




OceanBase存储 LSM-Tree
当下更多较新的数据库选择LSM-Tree作为存储结构,包括OceanBase、Leveldb、Cassandra、MyRocks(RocksDB)、TiDB(RocksDB)都是以LSM-Tree作为存储结构实现的存储引擎,本文对是在学习OB中关于存储引擎的一些总结,先LSM-Tree做个介绍,逐步延展到OceanBase内存及转储/合并管理
LSM-Tree简介
对于数据库IO密集型应用,有着各种优化方式去减少对磁盘的开销,例如:buffer , Redo顺序写、Inster Buffer等,能充分发挥出磁盘的优势是关键,对于磁盘的顺序写性能要好于随机写,尤其是在HDD时代IOPS只有一百出头,但是吞吐可以到200多MB/s,LSM-Tree与B-Tree核心的区别是将随机写转化为顺序写
LSM每次都通过Append方式进行写入,这种方式可以很大程度提升了写入性能,RocksDB是以LSM-Tree实现的存储引擎,从图中看到数据写入先写到内存中Memtable,当Memtable满后会生成一个新的Memtable,将满的Memtable刷新到磁盘中的SST file中,SST file是一种分层结构,每层存储多个SST file。
L0层为最高层存储最新的数据,Ln为最低层存储版本最老的数据 ,每层存储数据大小逐层增加

LSM-Tree写优势明显,但对于读性能是有影响,因为每一次都是Append方式写入,删除和修改也是插入,可能要查询的数据版本比较老,查询时访问的数据在内存中不能命中,这时就需要访问SST file,极端情况下可能会访问多层中的多个SST file这就放大了读。并且Append方式写入对空间也是一种放大,存在大量无效的数据。因此LSM-Tree中最重要一点就是Compaction操作,对文件做合并减少读放大和空间放大
我们可以总结出LSM-Tree中三个"放大":
- 读放大: 读取的数据量/实际返回的数据量
扫描的数据大于返回的行数,向上面提到那样查询可能会访问多个SST file,造成扫描的数据增加,读IO被放大 - 空间放大: 存储的数据量/实际存在的数据量
由于数据Append方式写入,过期的数据可能未及时清理,造成存储数据量>实际存在的数据量 - 写放大: 磁盘的写入量/实际的写入量
一次写入的可能会触发Compaction,造成写IO被放大
Compaction算法
Compaction就是在上面提到这三点中追求平衡,常见的Compaction算法有几种:
-
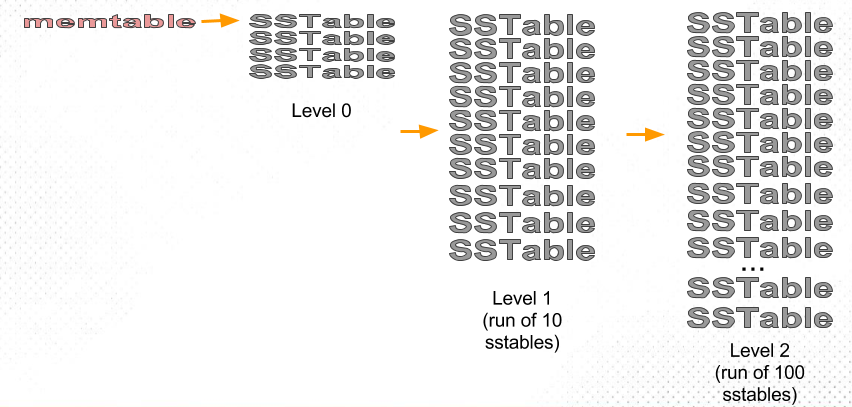
Classic Leveled
Leveled算法下每一层都是独立的"Sorted Run" ,代表是按Key排序且同层SST file之间的Key值没有重合,数量大小是逐层增大。相邻的两层SST file比称之为fanout(扇出),每次做Compaction的条件是Ln层大小达到了阈值,将Ln层数据与Ln-1层数据进行合并。- 空间放大:
a. 最好情况:假设Level之间SST file大小倍数是10,L1层10个SST file ,L2层100个SST file,L3层1000个SSTfile(全部都写满),因为L3层是一个Run(没有重复数据),所以L3层大概有90%的数据(1000/110),那么最多有大约10%数据与L1和L2层数据重复(L2+L3占10%,L2和L3的数据全部被L3层覆盖),那么空间放大大约是:存储的数据量/实际存在的数据量 1/0.9=1.1
b. 最坏情况下:如果L3层并没有写满,可能只比L1+L2层多一点的情况下,比如只有220个SST file,这时L3层大概就只有50%的数据,那么最多就可以有50%的重复数据,那么空间放大大约是: 1/0.5=2
- 写放大:每次做Compaction都将Ln层数据写入到Ln-1中,如果L1 ,L2 两层fanout是10,那么L1层写满后与L2层做排序合并,重写生成新的L2层,那么写放大最坏情况下等于fanout
当然在不同的数据库实现中,不一定是将Ln层所有的数据都合并写入到Ln-1中,像RocksDB中就是选择有重合的数据进行合并。
-
Tiered
Tiered算法与Classic Leveled的区别在于每一层的SST file之间Key有重合的,每层有多个"Sorted Run",每次做Compaction都是同层先做合并生成一个新的SST file写入到下一层中,这里与Leveled最重要区别是写入到下一层后不再需要排序合并、重写,因为Tiered每层存在多个"Sorted Run",那么写放大最坏情况下为1。
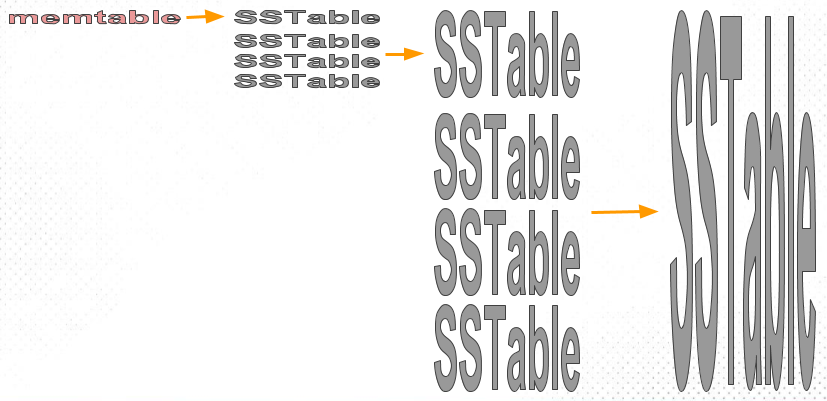
但是相比于Leveled,会有读放大和空间放大会比较严重,例如下面这张图:当查询key=5时由于存在两个"Stored Run",那么key无法直接定位到是在哪个SST file中,<2,8>,<1,7>可能都有符合的。
但是Leveled只有一个"Stored Run"(不一定是只有一个SST file),做Compaction时会和本层的SST file也做一次合并,那么查询时就只需要扫描1个SST file,但也能看出写放大会比较严重
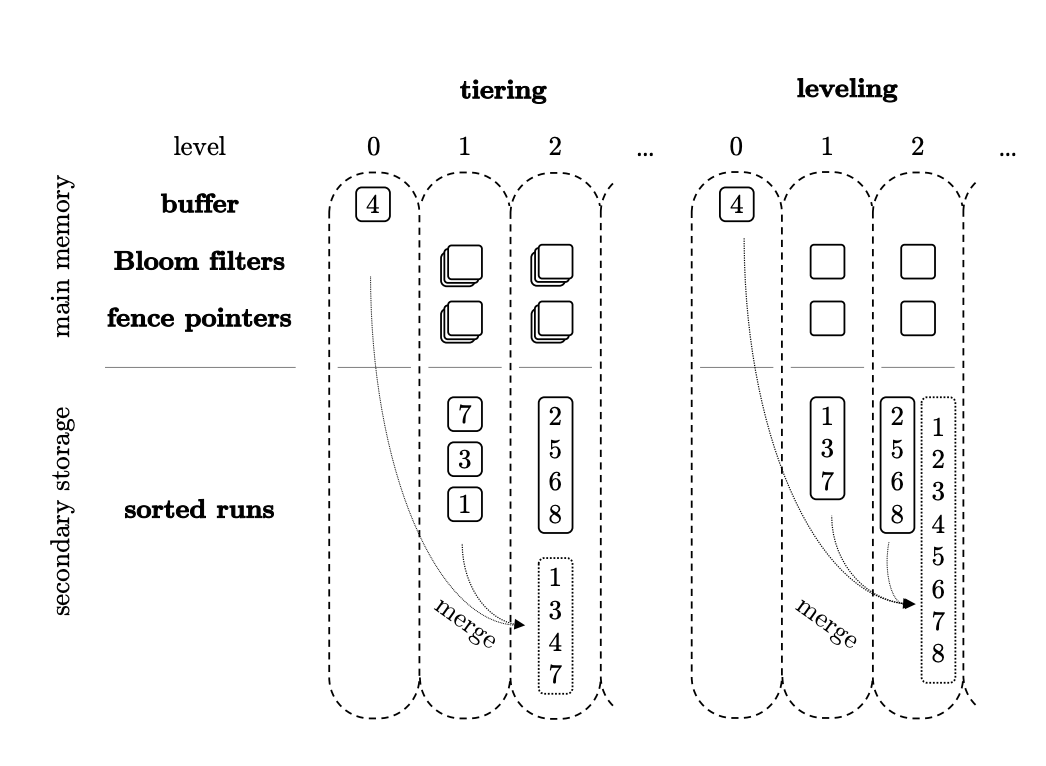
综合两种算法优缺点,RocksDB与OceanBase采用了混合方式,L0层使用Tiered,L1-LN使用Leveled
,RocksDB中将这种混合方式称为Leveled Compaction
新硬件下的LSM-Tree分析
前面我们提到了LSM-Tree将随机写转化为顺序写,提升了整体写入性能,并且LSM-Tree相相比于B-Tree写放大会更小。可以理解为这些优化都是围绕我们上面说的写放大、读放大、空间放大。
对于HDD写放大可能感觉不深,但是在SSD作为主流的时代,严重的写放大对于SSD寿命和性能都有较大影响。
因为SSD由于内部不能做修改,所有的数据都是写到新的Page上,等到Block上Free
的Page不够时,会将整个Block上有效Page做搬迁,并将原有Block进行擦除,频繁的擦除操作对SSD寿命是有影响的。所以在写放大严重情况下,会有很多无效的数据占用了Block,导致频繁的做GC。
当然LSM-Tree在SSD内部也不是完全没有写放大,数据进行分层存储,但每一层数据生命周期是不一样,Ln层的数据可能改变的几率会更小,但是写入数据在同一个Page上的多个Block可能混合着长短生命周期的数据,做清理时长生命周期的数据也会被搬迁,但其实这部分数据很少改变,如果能将数据按生命周期分开存储到SSD内部,则会减少SSD内部写放大,各家SSD厂商都有支持Multi-stream的SSD。
不管是LSM-Tree中各种Compaction算法的优化,还是支持Multi-streamSSD都是去减少写放大,但如果你现在使用的是MySQL InnoDB存储引擎,让你换成MyRocks,或者是已使用LSM-Tree存储引擎但希望结合Multi-stream做更深一步优化,这两种成本都是非常高,前者需要涉及到数据迁移、管理工具改造、验证测试等一些列工作,后者更是需要做存储引擎内核的改造。
我们希望通过一种更透明方法去减少写放大,不管是B-Tree或者是LSM-Tree都有写放大,如果将写入的数据在SSD盘内压缩后再写入到闪存颗粒上,那SSD内部的数据将会减少,从而降低了写放大,提高了SSD的寿命。并且所有的操作都是在SSD盘内对于用户完全透明,不需要做任何改造,目前厂商有ScaleFlux的CSD 可计算存储系列。
总结
这里介绍了下LSM-Tree的空间放大、读放大、写放大,围绕这三点围绕在Compaction算法上,做了哪些优化,下一篇会逐步到数据库层面,介绍相关参数和一些测试数据。
