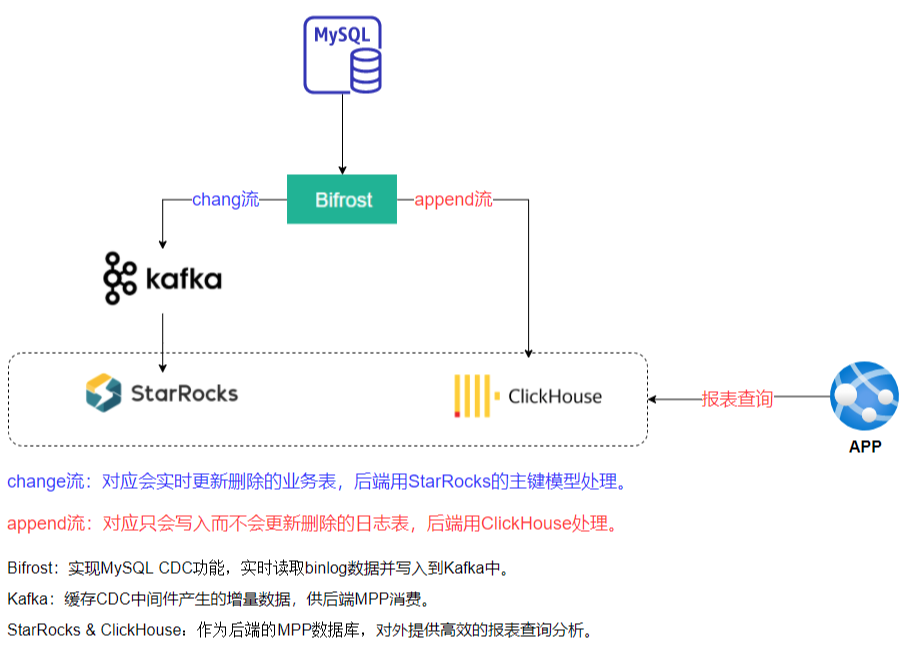
MySQL to ClickHouse 的同步我们使用了 GitHub 上开源的一款 CDC 产品,名字叫做Bifrost
,流程图如下所示,Bifrost 通过解析 MySQL Binlog 然后拼接成 insert 语句,最后批量写入 ClickHouse 中完成实时同步。
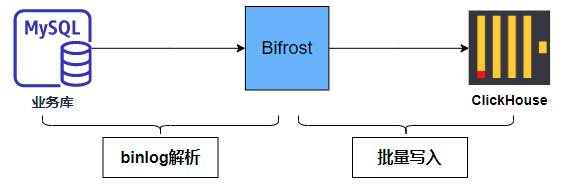
因为 Bifrost 会自动将 CDC 数据拼接成 SQL ,攒成一批数据后批量写入 ClickHouse ,所以并不需要 Kafka 等消息队列做缓冲,因此架构上非常简单。
因为同步走的是SQL语句,所以MySQL端加列等常见DDL也可以同步到ClickHouse中,同步效率上可以支撑每秒上千条数据,延迟在10秒之内,符合我们之前的诉求。
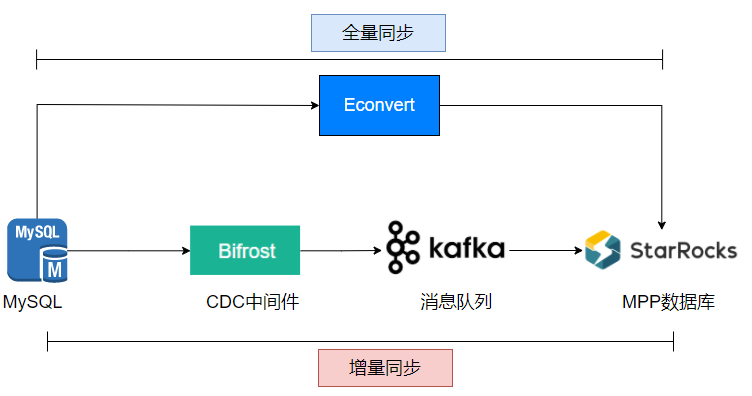
3.2. StarRocks 同步
Routine Load导入功能自主消费kafka数据实现同步。另外额外开发了一个 Econvert的Go 程序,用于批量生成 MySQL to StarRocks 的全量同步脚本,原理是走的 StarRocks 提供的MySQL外表同步数据。
四. 总结
文章推荐:
社区近期动态

 点一下“阅读原文”了解更多资讯
点一下“阅读原文”了解更多资讯