




PolarDB-X 简介
可计算存储简介
PolarDB-X Docker 部署简介
PolarDB-X 架构和部署类型
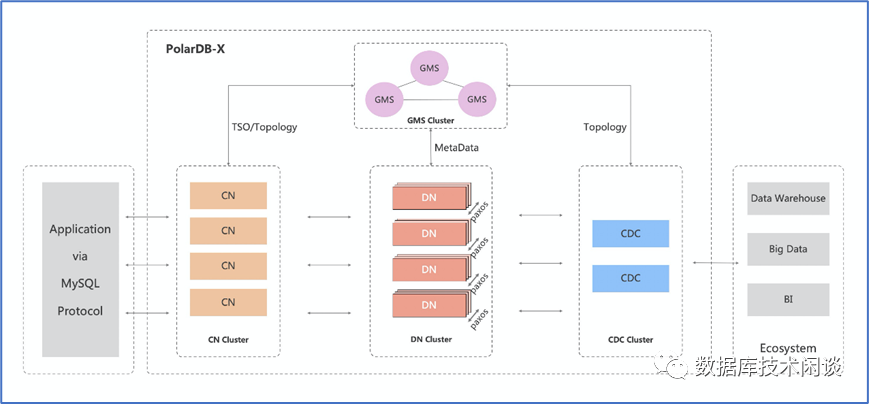
计算节点(CN, Compute Node)
计算节点是系统的入口,采用无状态设计,包括 SQL 解析器、优化器、执行器等模块。负责数据分布式路由、计算及动态调度,负责分布式事务 2PC 协调、全局二级索引维护等,同时提供 SQL 限流、三权分立等企业级特性。这里面比较特别的就是分布式事务和全局二级索引功能,这是早期DRDS产品的痛点。
存储节点(DN, Data Node)
存储节点负责数据的持久化,基于多数派 Paxos 协议提供数据高可靠、强一致保障,同时通过 MVCC 维护分布式事务可见性。这里面的特别之处应该就是使用Paxos协议实现MySQL的高可用。
元数据服务(GMS, Global Meta Service)
元数据服务负责维护全局强一致的 Table/Schema, Statistics 等系统 Meta 信息,维护账号、权限等安全信息,同时提供全局授时服务(即 TSO)。这个是 PolarDB-X 自己的元数据服务,包含分库分表规则和实例数据库信息。应用不需要再自己存储特殊的 jar 包了。
日志节点(CDC, Change Data Capture)
日志节点提供完全兼容 MySQL Binlog 格式和协议的增量订阅能力,提供兼容 MySQL Replication 协议的主从复制能力。这个也是很实用的功能,方便用户订阅PolarDB-X的日志(BINLOG),它实现了将后端MySQL的Binlog 根据一些事务规则聚合。
PolarDB-X Docker 部署总结
[root@sfx110008 ~]# source polardb/bin/activate(polardb) [root@sfx110008 ~]# python -VPython 3.7.6(polardb) [root@sfx110008 ~]#
(polardb) [root@sfx110008 ~]# pxd tryout/root/polardb/lib/python3.7/site-packages/deployerStart creating PolarDB-X cluster pxc-tryouton your local machinePolarDB-X Cluster params:* cncount: 1, version: latest* dncount: 1, version: latest*cdc count: 1, version: latest*gms count: 1, version: latest*leader_only: TrueProcessing[------------------------------------] 0% pre checkProcessing[##----------------------------------] 7% generate topologyProcessing[#####-------------------------------] 15% check docker engine versionProcessing[########----------------------------] 23% pull imagesPull image: polardbx/galaxysql:latest at127.0.0.1latest:Pulling from polardbx/galaxysqlDigest:sha256:dc48b544ccb12e14b8d40b5a5aa7445045ec5753809235a4320dde382106ac5bStatus: Image is up to date forpolardbx/galaxysql:latestPull image: polardbx/galaxyengine:latest at127.0.0.1latest:Pulling from polardbx/galaxyengineDigest:sha256:32fac0ec5bd03997e2fffc8829208e21f33e31124c7eecf7120f1eb491846d6cStatus: Image is up to date forpolardbx/galaxyengine:latestPull image: polardbx/polardbx-init:latestat 127.0.0.1latest:Pulling from polardbx/polardbx-initDigest:sha256:e2d7984f8a01845708eec86ef7d0168aa3b7cb8082040eb13e1c3160e0f799e3Status: Image is up to date forpolardbx/polardbx-init:latestPull image: polardbx/xstore-tools:latest at127.0.0.1latest:Pulling from polardbx/xstore-toolsDigest:sha256:914f44294bdcd5b141dbbdf2ce98dbeca42ed615fb9642dd1daebc3f98970620Status: Image is up to date forpolardbx/xstore-tools:latestPull image: polardbx/galaxycdc:latest at127.0.0.1latest:Pulling from polardbx/galaxycdcDigest:sha256:0ffe8a3ac06be9faed3cb27dbd0a736295292360817cc3c2610245b053a636a7Status: Image is up to date forpolardbx/galaxycdc:latestProcessing[###########-------------------------] 30% create gms nodeProcessing[#############-----------------------] 38% create gms db and tablesProcessing[################--------------------] 46% create PolarDB-X rootaccountProcessing[###################-----------------] 53% create dnProcessing[######################--------------] 61% register dn to gmsProcessing[########################------------] 69% create cnProcessing[###########################---------] 76% wait cn readyProcessing[##############################------] 84% create cdc containersProcessing[#################################---] 92% wait PolarDB-X readyProcessing[####################################] 100%PolarDB-X cluster create successfully, youcan try it out now.Connect PolarDB-X using the followingcommand:mysql -h127.0.0.1 -P59533 -upolardbx_root -plQgzQpWE
(polardb) [root@sfx110008 ~]# mysql-h127.0.0.1 -P59533 -upolardbx_root -plQgzQpWEmysql: [Warning] Using a password on thecommand line interface can be insecure.Welcome to the MySQL monitor. Commands end with ; or \g.Your MySQL connection id is 11Server version: 5.6.29 Tddl Server(ALIBABA)Copyright (c) 2000, 2021, Oracle and/or itsaffiliates.Oracle is a registered trademark of OracleCorporation and/or itsaffiliates. Other names may be trademarksof their respectiveowners.Type 'help;' or '\h' for help. Type '\c' toclear the current input statement.mysql> select user,host from mysql.user;+---------------+------+| user | host |+---------------+------+| polardbx_root | % |+---------------+------+1 row in set (0.05 sec)mysql> set PASSWORD FOR'polardbx_root'@'%' = PASSWORD('scaleFLUX2023') ;ERROR 5107 (HY000):[1597fedb36001000][172.17.0.4:59533][polardbx]ERR-CODE:[PXC-5107][ERR_OPERATION_NOT_ALLOWED] Can not modify polardbx_root since it isreserved for systemmysql>
(polardb) [root@sfx110008 ~]# pxd list/root/polardb/lib/python3.7/site-packages/deployerNAME CN DN CDC STATUSpxc-tryout 1 1 1 running(polardb) [root@sfx110008 ~]#
(polardb) [root@sfx110008 polardb-test]#cat polardb-x-sfx.yamlversion: v1type: polardbxcluster:name: pxcsfxgms:image: polardbx/galaxyengine:latesthost_group: [192.168.110.8]resources:cpu_limit: 4mem_limit: 4G cn:image: polardbx/galaxysql:latestreplica: 1nodes:- host: 192.168.110.8resources:cpu_limit: 36mem_limit: 96G dn:image: polardbx/galaxyengine:latestreplica: 2nodes:- host_group: [192.168.110.8]- host_group: [192.168.110.8]resources:cpu_limit: 24mem_limit: 48Gcdc:image: polardbx/galaxycdc:latestreplica: 1nodes:- host: 192.168.110.8resources:cpu_limit: 6mem_limit: 32G(polardb) [root@sfx110008 polardb-test]#
这里我部署了2个同等规格的 PolarDB-X 集群:pxcintel 和 pxcsfx ,主要是为了对比两块 SSD上的 PolarDB-X 性能。
(polardb) [root@sfx110008 polardb-test]#pxd list/root/polardb/lib/python3.7/site-packages/deployerNAME CN DN CDC STATUSpxcintel 1 2 1 runningpxcsfx 1 2 1 runningpxc-tryout 1 1 1 running(polardb) [root@sfx110008 polardb-test]#
注意,配置文件中各个容器需要的内存之和要小于服务器可用的内存。DN 节点里的 MySQL 使用的是文件系统,里面 MySQL 的日志会使用到 PageCache。所以后面会观察到内存有一部分在 PageCache 里。
默认 DN 和 GMS 节点的 MySQL 都是部署在当前用户 home 目录下隐藏文件夹 ~/.pxd/data 下,这个位置需要调整。由于没有找到在配置文件中指定目录的方式,我这里将 mysql 和 mysql_log 下面实例目录移动到 SSD 盘里,并使用软链接技术。
(polardb) [root@sfx110008 ~]# cd~/.pxd/data/(polardb) [root@sfx110008 data]# lltotal 16drwxr-xr-x3 root root 27 Jan 19 08:29cachedrwxr-xr-x4 root root 4096 Jan 28 10:26 mysqldrwxr-xr-x4 root root 4096 Jan 28 10:26 mysql_logdrwxr-xr-x 13 root root 4096 Jan 28 10:26podinfodrwxr-xr-x 10 root root 4096 Jan 28 10:26shareddrwxr-xr-x2 root root 28 Jan 19 08:35template(polardb) [root@sfx110008 data]#(polardb) [root@sfx110008 data]# ll mysql/total 0drwxr-xr-x 6 1000 1000 101 Jan 28 10:26127_0_0_1_14765drwxr-xr-x 6 1000 1000 101 Jan 28 10:25127_0_0_1_15598lrwxrwxrwx 1 root root 39 Jan 19 08:48 192_168_110_8_15285 ->/data/nvme0n1/mysql/192_168_110_8_15285lrwxrwxrwx 1 root root 39 Jan 19 08:45 192_168_110_8_15898 ->/data/nvme1n1/mysql/192_168_110_8_15898lrwxrwxrwx 1 root root 39 Jan 19 08:45 192_168_110_8_16176 ->/data/nvme1n1/mysql/192_168_110_8_16176lrwxrwxrwx 1 root root 39 Jan 19 08:48 192_168_110_8_16525 ->/data/nvme0n1/mysql/192_168_110_8_16525lrwxrwxrwx 1 root root 39 Jan 19 08:48 192_168_110_8_16890 ->/data/nvme0n1/mysql/192_168_110_8_16890lrwxrwxrwx 1 root root 39 Jan 19 08:45 192_168_110_8_17868 ->/data/nvme1n1/mysql/192_168_110_8_17868(polardb) [root@sfx110008 data]# llmysql_log/total 0drwxr-xr-x 3 root root 16 Jan 28 10:26127_0_0_1_14765drwxr-xr-x 3 root root 16 Jan 28 10:25127_0_0_1_15598lrwxrwxrwx 1 root root 43 Jan 19 08:47192_168_110_8_15285 -> data/nvme0n1/mysql_log/192_168_110_8_15285lrwxrwxrwx 1 root root 43 Jan 19 08:47192_168_110_8_15898 -> data/nvme1n1/mysql_log/192_168_110_8_15898lrwxrwxrwx 1 root root 43 Jan 19 08:47192_168_110_8_16176 -> data/nvme1n1/mysql_log/192_168_110_8_16176lrwxrwxrwx 1 root root 43 Jan 19 08:47192_168_110_8_16525 -> data/nvme0n1/mysql_log/192_168_110_8_16525lrwxrwxrwx 1 root root 43 Jan 19 08:47192_168_110_8_16890 -> data/nvme0n1/mysql_log/192_168_110_8_16890lrwxrwxrwx 1 root root 43 Jan 19 08:46192_168_110_8_17868 -> data/nvme1n1/mysql_log/192_168_110_8_17868(polardb) [root@sfx110008 data]#
其中 nvme0n1 是可计算存储。
(polardb) [root@sfx110008 data]# lsblk |grepnvmenvme0n1 259:1 0 3.5T 0 disk data/nvme0n1nvme1n1 259:0 0 3.5T 0 disk data/nvme1n1(polardb) [root@sfx110008 data]# nvme listNode SN Model NamespaceUsage Format FW Rev---------------- ------------------------------------------------------------ --------- ------------------------------------------ --------/dev/nvme0n1 UE2237C1501M CSD-3310 1 1.32 TB 3.84 TB 4 KiB + 0 B U3219118/dev/nvme1n1 BTAC14930A0A3P8AGN INTEL SSDPF2KX038TZ 1 3.84 TB 3.84 TB 4 KiB + 0 B JCV10100(polardb) [root@sfx110008 data]#
使用命令 docker stats 可以实时观察 docker容器的性能。这里主要是看看容器的内存资源规格。
(polardb) [root@sfx110008 data]# dockerstatsCONTAINER ID NAME CPU % MEM USAGE LIMIT MEM % NET I/O BLOCK I/O PIDS7a134a7f8819 pxc-tryout-cdc-YzFi 4.68% 1.418GiB 2GiB 70.90% 43.8MB 13MB 598kB227MB 448192d639dab9c pxc-tryout-cn-DRhz-59533 1.42% 1.734GiB 2GiB 86.72% 47.5MB 30.7MB 16.4kB 0B 2347b819ededc1 pxc-tryout-dn-0-Cand-14765 3.22% 918.1MiB 2GiB 44.83% 21.5MB 43.6MB 79MB6.08GB 1918910af8257e7 pxc-tryout-gms-Cand-15598 2.34% 900.2MiB 2GiB 43.96% 14.8MB 40.3MB 78.1MB 4.93GB 196528d02263414 pxcsfx-cdc-OuBg 5.81% 7.499GiB 32GiB 23.44% 0B 0B 0B 594kB 546d67c933141db pxcsfx-cn-rSAu-57751 2.85% 71.84GiB 96GiB 74.84% 0B 0B 0B 213kB 87eb75fd10e0c0 pxcsfx-dn-1-Cand-16890 7.14% 9.429GiB 48GiB 19.64% 0B 0B 1.28GB 95.9GB 193eaccd28a089a pxcsfx-dn-0-Cand-16525 7.56% 14.34GiB 48GiB 29.87% 0B 0B 1.25GB 157GB 19360f0ea52966d pxcsfx-gms-Cand-15285 2.67% 4GiB 4GiB 99.99% 0B 0B 5.68GB 50.8GB 197ae4fd818ab70 pxcintel-cdc-tzKD 0.30% 3.489GiB 32GiB 10.90% 0B 0B 164kB58.8MB 1341137dcdd007b pxcintel-cn-POfb-52289 1.48% 73.41GiB 96GiB 76.47% 0B 0B 49.2kB 123kB 872007f8324d48 pxcintel-dn-1-Cand-17868 0.88% 36.38GiB 48GiB 75.79% 0B 0B 16.9GB 112GB 1918c020d4b6a25 pxcintel-dn-0-Cand-15898 6.39% 42.45GiB 48GiB 88.44% 0B 0B 24.3GB 131GB 1929955e8db3b7c pxcintel-gms-Cand-16176 7.27% 3.845GiB 4GiB 96.13% 0B 0B 1.12GB 22.9GB 197^C
PolarDB-X OLTP 测试简介
分库分表介绍
分库类型
PolarDB-X 目前是2.0,保留了1.0的DRDS功能。PolarDB-X的目标是让用户像单实例一样使用数据库。首先进入 PolarDB-X 默认只有 information_schema 数据库。用户需要创建一个数据库。
命令:create database yourdb [ mode = ‘drds | auto’ ] ;
完整的语法见帮助文档。
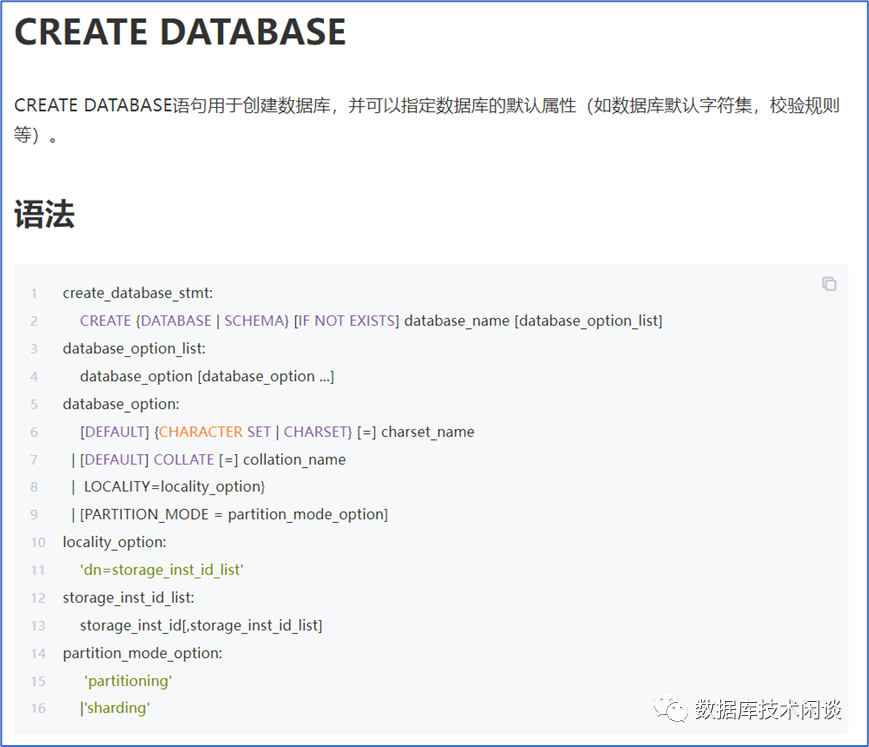
增加了 mode 选项,可以不提供,默认值看起来是 drds 。二者区别看后面分析。
mysql> create database testdb_default;Query OK, 1 row affected (0.47 sec)mysql> show databases;+--------------------+| DATABASE |+--------------------+| information_schema || testdb_default |+--------------------+2 rows in set (0.00 sec)
目前建好的数据库看起来跟单实例一样,我们倒后端 DN 节点的 MySQL 中看看数据库列表。
DN 节点容器名中的数字就是MySQL的监听端口,默认用户 root,密码空。只能本地登录。
[root@sfx110008 polardb-test]# docker exec -it pxc-tryout-dn-0-Cand-14765 bash[root@47b819ededc1 /]# mysql -h 127.1 -u root -P 14765 -pEnter password:Welcome to the MySQL monitor. Commands end with ; or \g.<…>mysql> show databases;+-----------------------+| Database |+-----------------------+| __cdc___000000 || __cdc___single || __recycle_bin__ || information_schema || mysql || performance_schema || sys || testdb_default_000000 || testdb_default_000001 || testdb_default_000002 || testdb_default_000003 || testdb_default_000004 || testdb_default_000005 || testdb_default_000006 || testdb_default_000007 || testdb_default_single |+-----------------------+16 rows in set (0.00 sec)
我们可以看到后端 DN 节点里跟 testdb_default 有关的数据库有9个,其中8个数据库名以数字结尾,从000000 到000007 ,我们简称为 testdb_default 的分库,最后一个以 single 结尾,简称为 testdb_default 的单库。目前数据库下都没有业务表。
这里有8个分库,应该是一个参数控制的,默认值是8 。深入使用 PolarDB-X 的时候,这个分库数量是有讲究的,这里初次使用就不展开了。8这个值挺好的。
我们回到 PolarDB-X 的会话中,继续建表。
mysql> use testdb_default;Database changedmysql> CREATE TABLE single_tbl(-> id bigint not null auto_increment,-> name varchar(30),-> primary key(id)-> );Query OK, 0 rows affected (0.85 sec)mysql> show tables;+--------------------------+| TABLES_IN_TESTDB_DEFAULT |+--------------------------+| single_tbl |+--------------------------+1 row in set (0.00 sec)mysql> show create table single_tbl \G*************************** 1. row ***************************Table: single_tblCreate Table: CREATE TABLE `single_tbl` (`id` bigint(20) NOT NULL AUTO_INCREMENT,`name` varchar(30) DEFAULT NULL,PRIMARY KEY (`id`)) ENGINE = InnoDB DEFAULT CHARSET = utf8mb4 DEFAULT COLLATE = utf8mb4_0900_ai_ci1 row in set (0.02 sec)
跟单实例建表看起来是一样的。
我们再看看后端DN节点中 MySQL 实例下的表。
mysql> show tables from testdb_default_000000;+---------------------------------+| Tables_in_testdb_default_000000 |+---------------------------------+| __drds_global_tx_log |+---------------------------------+1 row in set (0.00 sec)mysql> show tables from testdb_default_000007;+---------------------------------+| Tables_in_testdb_default_000007 |+---------------------------------+| __drds_global_tx_log |+---------------------------------+1 row in set (0.00 sec)mysql> show tables from testdb_default_single ;+---------------------------------+| Tables_in_testdb_default_single |+---------------------------------+| __drds_global_tx_log || single_tbl_gb4f |+---------------------------------+2 rows in set (0.00 sec)mysql> use testdb_default_single;Database changedmysql> show create table single_tbl_gb4f \G*************************** 1. row ***************************Table: single_tbl_gb4fCreate Table: CREATE TABLE `single_tbl_gb4f` (`id` bigint(20) NOT NULL AUTO_INCREMENT,`name` varchar(30) DEFAULT NULL,PRIMARY KEY (`id`)) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci1 row in set (0.00 sec)
从上看出只在单库下看到表 single_tbl,但是名字后面被自动追加了一个随机字符串后缀。这个估计是为了避免重名。表结构跟前面建表完全一样。
上面的表我建表时用自增列做了主键。如果建表不带主键,PolarDB-X 会在后端 MySQL 实例里自动给表加一个自增列作为主键。所以业务尽量创建主键,否则就不要在没有主键的时候创建自增列,在这里会报错。
mysql> CREATE TABLE single_tbl_no_pk( id bigint not null auto_increment, name varchar(30) );ERROR 4998 (HY000): [1598296a64c01000][172.17.0.4:59533][testdb_default]ERR-CODE: [PXC-4518][ERR_VALIDATE] ERR-CODE: [PXC-4998][ERR_NOT_SUPPORT] Incorrect table definition; there can be only one auto column and it must be defined as a key not support yet!mysql> CREATE TABLE single_tbl_no_pk( id bigint not null , name varchar(30) );Query OK, 0 rows affected (0.52 sec)mysql>
看一下后端表,验证一下这个结论。
mysql> show tables;+---------------------------------+| Tables_in_testdb_default_single |+---------------------------------+| __drds_global_tx_log || single_tbl_gb4f || single_tbl_no_pk_xrcv |+---------------------------------+3 rows in set (0.00 sec)mysql> show create table single_tbl_no_pk_xrcv\G*************************** 1. row ***************************Table: single_tbl_no_pk_xrcvCreate Table: CREATE TABLE `single_tbl_no_pk_xrcv` (`id` bigint(20) NOT NULL,`name` varchar(30) DEFAULT NULL,`_drds_implicit_id_` bigint(20) NOT NULL AUTO_INCREMENT,PRIMARY KEY (`_drds_implicit_id_`)) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci1 row in set (0.00 sec)mysql>
PolarDB-X 添加的自增列的名字叫 _drds_implicit_id_ ,所以业务列不要用这个名字。
截止目前这个表还是个普通表,我们简称为单表。单表通常是在单库(以 _single)结尾里。我们也可以在 PolarDB-X 的会话里通过命令 show topology 查看表的拓扑结构,通过命令 show rule 查看表的分库分表信息。
mysql> show topology from single_tbl;+------+-----------------------------+-----------------+----------------+| ID | GROUP_NAME | TABLE_NAME | PARTITION_NAME |+------+-----------------------------+-----------------+----------------+| 0 | TESTDB_DEFAULT_SINGLE_GROUP | single_tbl_GB4F | - |+------+-----------------------------+-----------------+----------------+1 row in set (0.00 sec)mysql> show rule;+------+------------------+-----------+------------------+---------------------+--------------------+------------------+---------------------+--------------------+| ID | TABLE_NAME | BROADCAST | DB_PARTITION_KEY | DB_PARTITION_POLICY | DB_PARTITION_COUNT | TB_PARTITION_KEY | TB_PARTITION_POLICY | TB_PARTITION_COUNT |+------+------------------+-----------+------------------+---------------------+--------------------+------------------+---------------------+--------------------+| 0 | single_tbl | 0 | | NULL | 1 | | NULL | 1 || 1 | single_tbl_no_pk | 0 | | NULL | 1 | | NULL | 1 |+------+------------------+-----------+------------------+---------------------+--------------------+------------------+---------------------+--------------------+2 rows in set (0.01 sec)
上面拓扑里的 GROUP_NAME 通常就对应后端的数据库(分库或单库),名字会在数据库名上加个后缀“_GROUP”。
从命令 show rule 可以看出,单表实际上就是单库单表,就是分库数量为1,分表数量也为1 。下面我们看看分表用法。
分表类型
分表指分库分表。一个逻辑表拆分为 M 个分库,每个分库下可以再拆分为 N 个分表。M,N >= 1,可以独立指定。M*N 就是这个逻辑表被拆分的分片数。前面介绍历史的时候说,淘宝交易表历史上最大拆分分片是4096,仅供参考。
分表语法就是普通建表语句后增加2个语法:dbpartition by 分库拆分策略(拆分字段) 、tbpartition by 分表拆分策略(拆分字段) 。
我们先从简单的情形开始,分库不分表,M=8, N=1 。
mysql> CREATE TABLE multi_db_single_tbl(-> id bigint not null auto_increment,-> name varchar(30),-> primary key(id)-> ) dbpartition by hash(id);Query OK, 0 rows affected (0.54 sec)mysql> show topology from multi_db_single_tbl ;+------+-----------------------------+--------------------------+----------------+| ID | GROUP_NAME | TABLE_NAME | PARTITION_NAME |+------+-----------------------------+--------------------------+----------------+| 0 | TESTDB_DEFAULT_000000_GROUP | multi_db_single_tbl_G7Uh | - || 1 | TESTDB_DEFAULT_000001_GROUP | multi_db_single_tbl_G7Uh | - || 2 | TESTDB_DEFAULT_000002_GROUP | multi_db_single_tbl_G7Uh | - || 3 | TESTDB_DEFAULT_000003_GROUP | multi_db_single_tbl_G7Uh | - || 4 | TESTDB_DEFAULT_000004_GROUP | multi_db_single_tbl_G7Uh | - || 5 | TESTDB_DEFAULT_000005_GROUP | multi_db_single_tbl_G7Uh | - || 6 | TESTDB_DEFAULT_000006_GROUP | multi_db_single_tbl_G7Uh | - || 7 | TESTDB_DEFAULT_000007_GROUP | multi_db_single_tbl_G7Uh | - |+------+-----------------------------+--------------------------+----------------+8 rows in set (0.00 sec)mysql> show rule from multi_db_single_tbl;+------+---------------------+-----------+------------------+---------------------+--------------------+------------------+---------------------+--------------------+| ID | TABLE_NAME | BROADCAST | DB_PARTITION_KEY | DB_PARTITION_POLICY | DB_PARTITION_COUNT | TB_PARTITION_KEY | TB_PARTITION_POLICY | TB_PARTITION_COUNT |+------+---------------------+-----------+------------------+---------------------+--------------------+------------------+---------------------+--------------------+| 0 | multi_db_single_tbl | 0 | id | hash | 8 | | NULL | 1 |+------+---------------------+-----------+------------------+---------------------+--------------------+------------------+---------------------+--------------------+1 row in set (0.00 sec)
建表时不需要指定分多少个库,实际会根据单个DN节点内部MySQL实例里的分库数定。从拓扑里看一个分成了8个分表,每个分库里有一个。再到后端验证一下。
mysql> show tables from testdb_default_000000;+---------------------------------+| Tables_in_testdb_default_000000 |+---------------------------------+| __drds_global_tx_log || multi_db_single_tbl_g7uh |+---------------------------------+2 rows in set (0.00 sec)mysql> show tables from testdb_default_000007;+---------------------------------+| Tables_in_testdb_default_000007 |+---------------------------------+| __drds_global_tx_log || multi_db_single_tbl_g7uh |+---------------------------------+2 rows in set (0.00 sec)mysql> show create table testdb_default_000005.multi_db_single_tbl_g7uh\G*************************** 1. row ***************************Table: multi_db_single_tbl_g7uhCreate Table: CREATE TABLE `multi_db_single_tbl_g7uh` (`id` bigint(20) NOT NULL AUTO_INCREMENT,`name` varchar(30) DEFAULT NULL,PRIMARY KEY (`id`)) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci1 row in set (0.00 sec)mysql> show tables from testdb_default_single ;+---------------------------------+| Tables_in_testdb_default_single |+---------------------------------+| __drds_global_tx_log || single_tbl_gb4f || single_tbl_no_pk_xrcv |+---------------------------------+3 rows in set (0.01 sec)
果然,分表只在分库里存在,且表结构一样。同样,创建分表如果不带主键,后端库里的分表会自动创建自增列做主键。这里不再验证。
接下来看分库分表,M=8, N>1 。
mysql> show topology from multi_db_multi_tbl ;+------+-----------------------------+---------------------------+----------------+| ID | GROUP_NAME | TABLE_NAME | PARTITION_NAME |+------+-----------------------------+---------------------------+----------------+| 0 | TESTDB_DEFAULT_000000_GROUP | multi_db_multi_tbl_buSd_0 | - || 1 | TESTDB_DEFAULT_000000_GROUP | multi_db_multi_tbl_buSd_1 | - || 2 | TESTDB_DEFAULT_000000_GROUP | multi_db_multi_tbl_buSd_2 | - || 3 | TESTDB_DEFAULT_000001_GROUP | multi_db_multi_tbl_buSd_0 | - || 4 | TESTDB_DEFAULT_000001_GROUP | multi_db_multi_tbl_buSd_1 | - || 5 | TESTDB_DEFAULT_000001_GROUP | multi_db_multi_tbl_buSd_2 | - || 6 | TESTDB_DEFAULT_000002_GROUP | multi_db_multi_tbl_buSd_0 | - || 7 | TESTDB_DEFAULT_000002_GROUP | multi_db_multi_tbl_buSd_1 | - || 8 | TESTDB_DEFAULT_000002_GROUP | multi_db_multi_tbl_buSd_2 | - || 9 | TESTDB_DEFAULT_000003_GROUP | multi_db_multi_tbl_buSd_0 | - || 10 | TESTDB_DEFAULT_000003_GROUP | multi_db_multi_tbl_buSd_1 | - || 11 | TESTDB_DEFAULT_000003_GROUP | multi_db_multi_tbl_buSd_2 | - || 12 | TESTDB_DEFAULT_000004_GROUP | multi_db_multi_tbl_buSd_0 | - || 13 | TESTDB_DEFAULT_000004_GROUP | multi_db_multi_tbl_buSd_1 | - || 14 | TESTDB_DEFAULT_000004_GROUP | multi_db_multi_tbl_buSd_2 | - || 15 | TESTDB_DEFAULT_000005_GROUP | multi_db_multi_tbl_buSd_0 | - || 16 | TESTDB_DEFAULT_000005_GROUP | multi_db_multi_tbl_buSd_1 | - || 17 | TESTDB_DEFAULT_000005_GROUP | multi_db_multi_tbl_buSd_2 | - || 18 | TESTDB_DEFAULT_000006_GROUP | multi_db_multi_tbl_buSd_0 | - || 19 | TESTDB_DEFAULT_000006_GROUP | multi_db_multi_tbl_buSd_1 | - || 20 | TESTDB_DEFAULT_000006_GROUP | multi_db_multi_tbl_buSd_2 | - || 21 | TESTDB_DEFAULT_000007_GROUP | multi_db_multi_tbl_buSd_0 | - || 22 | TESTDB_DEFAULT_000007_GROUP | multi_db_multi_tbl_buSd_1 | - || 23 | TESTDB_DEFAULT_000007_GROUP | multi_db_multi_tbl_buSd_2 | - |+------+-----------------------------+---------------------------+----------------+24 rows in set (0.01 sec)mysql> show rule from multi_db_multi_tbl ;+------+--------------------+-----------+------------------+---------------------+--------------------+------------------+---------------------+--------------------+| ID | TABLE_NAME | BROADCAST | DB_PARTITION_KEY | DB_PARTITION_POLICY | DB_PARTITION_COUNT | TB_PARTITION_KEY | TB_PARTITION_POLICY | TB_PARTITION_COUNT |+------+--------------------+-----------+------------------+---------------------+--------------------+------------------+---------------------+--------------------+| 0 | multi_db_multi_tbl | 0 | id | hash | 8 | bid | hash | 3 |+------+--------------------+-----------+------------------+---------------------+--------------------+------------------+---------------------+--------------------+1 row in set (0.01 sec)
最后我们来试试能不能不分库只分表,即M=1, N>1 。
mysql> CREATE TABLE single_db_multi_tbl( id bigint not null auto_increment, bid int, name varchar(30), primary key(id) ) tbpartition by hash(bid) tbpartitions 3;ERROR 4601 (HY000): [159830f976401000][172.17.0.4:59533][testdb_default]ERR-CODE: [PXC-4601][ERR_EXECUTOR] A single database shard with multiple table shards is not allowed in PolarDB-Xmysql>
看来是限制了不行,估计是为了管理方便。可以改为只分库不分表,也可以接受。
不过甲方用户也是能够决定产品的用法的。为了让用户用起来更方便,PolarDB-X推出自动分库分表功能。
自动分表
在创建数据库时,如果mode选项指定为 auto ,那又是另外一种形态。
mysql> create database testdb_auto mode='auto';Query OK, 1 row affected (0.07 sec)mysql> use testdb_auto;Database changedmysql> CREATE TABLE single_tbl( id bigint not null auto_increment,name varchar(30),primary key(id));Query OK, 0 rows affected (0.67 sec)mysql> show create table single_tbl \G*************************** 1. row ***************************TABLE: single_tblCREATE TABLE: CREATE TABLE `single_tbl` (`id` bigint(20) NOT NULL AUTO_INCREMENT,`name` varchar(30) DEFAULT NULL,PRIMARY KEY (`id`)) ENGINE = InnoDB DEFAULT CHARSET = utf8mb4 DEFAULT COLLATE = utf8mb4_0900_ai_ci1 row in set (0.01 sec)mysql> show topology from single_tbl ;+------+--------------------------+-----------------------+----------------+--------------------+-----------------+| ID | GROUP_NAME | TABLE_NAME | PARTITION_NAME | PHY_DB_NAME | DN_ID |+------+--------------------------+-----------------------+----------------+--------------------+-----------------+| 0 | TESTDB_AUTO_P00000_GROUP | single_tbl_BaPx_00000 | p1 | testdb_auto_p00000 | pxc-tryout-dn-0 || 1 | TESTDB_AUTO_P00000_GROUP | single_tbl_BaPx_00001 | p2 | testdb_auto_p00000 | pxc-tryout-dn-0 || 2 | TESTDB_AUTO_P00000_GROUP | single_tbl_BaPx_00002 | p3 | testdb_auto_p00000 | pxc-tryout-dn-0 || 3 | TESTDB_AUTO_P00000_GROUP | single_tbl_BaPx_00003 | p4 | testdb_auto_p00000 | pxc-tryout-dn-0 || 4 | TESTDB_AUTO_P00000_GROUP | single_tbl_BaPx_00004 | p5 | testdb_auto_p00000 | pxc-tryout-dn-0 || 5 | TESTDB_AUTO_P00000_GROUP | single_tbl_BaPx_00005 | p6 | testdb_auto_p00000 | pxc-tryout-dn-0 || 6 | TESTDB_AUTO_P00000_GROUP | single_tbl_BaPx_00006 | p7 | testdb_auto_p00000 | pxc-tryout-dn-0 || 7 | TESTDB_AUTO_P00000_GROUP | single_tbl_BaPx_00007 | p8 | testdb_auto_p00000 | pxc-tryout-dn-0 |+------+--------------------------+-----------------------+----------------+--------------------+-----------------+8 rows in set (0.00 sec)mysql> show rule from single_tbl ;+------+------------+-----------+------------------+---------------------+--------------------+------------------+---------------------+--------------------+| ID | TABLE_NAME | BROADCAST | DB_PARTITION_KEY | DB_PARTITION_POLICY | DB_PARTITION_COUNT | TB_PARTITION_KEY | TB_PARTITION_POLICY | TB_PARTITION_COUNT |+------+------------+-----------+------------------+---------------------+--------------------+------------------+---------------------+--------------------+| 0 | single_tbl | 0 | | | | id | KEY | 8 |+------+------------+-----------+------------------+---------------------+--------------------+------------------+---------------------+--------------------+1 row in set (0.00 sec)
从拓扑看,虽然建表没有指定分库分表语法,PolarDB-X 还是自动分了8个分表在一个分库里。从分库名字和分表名字推断,应该还有参数指定自动分库时默认分库数量和分表数量。
我们再看看后端 MySQL。
mysql> show databases;+-----------------------+| Database |+-----------------------+| __cdc___000000 || __cdc___single || __recycle_bin__ || information_schema || mysql || performance_schema || sys || testdb_auto_p00000 || testdb_default_000000 || testdb_default_000001 || testdb_default_000002 || testdb_default_000003 || testdb_default_000004 || testdb_default_000005 || testdb_default_000006 || testdb_default_000007 || testdb_default_single |+-----------------------+17 rows in set (0.00 sec)mysql> show tables from testdb_auto_p00000 ;+------------------------------+| Tables_in_testdb_auto_p00000 |+------------------------------+| __drds_global_tx_log || single_tbl_bapx_00000 || single_tbl_bapx_00001 || single_tbl_bapx_00002 || single_tbl_bapx_00003 || single_tbl_bapx_00004 || single_tbl_bapx_00005 || single_tbl_bapx_00006 || single_tbl_bapx_00007 |+------------------------------+9 rows in set (0.00 sec)mysql> use testdb_auto_p00000;Database changedmysql> show create table single_tbl_bapx_00000 \G*************************** 1. row ***************************Table: single_tbl_bapx_00000Create Table: CREATE TABLE `single_tbl_bapx_00000` (`id` bigint(20) NOT NULL AUTO_INCREMENT,`name` varchar(30) DEFAULT NULL,PRIMARY KEY (`id`)) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci1 row in set (0.00 sec)
索引表
分库分表架构早期有个痛点,就是不支持全局的二级索引。那个时候创建的二级索引都是每个分表上独立索引,没有办法形成一个整体索引。早期 DRDS 在支持这个功能的时候,先是让业务创建一个索引表充当这个作用,由业务去维护这个“索引表”和业务表的数据一致性。后来 DRDS 改为自己做索引表的数据同步(支持分布式事务)。目前看PolarDB-X ,这个索引的功能已经很完备和成熟了。用户在创建索引的时候感知不到后端有个索引表。
mysql> create index idx_name on single_tbl(name);Query OK, 0 rows affected (1.61 sec)mysql> show create table single_tbl \G*************************** 1. row ***************************TABLE: single_tblCREATE TABLE: CREATE TABLE `single_tbl` (`id` bigint(20) NOT NULL AUTO_INCREMENT,`name` varchar(30) DEFAULT NULL,PRIMARY KEY (`id`),INDEX `idx_name` (`name`)) ENGINE = InnoDB DEFAULT CHARSET = utf8mb4 DEFAULT COLLATE = utf8mb4_0900_ai_ci1 row in set (0.01 sec)mysql> show tables;+-----------------------+| TABLES_IN_TESTDB_AUTO |+-----------------------+| single_tbl |+-----------------------+1 row in set (0.01 sec)
不过我们使用 show topology 和 show rule 命令,还是能发现这个隐藏的细节。
mysql> show rule;+------+----------------+-----------+------------------+---------------------+--------------------+------------------+---------------------+--------------------+| ID | TABLE_NAME | BROADCAST | DB_PARTITION_KEY | DB_PARTITION_POLICY | DB_PARTITION_COUNT | TB_PARTITION_KEY | TB_PARTITION_POLICY | TB_PARTITION_COUNT |+------+----------------+-----------+------------------+---------------------+--------------------+------------------+---------------------+--------------------+| 0 | idx_name_$b02c | 0 | | | | name,id | KEY | 8 || 1 | single_tbl | 0 | | | | id | KEY | 8 |+------+----------------+-----------+------------------+---------------------+--------------------+------------------+---------------------+--------------------+2 rows in set (0.00 sec)mysql> show topology from idx_name_$b02c ;+------+--------------------------+---------------------------+----------------+--------------------+-----------------+| ID | GROUP_NAME | TABLE_NAME | PARTITION_NAME | PHY_DB_NAME | DN_ID |+------+--------------------------+---------------------------+----------------+--------------------+-----------------+| 0 | TESTDB_AUTO_P00000_GROUP | idx_name_$b02c_7gwU_00000 | p1 | testdb_auto_p00000 | pxc-tryout-dn-0 || 1 | TESTDB_AUTO_P00000_GROUP | idx_name_$b02c_7gwU_00001 | p2 | testdb_auto_p00000 | pxc-tryout-dn-0 || 2 | TESTDB_AUTO_P00000_GROUP | idx_name_$b02c_7gwU_00002 | p3 | testdb_auto_p00000 | pxc-tryout-dn-0 || 3 | TESTDB_AUTO_P00000_GROUP | idx_name_$b02c_7gwU_00003 | p4 | testdb_auto_p00000 | pxc-tryout-dn-0 || 4 | TESTDB_AUTO_P00000_GROUP | idx_name_$b02c_7gwU_00004 | p5 | testdb_auto_p00000 | pxc-tryout-dn-0 || 5 | TESTDB_AUTO_P00000_GROUP | idx_name_$b02c_7gwU_00005 | p6 | testdb_auto_p00000 | pxc-tryout-dn-0 || 6 | TESTDB_AUTO_P00000_GROUP | idx_name_$b02c_7gwU_00006 | p7 | testdb_auto_p00000 | pxc-tryout-dn-0 || 7 | TESTDB_AUTO_P00000_GROUP | idx_name_$b02c_7gwU_00007 | p8 | testdb_auto_p00000 | pxc-tryout-dn-0 |+------+--------------------------+---------------------------+----------------+--------------------+-----------------+8 rows in set (0.00 sec)
再查看一下后端表结构,就是包含主键和索引的字段。
mysql> use testdb_auto_p00000;Database changedmysql> show tables;+------------------------------+| Tables_in_testdb_auto_p00000 |+------------------------------+| __drds_global_tx_log || idx_name_$b02c_7gwu_00000 || idx_name_$b02c_7gwu_00001 || idx_name_$b02c_7gwu_00002 || idx_name_$b02c_7gwu_00003 || idx_name_$b02c_7gwu_00004 || idx_name_$b02c_7gwu_00005 || idx_name_$b02c_7gwu_00006 || idx_name_$b02c_7gwu_00007 || single_tbl_bapx_00000 || single_tbl_bapx_00001 || single_tbl_bapx_00002 || single_tbl_bapx_00003 || single_tbl_bapx_00004 || single_tbl_bapx_00005 || single_tbl_bapx_00006 || single_tbl_bapx_00007 |+------------------------------+17 rows in set (0.00 sec)mysql> show create table idx_name_$b02c_7gwu_00005 \G*************************** 1. row ***************************Table: idx_name_$b02c_7gwu_00005Create Table: CREATE TABLE `idx_name_$b02c_7gwu_00005` (`id` bigint(20) NOT NULL,`name` varchar(30) DEFAULT NULL,PRIMARY KEY (`id`),KEY `auto_shard_key_name` (`name`) USING BTREE) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci1 row in set (0.00 sec)
索引表只会在自动分库类型的数据库中存在,如果是DRDS那种手动分库类型里,通常不会有索引表。但是如果使用分区表且有索引时,也会自动创建索引表。
分区表
看到 PolarDB-X 支持分区表我还是有点意外。本来最早分库分表架构诞生的一个原因就是MySQL自身的分区表功能太弱性能太差。
不过 PolarDB-X 的分区表简单试了一下,跟 MySQL 分区表没有关系,其原理依然是分表技术。初步使用时还不明白为什么要有这个语法,可能也是被客户需求教育的。这里针对分区表就不深入探索了,感兴趣的直接查看帮助文档:https://docs.polardbx.com/dev-guide/topics/partition-syntax.html 。
分库分表如何决策
到目前我们已经看到 PolarDB-X 的分库分表的功能特点。分库分表技术诞生最早,也最容易被人理解接受。虽然自从有了 TiDB 不用分库分表的技术方案后,分库分表备受争议,不过这并不能抹灭这个架构的价值和存在的意义。从 PolarDB-X 的历史可知分库分表架构支撑了淘宝天猫多年的双十一大促,在大数据高并发情况下,加上3个以上的异地站点多活和单元化的苛刻需求,分库分表仍然是唯一可行的解决方案。原因可以参考《数据库的异地多活分析和方案》。目前市面上大部分分布式数据库的架构里还都有分库分表的影子,这也是一个证明。从 PolarDB-X 的产品文档里的SQL手册也可以看出推出了很多非标准SQL,但是都是用户真实的需求带来的 SQL,所以这个架构依然有着很强的生命力。
对于普通的用户来说,自动拆分、分库分表拆分和分区表拆分等技术都是工具。各个产品都在朝着让用户使用简单的方向发展。比如说对用户隐藏内部拆分细节、隐藏分布式事务细节。PolarDB-X 2.0 相比早期 DRDS,已经做到了这点,尽管跟其他竞品相比看起来并不“高端”。这里要说的是对用户简单,并不意味着事情就很简单,很多时候产品只是将复杂隐藏在内部(留给自己),把简单留给用户。在普通的业务场景下,简单总是更好一些。但是当业务要求变得不简单时,如大数据量、或高并发、或读写混合时,深入使用分布式数据库,想要保持高性能、高可靠时,DBA还是需要深入了解产品的内在原理,还是要去了解那些被隐藏的复杂细节。然后根据这个复杂的特点,引导业务做相应的优化。对于分布式拆分这个工具而言,不同工具特性原理有相同之处,也有不同之处。要最大化发挥分布式数据库的性能需要将数据的访问请求特点、SQL的执行计划和分布特点跟数据库存储节点数据存储特点三者保持一致或尽可能契合。阿里巴巴的异地多活单元化就是一个典范。有这样特点的业务并不仅此一家。还有火车票购票系统、证券交易所的交易、结算系统、券商的交易系统等等,都非常的有互联网特质(大数据,高并发,可拆分),并且特点还不一样,复杂不可怕,可怕的是不能掌控。到底哪个产品更适合自己的业务,还需要深入测试和分析。
单说 PolarDB-X,业务分库和分表又如何定呢。实际业务特点决定会存在一批表不能拆分,这些表就放到单库里以单表形式存在,最好是单独一个实例。其他可拆分的业务,根据业务模块再划分为多个实例然后单独拆分。不同业务的拆分的实例数、分库数不一定相同。同一个业务模块不同表的拆分字段尽可能相同。如果分库拆分字段不同,尽可能用不同实例的不同分库(建表可以指定使用哪些 DB GROUP或DN节点)。分表字段也可以不同,挑战是表关联。在PolarDB-X 里有一个特殊的表叫广播表,适合不能拆分的表,表数据量有一定规模,还会有变化但不是很频繁。这个表会被多个可拆分业务模块高度依赖,经常关联查询。那么建成广播表就可以将这个表的内容复制到多个分库中。这个数据同步是有PolarDB-X自动维护的。广播表的设计在OceanBase 里对应的方案是复制表,目的都是一样的,让关联查询尽可能在单个节点内部发生,减少跨节点的数据传输。从而提升数据库总体吞吐能力。这里就不深入展开了。
sysbench 使用介绍
观察一个分布式数据库除了看功能和跑简单的SQL外,还可以用 sysbench 做 OLTP 场景测试。sysbench 是开源项目,支持 MySQL、PG、ORACLE 等常用传统数据库连接。PolarDB-X兼容MySQL数据库,理论上也可以直接跑 sysbench。这里推荐 PolarDB 团队提供的 sysbench ,里面增加了很多场景测试语句。阿里云上官方给出 PolarDB-X的sysbench 测试实践,具体请参考 https://help.aliyun.com/document_detail/405017.html ,这里也不一一展示了。
我测试了DRDS那种分库分表的用法,也测试了自动分库的用法。下面是sysbench建表,使用DRDS 那种分库类型。
sysbench --db-driver=mysql --mysql-host=192.168.110.8 --mysql-port=61074 --mysql-user=sbtest --mysql-password='scaleflux' --mysql-db=sysbenchdb --table-size=100000000 --tables=20 --threads=20 --time=120 --events=0 --report-interval=60 --percentile=99 --create_table_options='dbpartition by hash(`id`) tbpartition by hash(id) tbpartitions 4' --create_secondary=true oltp_read_only.lua run
在实际sysbench 初始化和测试之前,先设置一组PolarDB-X 参数,这都是为了避免后面各种报错或者提升性能的。这些参数就不一一解释了。具体参数可以查看:https://docs.polardbx.com/maintance/topics/cn-variables.html 。
下面参数在PolarDB-X 实例中设置:
set global CONN_POOL_MIN_POOL_SIZE=50;set global CONN_POOL_XPROTO_MAX_POOLED_SESSION_PER_INST=1000;set global XPROTO_MAX_DN_CONCURRENT=4000;set global XPROTO_MAX_DN_WAIT_CONNECTION=4000;set global RECORD_SQL = false;set global ENABLE_CPU_PROFILE = false;set global GROUP_PARALLELISM = 1;set global SHARE_READ_VIEW = false;set global CONN_POOL_XPROTO_XPLAN = false;set global NEW_SEQ_GROUPING_TIMEOUT=30000;set global MAX_SESSION_PREPARED_STMT_COUNT=1000;set global sync_binlog=0;set global innodb_flush_log_at_trx_commit=0;
下面参数在后端DN节点的MySQL实例中设置:
set global binlog_expire_logs_seconds=10800;set global sync_binlog=0;set global innodb_flush_log_at_trx_commit=0;
注意,上面为了提升数据初始化速度,将 MySQL 的Redo 和 binlog 日志都设置为不实时落盘。当数据初始化完成后 做性能测试的时候,为了对比 PolarDB-X 在 CSD 和普通 SSD 上性能差异,还是会将两个落盘参数改回1 。
此外,sysbench 默认是初始完数据后再创建索引,虽然指定了20个并行,后来发现到索引创建这个环节,创建索引是串行执行的。这导致后面的很多索引创建任务最终都超时退出了。也许有个超时参数可以规避这个问题,不过我选择修改 oltp_common.lua 脚本,把索引创建语句移到数据初始化之前了(空表的时候建索引)。这样规避了报错,只是数据初始化时间变长了一倍多。这是一个经验,不一定非要这样。
sysbench 数据存储成本分析
这一节主要分析 sysbench 数据在可计算存储上的成本。
sysbench 提供了列的字符串的生成参数,在 oltp_common.lua 文件中,默认 sysbench 数据都是随机字符串。通常随机字符串也可以压缩,使用gzip算法时,压缩比大概在1.4 左右(这是不严谨的估算)。阿里云 PolarDB MySQL 业务的数据放在可计算存储 CSD2000 产品上压缩比大概在 2.4~4.0 ,不同业务数据压缩比会略有不同。为了让 sysbench 测试尽可能接近实际业务,我对 oltp_common.lua 脚本做了一些修改,使得生成的数据不是那么的完全随机,从而让整个数据压缩比提升到合理水平。
vim /usr/local/share/sysbench/oltp_common.lua:set nu176 -- Template strings of random digits with 11-digit groups separated by dashes177178 -- 10 groups, 119 characters179 local c_value_template = "0000000000#-0000000000#-0000000000#-" ..180 "0000000000#-0000000000#-012345#####-" ..181 "###########-###########-###########-" ..182 "###########"183184 -- 5 groups, 59 characters185 local pad_value_template = "0000000000#-0000000000#-0000000000#-" ..186 "012########-###########"187
50表总共50亿记录,数据目录大概 1.4 TiB左右。
[root@sfx110008 polardb-test]# df -h |grep nvme/dev/nvme1n1 3.5T 1.4T 1.9T 43% /data/nvme1n1/dev/nvme0n1 3.5T 1.4T 2.0T 41% /data/nvme0n1
CSD3000 实际NAND物理容量大概使用 578GB 左右。
[root@sfx110008 polardb-test]# nvme listNode SN Model Namespace Usage Format FW Rev---------------- -------------------- ---------------------------------------- --------- -------------------------- ---------------- --------/dev/nvme0n1 UE2237C1501M CSD-3310 1 547.06 GB / 3.84 TB 4 KiB + 0 B U3219118/dev/nvme1n1 BTAC14930A0A3P8AGN INTEL SSDPF2KX038TZ 1 3.84 TB / 3.84 TB 4 KiB + 0 B JCV10100
sysbench数据在CSD3000上数据压缩比大概在2.75 左右。
[root@sfx110008 polardb-test]# sfx-statusSFX card: /dev/nvme0n1PCIe Vendor ID: 0xcc53PCIe Subsystem Vendor ID: 0xcc53Manufacturer: ScaleFluxModel: CSD-3310Serial Number: UE2237C1501MOPN: CSDU5SPC38M1Drive Type: U.2-VFirmware Revision: U3219118Temperature: 36 CPower Consumption: 10956 mWAtomic Write mode: ONPercentage Used: 1%Data Read: 133657 GiBData Written: 324914 GiBCorrectable Error Cnt: 0Uncorrectable Error Cnt: 0PCIe Link Status: Speed 16GT/s, Width x4PCIe Device Status: GoodFormatted Capacity: 3840 GBProvisioned Capacity: 3840 GBCompression Ratio: 275%Physical Used Ratio: 14%Free Physical Space: 3292 GBRSA Verify: OFFAES Encryption: OFFIO Speed: NormalCritical Warning: 0[root@sfx110008 polardb-test]#
当反复初始化和压测数据后,将 CSD 和 SSD 的逻辑容量所有地址(LBA)都写过一轮后,CSD3000 的 NAND 物理使用容量维持在 1.32 TB 左右,压缩比在 2.28 左右。
[root@sfx110008 polardb-test]# nvme listNode SN Model Namespace Usage Format FW Rev---------------- -------------------- ---------------------------------------- --------- -------------------------- ---------------- --------/dev/nvme0n1 UE2237C1501M CSD-3310 1 1.32 TB / 3.84 TB 4 KiB + 0 B U3219118/dev/nvme1n1 BTAC14930A0A3P8AGN INTEL SSDPF2KX038TZ 1 3.84 TB / 3.84 TB 4 KiB + 0 B JCV10100
这里对 SSD 挂载文件系统时没有指定 discard 选项,所以删除文件时SSD里NAND使用空间不会释放。严格来说有点浪费SSD物理空间,不过大部分用户都是这么简单使用SSD的。
[root@sfx110008 polardb-test]# cat /etc/fstab |grep nvme/dev/nvme0n1 /data/nvme0n1 ext4 nodelalloc,defaults,noatime 0 0/dev/nvme1n1 /data/nvme1n1 ext4 nodelalloc,defaults,noatime 0 0
此时测试 sysbench OLTP 场景比较接近生产环境(SSD 写过一段时间后接近稳态),其结果可以作为 CSD3000 替换普通SSD的参考。
sysbench 测试问题
基本上每个国产数据库在初次使用的时候,面对sysbench 大数据量高并发压测的时候,都会问题频发。首要原因就是产品的测试文档对于测试资源的要求不明确或者解释的不明确,对于参数的调优说的太少或者太简单。当你熬过这个阶段后,对这个数据库的理解肯定会有显著的进步。虽然我对 DRDS 产品有一些了解,在面临 PolarDB-X 时,测试还是会碰到连接问题、SQL 超时问题、死锁等等问题。能通过搜索文档解决一部分,还有一部分是要咨询原厂研发才能解决。
首先是连接问题。
连接问题
问题1:连接 prepare 问题。
FATAL: mysql_stmt_prepare() failedFATAL: MySQL error: 0 "[15839d19e4401002][192.168.110.8:61074][sysbenchdb]Can't create more than max_prepared_stmt_count statements in one session (current value: 100)"FATAL: `thread_init' function failed: ./oltp_common.lua:298: SQL API errorFATAL: mysql_stmt_prepare() failed
sysbench 默认运行测试的时候,会自动发起 prepare 语句。并发高的时候 prepare 会话可能超出一个 PolarDB-X 会话(应用到CN节点的会话)允许的限制。
解决方法一是修改参数 MAX_SESSION_PREPARED_STMT_COUNT 值。这里麻烦的是看不到这个参数的默认值是多少,即使自己设置了,也查不到它的值(也可能是我没找到方法)
mysql> set global MAX_SESSION_PREPARED_STMT_COUNT=512;Query OK, 0 rows affected (0.01 sec)
方法二就是 sysbench 带上参数 --db-ps-mode=disable 直接关闭 prepare 省事。
问题2:不能创建连接。
sysbench 的threads 指定的过高时可能会碰到无法创建连接的报错。这个报错原因可能是来自 CN 节点的设置,也可能是来自后端 DN 节点(MySQL)的设置。由于一个逻辑库后面对应16个分库(我这里有2个DN节点),所以一个客户端连接有可能会导致后端增加16个连接。
sysbench 跟 PolarDB-X 的CN节点之间的连接是短连接,CN 响应客户端请求时内部有维护一个连接池,并通过参数
CONN_POOL_MIN_POOL_SIZE、XPROTO_MAX_DN_CONCURRENT、 XPROTO_MAX_DN_WAIT_CONNECTION、CONN_POOL_XPROTO_MAX_POOLED_SESSION_PER_INST 等参数控制这个连接池的行为。CN节点跟DN节点的连接也受 DN 节点MySQL自身的连接参数限制。不过由于这个后端连接是PolarDB-X 自定义协议(RPC协议)的连接,看起来这个连接数是受 MySQL 的参数 mysqlx_max_connections 限制。这些参数都需要相应的调大。
此外,当sysbench的连接执行的是写操作时,后端 DN 节点上还会出现相应的由CDC发起的会话(可能是在获取DN节点 MySQL 的 binlog 增量),这部分会话数量也随着压测会话数增长而增长。所以我也没有知道精确计算这些参数的方法。只要把CN节点并发连接数设置的够大(比如说 2000),后端DN节点 mysql 的 mysqlx_max_connections 设置到 8000 以上。那么理论上 sysbench 压测 1000个并发至少不会碰到连接报错问题。
PolarDB-X的连接和会话是分离的,客户端发起多少个连接,并不意味着就会有多少个会话去执行请求,而是会从一个池子里取获取可用的会话去相应请求。如果没有就会排队等待,直到等待超时。所以连接报错也不一定是立即就出现的。
以上的分析是根据仅有的文档描述猜测的,对于连接和会话的概念并没有严格区分,不排除有可能理解错了。但解决方法大体不差。
PolarDB-X 也提供了几个有用的命令诊断连接问题。
命令 show ds 用于查看各个分库简单信息。
mysql> show databases;+--------------------+| DATABASE |+--------------------+| information_schema || sysbenchdb || sysbenchdb_auto |+--------------------+3 rows in set (0.00 sec)mysql> show ds;+------+-----------------+--------------------+---------------------------------+------------------------+---------+| ID | STORAGE_INST_ID | DB | GROUP | PHY_DB | MOVABLE |+------+-----------------+--------------------+---------------------------------+------------------------+---------+| 0 | pxcintel-gms | information_schema | INFORMATION_SCHEMA_SINGLE_GROUP | polardbx_info_schema | 0 || 1 | pxcintel-dn-0 | sysbenchdb | SYSBENCHDB_000000_GROUP | sysbenchdb_000000 | 1 || 2 | pxcintel-dn-1 | sysbenchdb | SYSBENCHDB_000001_GROUP | sysbenchdb_000001 | 1 || 3 | pxcintel-dn-0 | sysbenchdb | SYSBENCHDB_000002_GROUP | sysbenchdb_000002 | 1 || 4 | pxcintel-dn-1 | sysbenchdb | SYSBENCHDB_000003_GROUP | sysbenchdb_000003 | 1 || 5 | pxcintel-dn-0 | sysbenchdb | SYSBENCHDB_000004_GROUP | sysbenchdb_000004 | 1 || 6 | pxcintel-dn-1 | sysbenchdb | SYSBENCHDB_000005_GROUP | sysbenchdb_000005 | 1 || 7 | pxcintel-dn-0 | sysbenchdb | SYSBENCHDB_000006_GROUP | sysbenchdb_000006 | 1 || 8 | pxcintel-dn-1 | sysbenchdb | SYSBENCHDB_000007_GROUP | sysbenchdb_000007 | 1 || 9 | pxcintel-dn-0 | sysbenchdb | SYSBENCHDB_000008_GROUP | sysbenchdb_000008 | 1 || 10 | pxcintel-dn-1 | sysbenchdb | SYSBENCHDB_000009_GROUP | sysbenchdb_000009 | 1 || 11 | pxcintel-dn-0 | sysbenchdb | SYSBENCHDB_000010_GROUP | sysbenchdb_000010 | 1 || 12 | pxcintel-dn-1 | sysbenchdb | SYSBENCHDB_000011_GROUP | sysbenchdb_000011 | 1 || 13 | pxcintel-dn-0 | sysbenchdb | SYSBENCHDB_000012_GROUP | sysbenchdb_000012 | 1 || 14 | pxcintel-dn-1 | sysbenchdb | SYSBENCHDB_000013_GROUP | sysbenchdb_000013 | 1 || 15 | pxcintel-dn-0 | sysbenchdb | SYSBENCHDB_000014_GROUP | sysbenchdb_000014 | 1 || 16 | pxcintel-dn-1 | sysbenchdb | SYSBENCHDB_000015_GROUP | sysbenchdb_000015 | 1 || 17 | pxcintel-dn-0 | sysbenchdb | SYSBENCHDB_SINGLE_GROUP | sysbenchdb_single | 0 || 18 | pxcintel-dn-0 | sysbenchdb_auto | SYSBENCHDB_AUTO_P00000_GROUP | sysbenchdb_auto_p00000 | 1 || 19 | pxcintel-dn-1 | sysbenchdb_auto | SYSBENCHDB_AUTO_P00001_GROUP | sysbenchdb_auto_p00001 | 1 |+------+-----------------+--------------------+---------------------------------+------------------------+---------+20 rows in set (0.00 sec)
要看具体的连接池信息,还要切换到对应的数据库下。
mysql> use sysbenchdb_auto;Database changedmysql> show datasources \G*************************** 1. row ***************************ID: 0SCHEMA: sysbenchdb_auto@pxcintelNAME: dskey_sysbenchdb_auto_p00000_group#pxcintel-dn-0#192.168.110.8-15898#sysbenchdb_auto_p00000_48GROUP: SYSBENCHDB_AUTO_P00000_GROUPURL: X://admin@192.168.110.8:43898/sysbenchdb_auto_p00000?connectTimeout=5000&characterEncoding=utf8mb4&socketTimeout=900000USER: adminTYPE: xdbINIT: 0MIN: 32MAX: 32768IDLE_TIMEOUT: 60MAX_WAIT: 5000ON_FATAL_ERROR_MAX_ACTIVE: 4000MAX_WAIT_THREAD_COUNT: 8000ACTIVE_COUNT: 0POOLING_COUNT: 41ATOM: dskey_sysbenchdb_auto_p00000_group#pxcintel-dn-0#192.168.110.8-15898#sysbenchdb_auto_p00000READ_WEIGHT: 10WRITE_WEIGHT: 10STORAGE_INST_ID: pxcintel-dn-0
如果分库类型是 DRDS 模式,每个数据库后端会对应16个分库(这里是2个 DN 节点),这个会输出很多记录。每个分库的连接池信息在这里面都有体现,只是修改这个连接池就要靠CN节点提供的参数。具体哪个参数的修改会影响到这里面的各个字段,还需要深入测试分析。这里也不展开了。
关于连接数还有个规律。如果要并发连接数尽可能的高,那么单个连接的 SQL 执行时间就要尽可能的短。对于PK查询和更新,1000 个并发更新引发的后端会话数可能也就 1000出头(还有部分CDC会话),但是如果跑的是 oltp_read_only 场景,涉及到复杂的SQL时,则每个DN节点上后端连接数可能就到了 8000 左右了。所以连接报错问题也看当前连接数规模以及SQL平均执行时间。如果本身连接数规模已经很大了,那优化方向首先应该是SQL性能优化。
DDL问题
sysbench 初始化数据集默认是表数据加载完毕再创建二级索引。当分库类型是自动分库时,PolarDB-X 会创建独立的索引表去模拟“索引”的功能,所以这个会分批次抽取所有分表的数据,在 CN 节点内部重新排序,然后再写入索引表。这个过程也比较久。同时看起来好像每一时刻,数据库下只能有一个DDL会话(这点文档里没有说明,是我猜测的。如果不对,欢迎指出),导致很多索引创建会话排队等待超时最终报错。说起分布式数据库的DDL串行执行,在其他分布式数据库里我也看到过。推测DDL涉及到元数据的变更,可能会导致数据库内部相关 cache 失效,可能对分布式数据库性能稳定性影响比较大,所以分布式数据库先采用串行执行。
这个问题通过修改 oltp_common.lua 脚本,将索引放到建表语句中绕过。代价就是数据初始化变慢了。
PolarDB-X 比较友好的地方是提供了命令取查看 DDL 的状态和结果。
命令:show ddl result 用于查看当前数据库下的 DDL 线程结果。
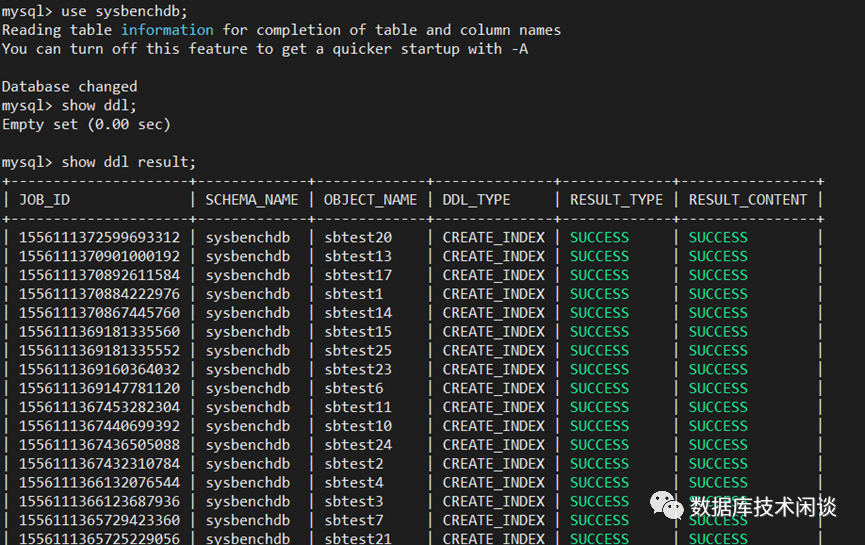
命令 show ddl 可以查看正在运行的 DDL。如果SQL执行比较快,这里可能看不到。正常情况下 PolarDB-X 一个DDL 执行时间在毫秒级别。如果是建空表或删除表长期不结束,那可能有别的原因。
如果 DDL 出现报错,会在这里显示。此时可以选择用命令是继续 RECOVER DDL 还是回滚 ROLLBACK DDL。没有这个功能的时候,DDL 也是分库分表的一个痛点,尤其是部分分库执行成功部分失败时,需要 DBA 挨个去检查 并修补。
死锁问题
首先要理解,死锁问题通常应用的事务设计问题。两个不同业务事务,按相反的顺序锁定了相关记录,导致数据库发生死锁。MySQL 在 RR 隔离级别下单表 DML 也可能会发生死锁。这种就按 MySQL 的解决方法去排查。在分布式数据库里,死锁涉及到多个 DN 节点上的事务,情形更复杂。
PolarDB-X 提供了命令 show deadlock 查看死锁。并且区分是 DN 节点本地死锁还是所有 DN 节点间的全局死锁。
分布式死锁的探测技术门槛比较高,支持这个的分布式数据库并不多。不过我这里没有展开测试分布式死锁案例。
SQL 性能问题
SQL 执行慢时,CN 节点和 DN 节点的连接数都可能会上涨,服务器压力也增加。此时首先要排查慢 SQL。单实例MySQL 里可以看慢查日志,在分布式MySQL里,后端MySQL 太多,挨个排查效率不高。PolarDB-X 提供命令 show slow 用于查看慢SQL。
mysql> show slow;+------------------+--------+---------------+------------+---------------------+--------------+------------+-------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+| TRACE_ID | USER | HOST | DB | START_TIME | EXECUTE_TIME | AFFECT_ROW | SQL |+------------------+--------+---------------+------------+---------------------+--------------+------------+-------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+| 15986b09ab001002 | sbtest | 192.168.110.8 | sysbenchdb | 2023-01-28 18:25:23 | 2875 | 0 | CREATE TABLE sbtest20( id INTEGER NOT NULL, k INTEGER DEFAULT '0' NOT NULL, c CHAR(120) DEFAULT '' NOT NULL, pad CHAR(60) DEFAULT '' NOT NULL, PRIMARY KEY (id) ) /*! ENGINE = innodb */ || 15986b0a2c801000 | sbtest | 192.168.110.8 | sysbenchdb | 2023-01-28 18:25:23 | 2710 | 0 | CREATE INDEX k_16 ON sbtest16(k) || 15986b0b47001000 | sbtest | 192.168.110.8 | sysbenchdb | 2023-01-28 18:25:24 | 2612 | 0 | CREATE INDEX k_11 ON sbtest11(k)<…>| 15986d2852801000 | sbtest | 192.168.110.8 | sysbenchdb | 2023-01-28 18:34:37 | 1007 | 0 | CREATE TABLE sbtest26( id INTEGER NOT NULL, k INTEGER DEFAULT '0' NOT NULL, c CHAR(120) DEFAULT '' NOT NULL, pad CHAR(60) DEFAULT '' NOT NULL, PRIMARY KEY (id) ) /*! ENGINE = innodb */ |+------------------+--------+---------------+------------+---------------------+--------------+------------+-------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+63 rows in set (0.03 sec)
命令 clear slow 清除上次慢SQL结果。
命令 trace SQL 可以跟踪特定SQL。命令 show trace 可以显示最近一次SQL跟踪结果。
命令show [full] trans 可以查看当前事务。目前信息还比较少,期待以后能完善。
命令 explain [detail | execute ] SQL 可以查看SQL执行计划,或者查看后端 DN 节点上该 SQL 的执行计划。不过后端DN节点上的 SQL 不一定跟实际SQL完全一样。CN 节点在SQL 解析时可能会做对SQL条件进行拆分、裁剪或聚合等,这考验的是 PolarDB-X SQL引擎的能力。而这个一直都是产品后期发展的主要方向(要支持HTAP复杂场景)。
sysbench在可计算存储上测试结论
最后简单说明一下对比测试的信息。sysbench 50 表,总共 50 亿数据,两个 PolarDB-X 集群,DN 节点数据分别存储在 CSD3000 和 P5510 上。CSD3000 上的 PolarDB-X 集群先后重建两次,区别在于第二次重建的时候,将文件系统格式化重新挂载,启用 ext4 bigalloc特性,支持16KB IO,同时关闭DN节点的MySQL的原子写(参数 innodb_doublewrite)。CSD3000 默认开启了原子写功能,支持 4KB~128KB IO 的原子写。
观察 sysbench 在不同并发下的吞吐QPS和相应的平均延时RT。
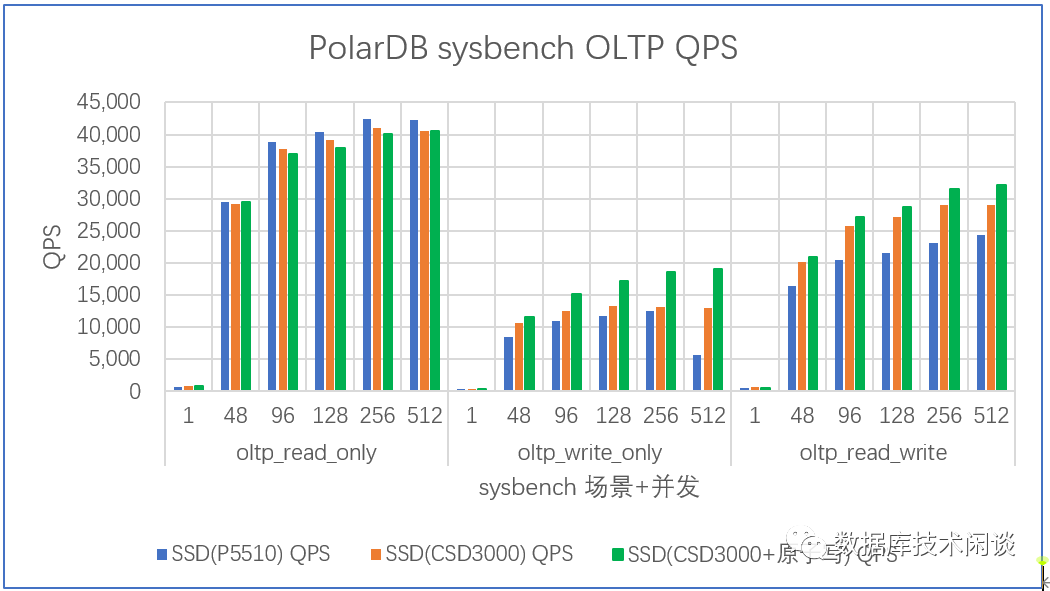
QPS 对比如下:
RT对比如下:
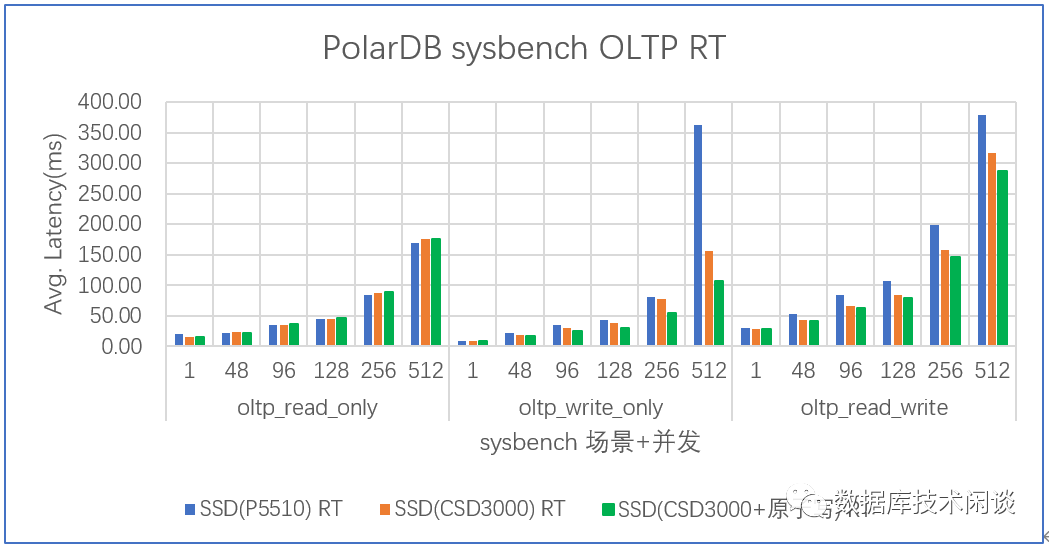
从这个测试结果上可以看,在只读场景里,CSD3000 相比 P5510 并没有太大优势,但是在写场景里,CSD3000 上 PolarDB-X 性能会有提升。尤其是在延时方面会更低一些。关闭 MySQL 双写启用 CSD3000 原子写的性能有提升,但幅度看起来没有 MySQL 单实例测试那么大。
总体来说 PolarDB-X 部署在 CSD3000 在读写方面有一些性能提升,幅度不是特别大。不过部署在 CSD3000上实际并发数还可以再高一些。
数据库性能测试有很大的不确定性。数据量、并发数、内存大小等,以及服务器负载等等。这次测试并没有把服务器 CPU 利用率压测到 80%以上,主要是 PolarDB-X 实例参数方面可能还不是最优的,有些稳定性问题还不知道原因导致压测并发上不去。此外就是计算和存储节点没有分离部署。
不过数据压缩比倒是接近线上业务数据压缩比,在这样的压缩比下,同等物理容量的 CSD3000 相比普通的 SSD 能节省近 57% 的闪存容量。反过来对 CSD3000 进行 2倍 扩容使用(3.84 T 盘当 7.68 T盘用)时,跟普通 SSD 相比,依然能节省很多闪存容量,同时在部分场景依然有不同程度的性能提升。这就是可计算存储降本增效的原理。
更多阅读
说说数据库事务和开发(下)—— 分布式事务 (注:PolarDB-X 已经支持分布式事务,默认对用户透明,隐藏了分布式事务细节。)
