





一、告警数据处理

未恢复的历史告警如果较多,zabbix_server会不断地去检索未恢复的告警并更新告警持续时间,造成zabbix_server压力较大。此时需要禁用掉用户不关注/不必要的告警,然后删除历史告警信息。
events
problem
snc_alarms
snc_alarms_trigger_value
snc_alarms_history
snc_alarms_handle_record
snc_alarms_history_handle_record
snc_alarms_history_trigger_value
snc_notice_alerts_detail
snc_notice_alerts
AMP_ALARM_CENTER
AMP_ALARM_CENTER_TOPIC
AMP_EVENT_ALARM
AMP_EVENT_ALARM
AMP_STRATEGY_INFO
alarm_notifies
alarm_values
alarm_values_transformed
alarm_values_transformed_err
amp_alarm_info
amp_alarm_notice
amp_zabbix
snc_alarm_notice
notification_default
二、数据库参数优化及大表清理
2.1 数据库参数调优
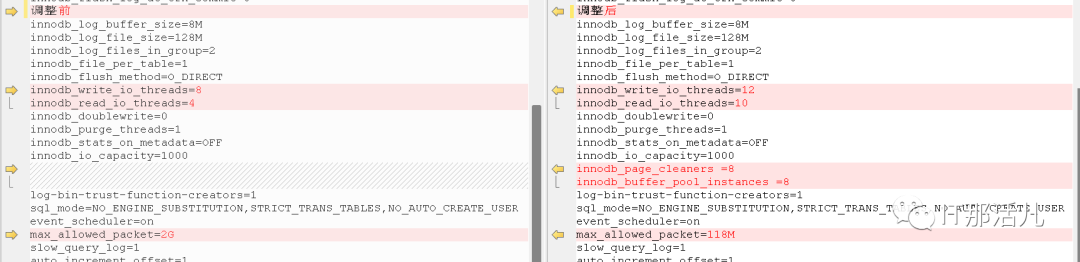
参数说明:
innodb_write_io_threads和innodb_read_io_threads一般配置为cpu核数的一半,再根据读写的实际情况稍微调整,写的事务大于读的事务,就将innodb_write_io_threadss参数稍微大于innodb_read_io_threads参数,反之则调换。 innodb_page_cleaners 为page cleaner线程从buffer pool中刷脏页的线程数量,innodb_buffer_pool_instances可以开启多个内存缓冲池,把需要缓冲的数据hash到不同的缓冲池中,这样可以并行的内存读写,两个参数配合一起使用。 allowed_package 传输包的上限值,可理解成一个事务传送的包最大值,太大会导致整个事务卡住。
表数据量可能会很大,清表时可能会导致事务拥塞,可能需要等很长时间(所属地清这张表花了45分钟左右)。
select
table_schema as '数据库',
table_name as '表名',
table_rows as '记录数',
truncate(data_length/1024/1024, 2) as '数据容量(MB)',
truncate(index_length/1024/1024, 2) as '索引容量(MB)'
from information_schema.tables
where table_schema='amp' and table_rows>=5
order by table_rows desc, index_length desc ;
三、proxy状态排查和参数优化
3.1 查看proxy进程的执行时间
ps -ef|grep zabbix_procy
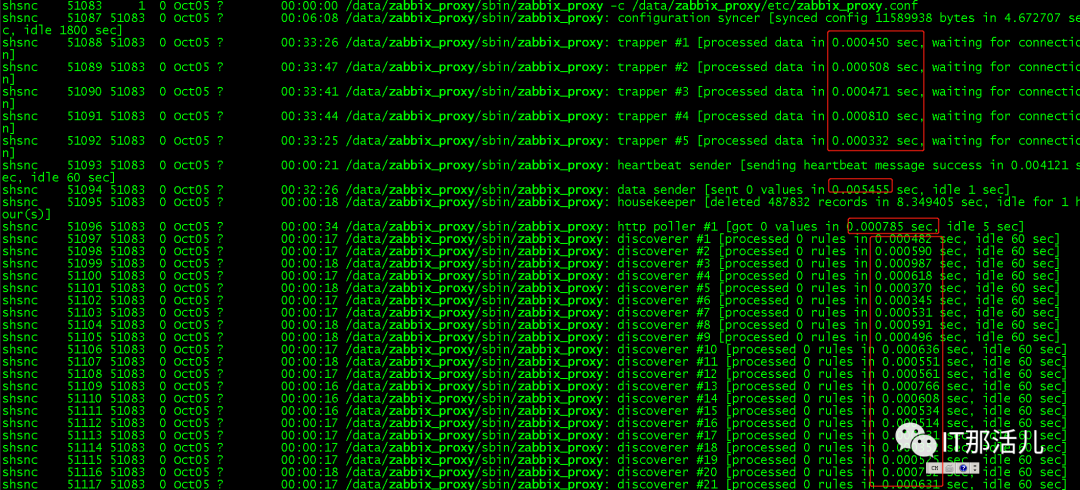
ConfigFrequency为proxy向zabbix_server获取监控配置(监控项,主机清单等)的配置项,过于频繁向zabbix_server获取数据会导致zabbix_server压力过大。小董项目原来的ConfigFrequency=120,后来调整成ConfigFrequency=1800.
四、zabbix_server进程观察及参数调优
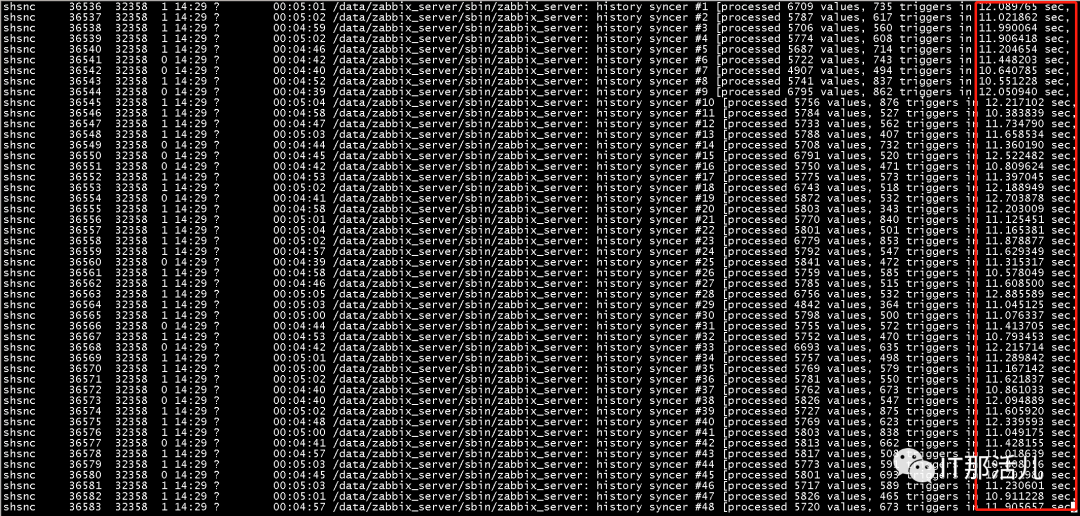
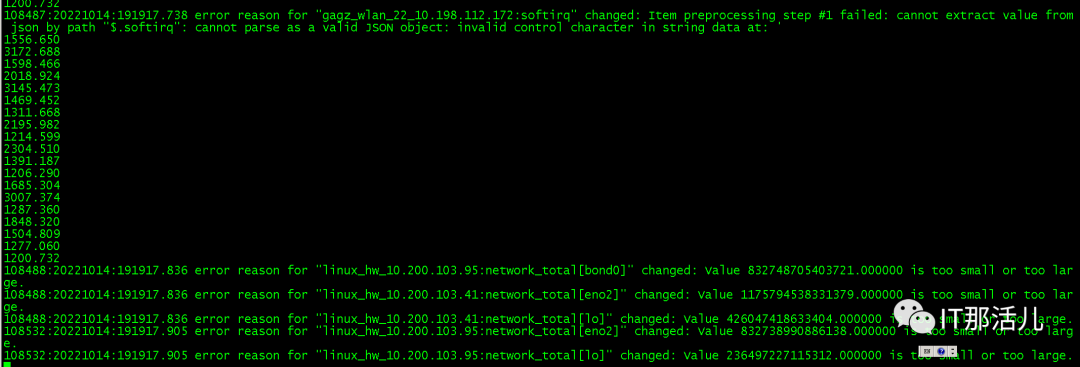
4.1 重点关注preproces进程中待处理数据的积压情况和history syncer进程的时间消耗情况
watch -tn 0.2 'ps -fC zabbix_server | grep preprocessing'


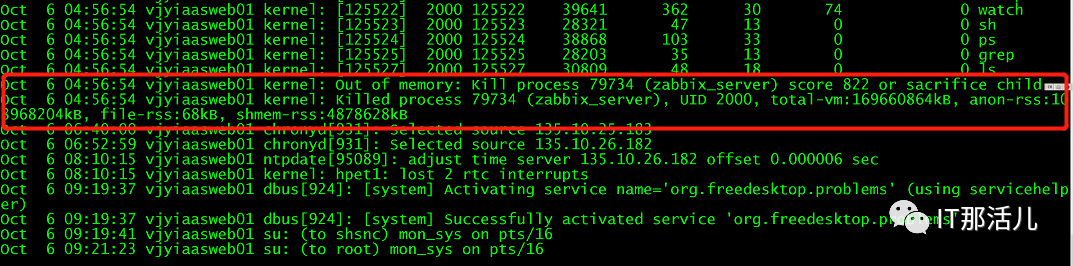
watch -tn 0.2 'ps -fC zabbix_server | grep history'
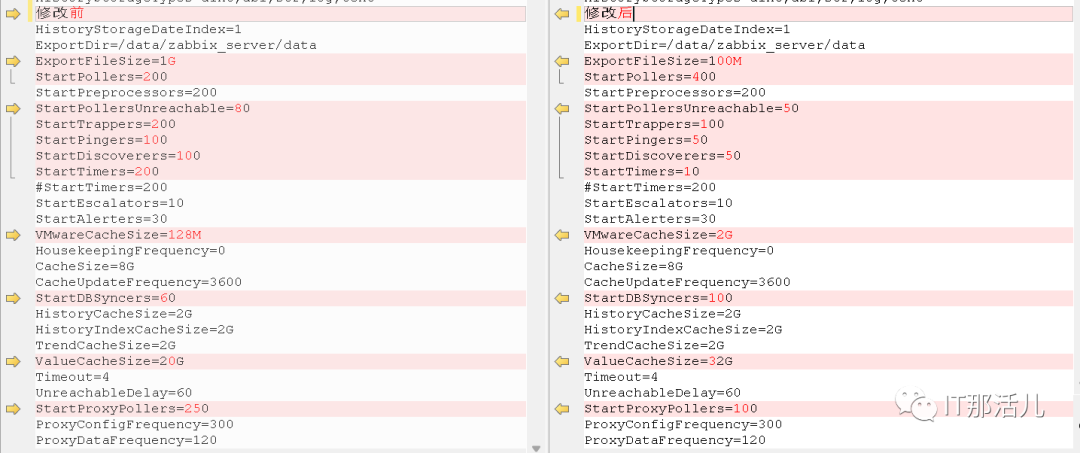
4.4 zabbix_server.cnf参数说明
HistoryStorageDateIndex=1 将历史数据保存到不同的elasticsearch索引; ExportFileSize=100M 定义每个导出文件的最大大小; StartPollers=400 启动多少个进程收集来自agent的数据,默认轮询方式,处理完一个agent的数据换下一个进程; StartPreprocessors=200 预启动多少个进程用于处理zabbix agent数据; StartPollersUnreachable=50 对不可达主机的进行轮询探测的进程的初始实例启动数量; StartTrappers=100 预启动的Trappers(告警触发器)进程数据; StartPingers=50 ICMP ping进程的初始实例数量; StartDiscoverers=50 自动发现主机的进程数量; StartTimers=10 计时器实例数量,计时器用于记录问题的发生时间和步骤同步等; StartEscalators=10 escalators进程的初始实例数量,用于处理动作中的自动步骤的进程的数量; StartAlerters=30 告警实例预启动数量; VMwareCacheSize=2G vmware数据缓存大小,会占用zabbix server服务器内存; HousekeepingFrequency=0 多少小时清理一次代理端数据库的历史数据; CacheSize=8G 缓存大小; CacheUpdateFrequency=3600 Zabbix更新缓存数据的频率,单位为秒,范围是1-3600; StartDBSyncers=100 zabbix和数据库同步数据的进程数量; HistoryCacheSize=2G 历史数据的缓存大小,128K-2G; HistoryIndexCacheSize=2G 历史数据索引缓存的大小,128K-2G; TrendCacheSize=2G 用于设置划分多少系统共享内存用于存储计算出来的趋势数据,此参数值从一定程度上可缓解数据库读压力,范围是128K-2G; ValueCacheSize=32G 历史值缓存的大小,用于缓存历史数据请求的共享内存大小; Timeout=4 数据获取等待超时时间,1-30s,过期不候,哪怕数据来了也是记录超时; UnreachableDelay=60 当主机不可到达了,多久检查一次该主机的可用性,单位为秒,范围是1-3600; StartProxyPollers=100 启用多少子进程与代理端通信,若代理较多可考虑加大此数值,范围是0-250; ProxyConfigFrequency=300 proxy被动模式下,server多少秒同步配置文件至proxy,该参数仅用于被动模式下的代理,范围是1-3600*24*7; ProxyDataFrequency=120 被动模式下,zabbix server间隔多少秒向proxy请求历史数据,1-3600s。
本文作者:IT那活儿(上海新炬中北团队)
本文来源:“IT那活儿”公众号

