




点击上方“IT那活儿”公众号,关注后了解更多内容,不管IT什么活儿,干就完了!!!
2. 源代码编译
<dependency>
<groupId>org.springframework.kafka</groupId>
<artifactId>spring-kafka</artifactId>
<version>2.6.7</version>
</dependency>
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>fastjson</artifactId>
<version>1.2.47</version>
</dependency>
kafka:
producer:
bootstrap-servers: 192.168.XXX.104:9098,192.168.XXX.102:9098
kafka:
agent-info:
topic: agent-info #写入topic 名称
disabled: true #是否禁用 true 禁用 false 启用
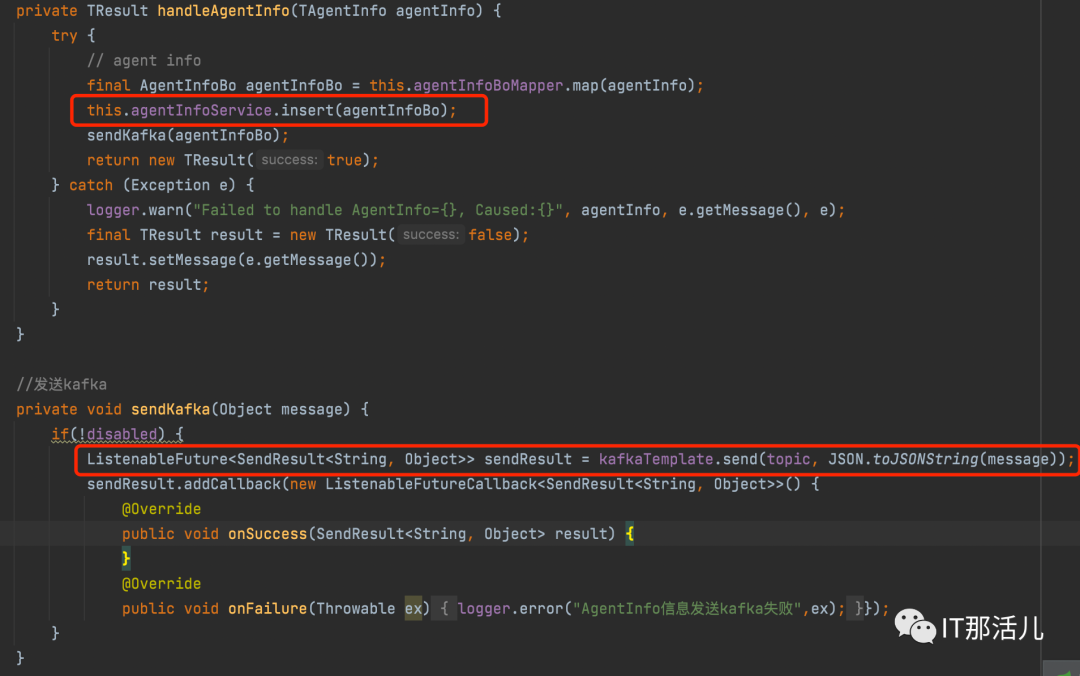
kafka-console-consumer.sh --bootstrap-server 192.168.XXX.102:9098 --topic agent-info
{"agentId":"192.168.XXX.101-
8081","agentName":"","agentVersion":"2.3.3","applicationName":"snc-datacollection","container":false,"endStatus":0,"endTimeStam
p":0,"hostName":"bigdata-
02","ip":"192.168.XXX.101","jvmInfo":
{"gcTypeName":"PARALLEL","jvmVersion":"1.8.0_201","version":0},"pid":979789,"ports":"","serverMetaData":
{"serverInfo":"Apache Tomcat/9.0.30","serviceInfos":
[{"serviceLibs":[],"serviceName":"Tomcat/localhost/snc-datacollection"}],"vmArgs":["-Xms1g","-Xmx1g","-
XX:+HeapDumpOnOutOfMemoryError","-javaagent:/home/pinpoint/pinpoint-agent-2.3.3/pinpoint-
bootstrap-2.3.3.jar","-Dpinpoint.agentId=192.168.XXX.101-
8081","-Dpinpoint.applicationName=snc-datacollection","-Dpinpoint.licence=8310000"]},"serviceTypeCode":1000,"startTi
me":1672902590224,"vmVersion":"1.8.0_201"}
本文作者:长研架构小组(上海新炬中北团队)
本文来源:“IT那活儿”公众号

文章转载自IT那活儿,如果涉嫌侵权,请发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
